







最近需要对大小在0到100万内的很多数组进行排序,每一个数组的长度都不固定,短则几十,长则几千。为了最快完成排序,需要将数组大小和数据范围考虑进去。由于快速排序是常规排序中速度最快的,首选肯定是它。但是数组中数据的范围固定,可以考虑基数排序。为了使排序耗时尽可能短,需要测试这两种排序算法。
快排是面试过程中常考的手写代码,需要背得滚瓜烂熟,代码如下:
void swap(int* a,int *b)
{
int temp=*a;
*a=*b;
*b=temp;
}
void q_sort(int* a,int left,int right)
{
if(left>=right) return;
int i=left,j=right+1;
int pivot=a[left];
while(true)
{
do
{
i++;
}while(i<=right&&a[i]<pivot);
do
{
j--;
}while(j>=left&&a[j]>pivot);
if(i>=j) break;
swap(&a[i],&a[j]);
}
a[left]=a[j];
a[j]=pivot;
q_sort(a,left,j-1);
q_sort(a,j+1,right);
}
void quick_sort(int* a,int n)
{
q_sort(a,0,n-1);
}
const static int radix=100;
int get_part(int n,int i)
{
int p=(int)pow(radix,i);
return (int)(n/p)%radix;
}
void radix_sort(int* a,int n)
{
int* bucket=(int*)malloc(sizeof(int)*n);
int* count=(int*)malloc(sizeof(int)*radix);
for(int i=0;i<3;++i)
{
memset(count,0,sizeof(int)*radix);
for(int j=0;j<n;++j)
{
count[get_part(a[j],i)]++;
}
for(int j=1;j<radix;++j)
{
count[j]+=count[j-1];
}
for(int j=n-1;j>=0;--j)
{
int k=get_part(a[j],i);
bucket[count[k]-1]=a[j];
count[k]--;
}
memcpy(a,bucket,sizeof(int)*n);
}
free(bucket);
free(count);
}
下面详细分析一下上面的基数排序代码。首先定义常量radix用来表示选择的基数,上面的代码一开始选择的基数为100。很多代码在使用基数排序的时候总是默认基数为10,但是这样往往会提高复杂度,后面会详细分析10为基的坏处。之后定义了一个get_part函数,用来获得数据的不同部分。最后是具体的基数排序函数。通过函数体可以很清楚的看出基数排序的复杂度,上面代码给出的复杂度为O(3*(3n+r))。其中外面的3表示范围在100万以内的数通过基数100分解最多只需要分解三次;里面的3n+r表示每次循环的复杂度。For循环内部有三个小的for循环,复杂度分别为n、r和n。此外还有一个memset调用,复杂度也是n,因而每次循环总的复杂度是3n+r。
由上面的分析,我们可以获得基数排序在数据任意大小时的复杂度为: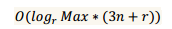
其中,r为基数,n为数组长度,Max为数组最大值。由此我们可以看出,影响基数排序的因素有三个:数组长度,基数大小和数组最大值。优化基数排序的方法也就是从这三方面入手。
在介绍优化之前,我们先对比原始的基数排序和快速排序的性能,测试结果如表一:

测试结果很让人吃惊,基数排序完全比不上快速排序,性能差距而且不小,这很奇怪。如果看代码,基数排序的复杂度确实很低,但是性能却比较差劲。不过好的一点是,基数排序的性能确实满足线性增长规律。
优化一:避免内存分配
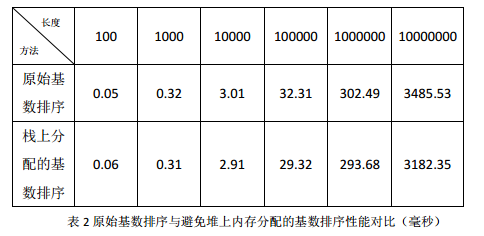
原始基数排序中桶变量count使用malloc分配空间,我们首先将该动态内存分配改为栈上固定内存分配,基数排序的前后性能对比如表二。可以看出,通过改为固定内存分配,基数排序的性能有小幅提升,但是这还不足以与快速排序相匹配。我们还需要考虑别的优化技巧。
优化二:修改基数
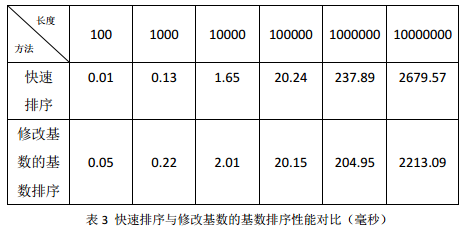
通过基数排序的复杂度可以看出,影响复杂度的很大一个参数是基数的选择。很多人在使用基数排序时都会默认基数为10,但是这样会显著增大算法复杂度的常量,因而在数组长度较大时,选用较大的基数可能会使性能更好。我们将算法的基数改为1000,性能对比图如表三。可以看出,通过修改基数,基数排序的性能有很大提升,当数组长度大于10000时,基数排序的性能已经超过快速排序。
但是这还不足以说明基数排序的优势。按复杂度推算,快速排序的复杂度为O(n*logn),基数排序复杂度在基为1000时复杂度为O(6n+2r),因而当元素个数在500左右时,两者的性能就应该达到一样,这说明算法还有优化余地。
优化三:避免复杂的数学运算
基数排序中有一个频繁的操作是获取整数的不同部分,该操作通过一个get_part函数获得,函数代码如下:
int get_part(int n,int i)
{
int p=(int)pow(radix,i);
return (int)(n*p)%radix;
}
上述函数有一个复杂的pow系统调用,这可能会影响速度。但其实该操作就是计算基数的次方。在基数固定的前提下,我们可以将次方计算提前计算出来,每次通过查表来获得基数的次方。为此,我们定义一个常量数组p用来保存基数的次方:
static int p[]={1,radix,radix*radix,radix*radix*radix,radix*radix*radix*radix};当基数为1000时,上述数组可以应对最大为10^12的整数。然后get_part函数就变为:
int get_part(int n,int i)
{
return (n/p[i])%radix;
}
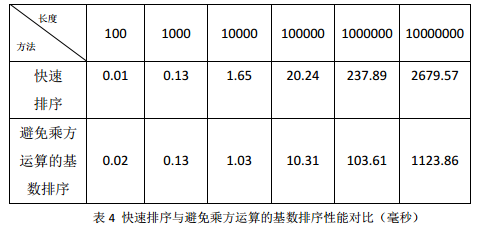
在此测试两种排序,性能对比如表四。这次可以看出,当元素为1000左右时,基数排序性能开始占优;当数组很长时,基数排序有很明显的性能提升,已经远远超过了快速排序。
优化四:除法变乘法
在get_part函数中有一个除法取整的操作,一般情况下除法要比乘法更耗时,一个优化技巧是将除法变成乘法。在此我们可以定义一个常量数组,用来保存基数次方的倒数,这样就可以将除法转变成乘法:
static double rp[]={1,1.0/p[1],1.0/p[2],1.0/p[3],1.0/p[4]};然后get_part函数就变为:
int get_part(int n,int i)
{
return (int)(n*rp[i])%radix;
}
再次测试基数排序前后的性能有表五。可以看出,避免除法操作又可以使性能获得较大提升。当数组长度在400左右时,基数排序性能开始占优。
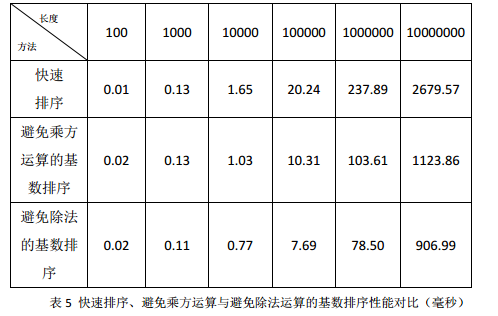
优化五:内联函数
可以看出get_part函数在基数排序中多次调用,同时其构造又很简单,可以考虑将其作为内联函数。修改一个函数为内联函数的方式很简单,只需要在声明函数时加inline关键词即可。将get_part函数修改为内联函数后,性能又有些许提升,如表六。当数组长度在300左右时,基数排序性能开始占优。
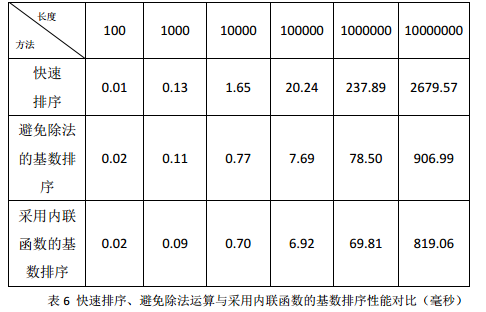
优化六:采用2的幂作为基数
在选择基数时我们总会习惯性的以10的幂作为基数,这与我们平时多用10进制运算相符合。但是,计算机是以二进制存储数据的,所以当采用10的幂作为基数时就会出现很多问题,最明显的就是上面出现的乘法除法问题。虽然我们对get_part函数做了很多优化,但是还有一个取余操作尚未优化。昨天,经俊哥指点,我们完全可以采用2的幂作为基数,这样就可以完全避免复杂的乘除法运算。
我们将基数改为1024,此时我们需要修改常量数组p为:
static int p[]={0,10,20,30};然后get_part函数变为:
inline int get_part(int n,int i)
{
return n>>p[i]&(radix-1);
}
可以看出,修改基数为1024之后,除法操作就变为了右移操作,取模操作就变成了与操作。直观上,性能会有很大提升;测试结果也是如此,如表七。当数组长度在200左右时,基数排序性能开始占优。
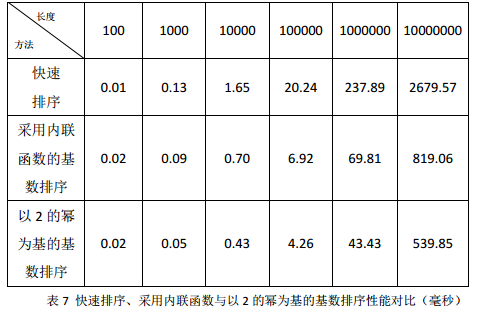
下面把调优之后的完整基数排序代码列出:
const static int radix=1024;
static int p[]={0,10,20,30};
inline int get_part(int n,int i)
{
return n>>p[i]&(radix-1);
}
void radix_sort(int* a,int n)
{
int* bucket=(int*)malloc(sizeof(int)*n);
int count[radix];
for(int i=0;i<2;++i)
{
memset(count,0,sizeof(int)*radix);
for(int j=0;j<n;++j)
{
count[get_part(a[j],i)]++;
}
for(int j=1;j<radix;++j)
{
count[j]+=count[j-1];
}
for(int j=n-1;j>=0;--j)
{
int k=get_part(a[j],i);
bucket[count[k]-1]=a[j];
count[k]--;
}
memcpy(a,bucket,sizeof(int)*n);
}
free(bucket);
}再次运行快速排序和上述代码,获得一个性能对比图:

总结
通过上面的分析我们可以看出,基数排序确实符合它线性复杂度的优势。如果我们知晓整数数组元素的范围,基数排序确实是一个很好的选择。但是要获得好的性能并不是特别容易,需要很多优化技巧。最好的优化方法就是选择2的幂作为基数。在具体应用时,我们要根据实际的数据范围去合理的选择基数,在确定基数之后再去考虑需要循环的次数。在上面的对比中,数据范围在100w以内,因而循环只有两次,所以快速排序和基数排序的性能差异接近5倍;如果在10亿以内,则需要三次循环,性能差异可能就会降为3倍左右。其实,10亿以内的数几乎快覆盖了int型整数的范围;如果基数选择为2048,则三次循环就完全覆盖了整个int型整数范围。所以,如果要排序的数据范围很大,但是数据量又不足以使用计数排序时,可以考虑采用基数为2048的基数排序。















 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









