







DeepSig RadioML 2018.01A 数据集:下载地址 19G 下载速度很快10+m/s
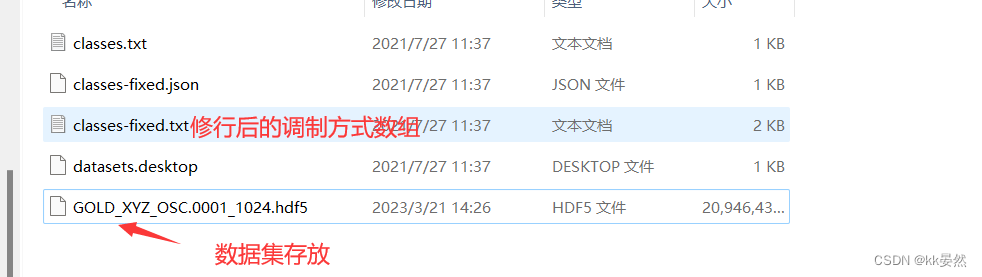
下载后的目录:除了图中标注,其他无用
 数据集包含24种调制样式:‘OOK’, ‘4ASK’, ‘8ASK’, ‘BPSK’, ‘QPSK’, ‘8PSK’, ‘16PSK’, ‘32PSK’, ‘16APSK’, ‘32APSK’, ‘64APSK’, ‘128APSK’, ‘16QAM’, ‘32QAM’, ‘64QAM’, ‘128QAM’, ‘256QAM’, ‘AM-SSB-WC’, ‘AM-SSB-SC’, ‘AM-DSB-WC’, ‘AM-DSB-SC’,‘FM’, ‘GMSK’, ‘OQPSK’
数据集包含24种调制样式:‘OOK’, ‘4ASK’, ‘8ASK’, ‘BPSK’, ‘QPSK’, ‘8PSK’, ‘16PSK’, ‘32PSK’, ‘16APSK’, ‘32APSK’, ‘64APSK’, ‘128APSK’, ‘16QAM’, ‘32QAM’, ‘64QAM’, ‘128QAM’, ‘256QAM’, ‘AM-SSB-WC’, ‘AM-SSB-SC’, ‘AM-DSB-WC’, ‘AM-DSB-SC’,‘FM’, ‘GMSK’, ‘OQPSK’
信噪比范围:SNR = 【-20:32:2】 -20到30间隔2,共26种信噪比,具体【-20,-18…28,30】
每个调制,每个信噪比有4096条数据,共计2555904(24 * 26 4096*)条数据,IQ数据,数据格式为(1024, 2)
在数据集存放文件hdf5文件,存在3个参数X(IQ信号),Y(调制方式),Z(信噪比)
X——>[24264096,1024,2]
Y——>[24264096,24] 采用onehot,所以不是[24264096,1] ,顺序为上述顺序(class-fixed.txt修正后的 )
Z——>[24264096,1]
我要切分 全部调制方式的信噪比为10db的全部,则代码为
# -*- coding: utf-8 -*-
import h5py
h5file = h5py.File('D:/RF_data/archive/GOLD_XYZ_OSC.0001_1024.hdf5', 'r+')
savefile=h5py.File('mini_dataset.hdf5', 'w')
import numpy as np
X = h5file['X'][15 * 4096:16 * 4096] # 15是因为10db在 26个信噪比的第15个
Y = h5file['Y'][15 * 4096:16 * 4096]
Z = h5file['Z'][15 * 4096:16 * 4096]
for i in range(1, 24, 1):
X = np.vstack((X, h5file['X'][4096 * 26 * i + 15 * 4096:4096 * 26 * i + 16 * 4096]))
Y = np.vstack((Y, h5file['Y'][4096 * 26 * i + 15 * 4096:4096 * 26 * i + 16 * 4096]))
Z = np.vstack((Z, h5file['Z'][4096 * 26 * i + 15 * 4096:4096 * 26 * i + 16 * 4096]))
savefile['X']=X
savefile['Y']=Y
savefile['Z']=Z
print(savefile['X'].shape)
切分成功,切成的数据维度为98304(24(全部调制)*4096(一类数据))
切分方法二:参考教程
原博文代码有点问题,修改了一下:
# -*- coding: utf-8 -*-
import h5py
h5file = h5py.File('D:/RF_data/archive/GOLD_XYZ_OSC.0001_1024.hdf5', 'r+')
Y = h5file['Y'][:]
Z = h5file['Z'][:]
import numpy as np
import scipy.io as io
Y_array = np.array(Y) # mod
Z_array = np.array(Z) # SNR
mod = ['OOK', '4ASK', '8ASK', 'BPSK', 'QPSK', '8PSK', '16PSK', '32PSK', '16APSK', '32APSK', '64APSK', '128APSK',
'16QAM', '32QAM', '64QAM', '128QAM', '256QAM', 'AM-SSB-WC', 'AM-SSB-SC', 'AM-DSB-WC', 'AM-DSB-SC', 'FM', 'GMSK',
'OQPSK']
snr = range(-20, 31, 2)
n = 0
for i in range(0, 24, 1):
for j in range(0, 26, 1):
IQ = h5file['X'][n * 4096:(n + 1) * 4096, :, :]
path = mod[i] + "_SNR=" + str(snr[j]) + "dB.mat"
io.savemat(path, {'name': IQ})
n = n + 1
print('ending')
最终得到.mat文件,可以使用为原来的hdf5格式,参考第一个代码
之前检索关于Deepsig 2018数据集资料,都在找采样频率,我自己也找了半天没找到相关资料,突发奇想试了一下newbing,给出了答案
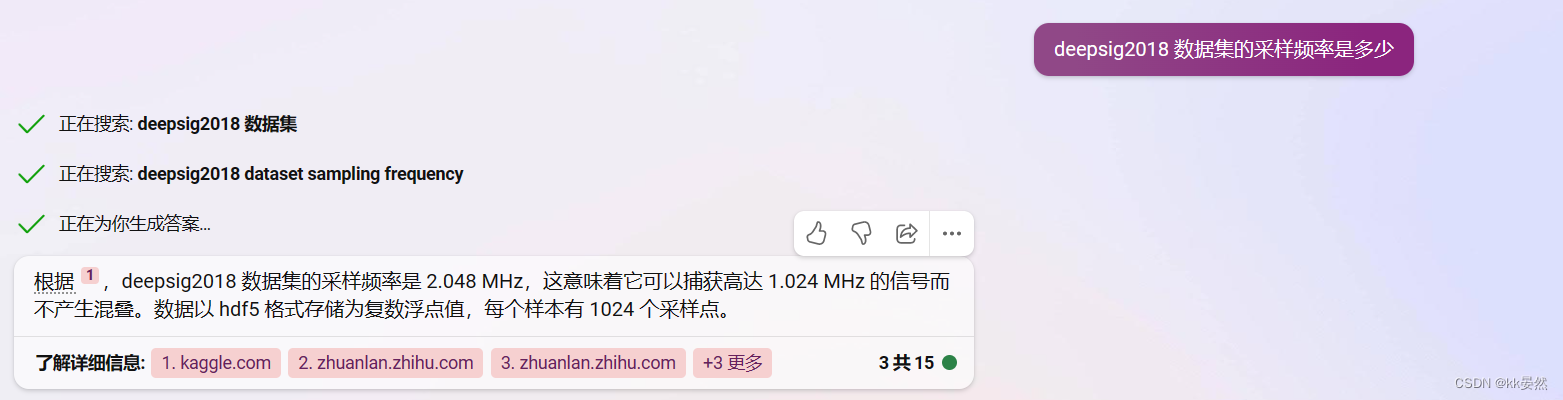
Deepsig 2018数据集的采样频率为2.018Mhz?
再分享一个生成数据集代码(自动调制识别基本都是tensorflow写的,找个pytorch模型挺费劲):
from torch.utils.data import Dataset
import os
import h5py
import numpy as np
import torch
import torch.nn.functional as F
catalog = {
'deep_sig_2018_train': {
'path': 'data/full_train_set.hdf5',
},
'deep_sig_2018_test': {
'path': 'data/full_test_set.hdf5',
},
'deep_sig_micro_train': {
'path': 'data/micro_train_set.hdf5',
},
'deep_sig_micro_test': {
'path': 'data/micro_test_set.hdf5',
}
}
class DeepSig2018(Dataset):
'''
DeepSig2018_Train Pytorch Dataset Class
Dataset contains 4096 frames per modulation-SNR combination
Loads data from DeepSig.ai 2018 dataset
- f['X'] = 2.5M array of 1024 intervals of 2 I/Q datapoints
- f['Y'] = 2.5M array of 24 modulation types one-hot-encoded
- f['Z'] = SNR level in dB --> [['-2dB']]
Assigns the modulation type as the data label
'''
classes = ["OOK", "ASK4", "ASK8", "BPSK", "QPSK", "PSK8", "PSK16",
"PSK32", "APSK16", "APSK32", "APSK64", "APSK128", "QAM16",
"QAM32", "QAM64", "QAM128", "QAM256", "AMSSBWC", "AMSSBSC",
"AMDSBWC", "AMDSBSC", "FM", "GMSK", "OQPS"]
def __init__(self,
transform=None,
download=True,
split="train",
progress=True,
min_snr=-float('inf'),
max_snr=float('inf'),
one_hot=True
):
super().__init__()
self.transform = transform
if split == "train":
f_path = catalog['deep_sig_2018_train']['path']
elif split == "test":
f_path = catalog['deep_sig_2018_test']['path']
elif split == "micro_train":
f_path = catalog['deep_sig_micro_train']['path']
elif split == "micro_test":
f_path = catalog['deep_sig_micro_test']['path']
else:
assert False, ("Split argument is invalid. "
"Please choose from 'train', "
"'test', 'micro_train', or 'micro_test")
if not os.path.isfile(f_path):
if download:
print("Selected dataset not found.")
self.download(self, progress=progress)
else:
assert False, "No dataset has been downloaded. Please flag set 'download=True' to download."
# LOAD DISK DATA TO VARIABLES
raw_data = h5py.File(f_path, "r")
self.X = np.array(raw_data['X'])
self.mod_type = np.array(raw_data['Y'])
self.SNR = np.array(raw_data['Z'])
self.one_hot = one_hot
self.min_snr = min_snr
self.max_snr = max_snr
self.index = np.arange(len(self.X))
self.filter_SNR(self, self.min_snr, self.max_snr)
@staticmethod
def filter_SNR(self, min_snr, max_snr):
'''
Filters the object to only contain data
with SNR levels between max_snr and min_snr.
Args:
- max_snr(float): Maximum level of SNR to retain
- min_snr(float): Minimum level of SNR to retain
'''
self.min_snr = min_snr
self.max_snr = max_snr
self.index, = np.where((self.SNR >= self.min_snr) & (self.SNR <= self.max_snr))
@staticmethod
def export_data(set_data, file_name):
out_path = f'./data/{file_name}.hdf5'
out_data = h5py.File(out_path, 'w')
out_data['X'] = set_data[0]
out_data['Y'] = set_data[1]
out_data['Z'] = set_data[2]
out_data.close()
return f'{file_name} exported to {out_path}'
@staticmethod
def data_split(self, f_name='data/GOLD_XYZ_OSC.0001_1024.hdf5'):
print("Unpacking master file.")
raw_data = h5py.File(f_name, "r")
sigs = np.array(raw_data['X'])
print("Signals allocated.")
mod_type = np.array(raw_data['Y'])
print("Labels allocated.")
SNR = np.array(raw_data['Z'])
SNR = SNR.squeeze(1)
print("SNR levels allocated.")
index = np.arange(len(sigs))
print("Splitting data...")
full_train_idx = []
micro_train_idx = []
micro_test_idx = []
full_test_idx = []
for i in range(0, len(sigs), 4096):
mtrain_idx, mtest_idx = index[i:820 + i], index[820 + i:1230 + i] # 820 is ~20% of the dataset
ftrain_idx, ftest_idx = index[i:3276 + i], index[3276 + i:3276 + 820 + i]
micro_train_idx.extend(mtrain_idx)
micro_test_idx.extend(mtest_idx)
full_train_idx.extend(ftrain_idx)
full_test_idx.extend(ftest_idx)
print()
print("Split complete. Assigning data to sets.")
micro_train_set = [sigs[micro_train_idx], mod_type[micro_train_idx], SNR[micro_train_idx]]
micro_test_set = [sigs[micro_test_idx], mod_type[micro_test_idx], SNR[micro_test_idx]]
full_train_set = [sigs[full_train_idx], mod_type[full_train_idx], SNR[full_train_idx]]
full_test_set = [sigs[full_test_idx], mod_type[full_test_idx], SNR[full_test_idx]]
print("Data has been split into 'micro_train_set', 'micro_test_set', 'full_train_set', 'full_test_set'")
print("Saving data sets into hd5f files.")
print(self.export_data(micro_train_set, "micro_train_set"))
print(self.export_data(micro_test_set, "micro_test_set"))
print(self.export_data(full_train_set, "full_train_set"))
print(self.export_data(full_test_set, "full_test_set"))
return [full_train_set, full_test_set, micro_train_set, micro_test_set]
@staticmethod
def download(self, progress=True):
f_path = 'data/GOLD_XYZ_OSC.0001_1024.hdf5'
if not os.path.isfile(f_path):
import kaggle
print("Downloading zip file from Kaggle")
print("WARNING: A Kaggle API key is needed for the download!!! \n"
"If you do not have one, download the file manually and place "
"it's extracted contents in the 'data/' folder.")
kaggle.api.dataset_download_files('pinxau1000/radioml2018', path='./data/', unzip=True, quiet=False)
print("Data has been downloaded. \n Preparing to split data...")
self.data_split(self, f_path)
else:
print("Master data file located. Preparing to split data...")
self.data_split(self, f_path)
def __len__(self):
return len(self.X[self.index])
def __getitem__(self, idx):
tru_idx = self.index[idx]
data = self.X[tru_idx].T
label = self.mod_type[tru_idx]
if not self.one_hot:
label = label.argmax()
if self.transform:
data = self.transform(data)
return torch.tensor(data), torch.tensor(label, dtype=torch.float)
def test():
ds = DeepSig2018(split="train")
x, y = ds[0]
assert y.shape == torch.Size([24]), "Labels to default to one-hot-encoding with 24 classes."
assert y.dtype == torch.float, "Labels should be torch.float datatype."
if __name__ == "__main__":
test()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









