







严格的说,数据库是“按照数据结构来组织,存储和管理数据的仓库”。
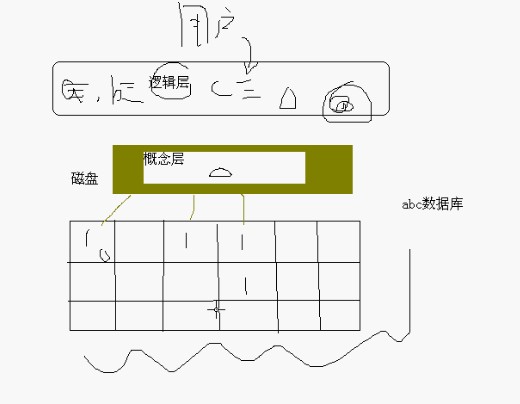
数据库的基本结构
① 物理数据层 放在磁盘的哪些位置的。
② 概念数据层 是存储记录的集合
③ 逻辑数据层 用户看到的表等
数据库的基本特点
① 实现数据共享
② 减少数据的冗余度
③ 实现数据集中控制
④ 数据一致性和可维护性,以确保数据的安全性和可靠性
⑤ 故障恢复
一流公司做标准 二流公司做服务 三流公司做产品 四流公司做项目
数据库的选择
① 成本
② 功能多少
③ 并发性(最终用户多少)
④ 安全性要求
SQL是英文 Structured Query Language 的缩写 意思是 结构化查询语言。
是一种数据库查询和程序设计语言,用于存取数据以及查询,更新,和管理关系数据库系统。
SQL语言包含四个部分:
① 数据定义语言DDL create drop alter
② 数据操作语言DML insert update delete
③ 数据查询语言DQL select
④ 数据控制语言DCL grant revoke commit rollback
两种开发工具:
① 企业管理器
图形界面方式操作工具
给我们提供了一个很方便的工具,但是当一个表的记录非常大的时候,对表的操作就显得不方便了
② 查询分析器
用命令行(sql语句)操作工具
在安装SQL2000的时候,如果遇到已经有一个实例被挂起状态
进入到注册表(regedit),hkey_local_machinesystemcurrentControlsetControlsession manager
把一个键值pending 删除就可以了。
- - 代表注释Use 数据库名 使用数据库
表名是不区分大小写的
删除表
删除表的结构和数据 DROP TABLE 表名
删除表的数据 delete from 表名
表名 / 列名
必须以字母开头或者下划线或者汉字
长度不能超过128字符
不要使用sql server的保留字
只能使用如下字符A~Z , a~z, 0~9,$,#, _,等
Unicode编码
用两个字节表示一个字符(可以是英文字母,可以使汉字)
例如一个字母是用两个字符表示,一个汉字也是两个字符表示,对汉字支持比较好
非unicode编码 用一个字节表示一个字母,用两个字节表示一个汉字。
Big5码 用来支持繁体汉字的
Gb2312国标码 主要是用来针对中国的汉字的
Gbk 可以用来支持更多的汉字
Utf-8
字符型
Char 定长 最大8000个字符(非unicode编码)
Char(10) ‘小瀚’ 前四个字符存放‘小瀚’ 后面6个空格补全,数据库不会自动回收没有用的空间。
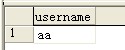
例如下面一个案例 定义char(100)添加 values(‘aa’)
执行效果如下:看见后面的空格了吗

Varchar 变长 最大8000个字符(非unicode编码)
Varchar(10)‘小瀚’ sql server 分配四个字符,这样会节省空间,系统会自动回收没有用的空间。
例如下面一个案例 定义varchar(100)添加 values(‘aa’)
执行效果如下:看见后面短了吗
为什么还需要char呢?
在我们确定一个字段是定长的话我们应当用char,因为这样进行查询语句的时候速度会比varchar快很多,效率高出很多。因为char是定长进行查询字段的时候会按长度一起比对,而varchar会一个一个字符的比对。
Ntext 可变长度的unicode数据 最大长度为2的30次方-1个字符
Text 可变长度非unicode数据 最大长度为2的31次方-1个字符
Text是字节格式存储英文的,也可以存中文但有时候会显示乱码
Ntext是多字节格式存储unicode,也就是存储各种文字用的。
Nchar 定长 最大4000个字符(unicode编码)
Nchar(10) ‘小瀚’ 前面四个放字符‘小瀚’ 后面用6个空格补全
Nvarchar 变长 最大4000字符(unicode编码)
Nvarchar(10) ‘小瀚’ sql server分配四个字符,同上,节省空间。
特别说明:
一般带有汉字的段用nvarchar,全英文或符号的用varchar,因为nvarchar为unicode字符集,该类型的字段无论是单个字母还是单个汉字都占两个字节,而varchar,字母占一个字节,汉字占两个字节,nvarchar处理汉字或其他unicode字符集的速度要比varchar字段快。
数字型
Bit 范围 0~1

Float 可以存放小数
Float(n) n用来指定后面小数点后的位数
Numeric 可以存放小数
Numeric(m,n)m小数点左右位数之和,n小数点右面位数
日期类型
Datetime 表示日期
Timestamp 时间戳
Getdate() 获取当前时间
存放图片
Image 很少用 一般用路径保存图片
存放视频
Binary 很少用 一般sql server保存路径
Primary key 主键,主键不允许为空,主键的值如果没有相同的则可以修改主键值
Foreign key 外键 例如在emp表中添加deptno int foreign key references dept(deptno)
外键只能指向主键,外键和主键数据类型要一致
修改多个字段
Update 表名 set 字段名=‘’,字段名=‘’,where 条件
判断是空 用 is null
判断不是空 用 is not null
Select sal,job from emp where ename=’smith’
小写的simth 大写的SIMTH都可以
取消重复行
Select distinct 字段 from 表名 where 条件
判断是否是空值
Select ename,sal*13+isnull(comm.,0)*13 from emp
Isnull(comm.,0) 如果是空就返回0,不是空就返回comm
分页查询
显示第一个到第四个职员
Select top 4 * from emp order by hiredate
Top 4 前四个
Top n n表示 要取出几条记录
Select top 6 * from emp where empno not in (select top 4 empno from emp order by hiredate ) order by hiredate
分组查询
① 分组函数只能出现在选择列表,having,order by子句中
② 如果在select语句中同时包含有group by ,having,order by那么他们的顺序是group
By,having,order by
③ 在选择列中如果有列,表达式,和分组函数,那么这些列和表达式必须有一个出现在group by 子句中,否则会出错。
如:
select deptno ,avg(sal),max(sal) from emp group by deptno having avg(sal)<2000
这里deptno就一定要出现在group by中
自连接
自连接是在同一张表上的连接查询
例如:显示每个员工名字和他的上级的名字
select e1.ename ,e2.ename from emp e1,emp e2 where e1.mgr=e2.empno
左外连接
指左边的表的记录全部显示,如果没有匹配的记录就用null来补充
Select w.ename , b.ename from emp w left join emp b on w.mgr=b.empno
右外连接
指右边的表的记录全部显示,如果没有匹配的记录就用null来补充


子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
Identity(1,1) 表示该字段自增长从1开始增长,每次加1 ,一般给主键设置该属性
疯狂的复制(用查询结果新建表)
Insert into test (testname,testpass) select testname,testpass from test;
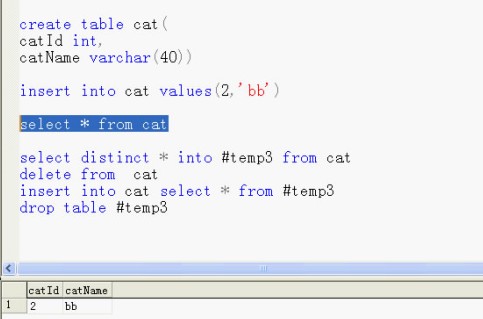
如何删除一张表中的重复记录
约束
not null 非空
unique 该值不能重复,但是可以为null,但是只能有个一个null
primary key 主键,不能有重复,不能有空值,只能有一个主键
可以有多个复合主键
primary key (testid,testname) 单独定义,单独写一行
foreign key 主要定义主表和从表之间的关系
check 用于强制行数据必须满足的条件check(sal>300)
default misdate datetime default getdate() 自动得到日期
表的修改

分离和附加(也属于备份的一种)

备份和恢复
备份
backup database 数据库名 to disk=’d:/sp.bak’
删除数据库
drop database 数据库名
恢复数据库
restore database 数据库名 from disk=’备份的路径.bak’
crud
crud是指在做计算机处理时的增加(create),查询(retrieve),更新(update),删除(delete),
jdbc
jdbc(java data base connectivity,java数据库连接)
jdbc—odbc
①配置数据源
控制面板管理工具数据源用户DNS添加sql server服务器填写local或者写一个点。
数据源的名称和你要去操作的数据库的名称要一致
② 在程序中去连接数据源


增删改和上面的操作一样
下面是查询的
package com;
import java.sql.*;
public class Test2 {
public static void main(String[] args) {
try {
//加载驱动
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
//得到连接
Connection ct=DriverManager.getConnection("jdbc:odbc:animal","sa","as");
//创建statement
Statement sm=ct.createStatement();
//resultset是一个结果集,表示行的结果集
ResultSet rs=sm.executeQuery("select * from master");
//rs指向结果集第一行的前一行,也就是表的字段名
while(rs.next()){
String name=rs.getString(1);
int age=rs.getInt(2);
float weight=rs.getFloat(3);
String hobby=rs.getString(4);
System.out.println(name+" "+age+" "+weight+" "+hobby);
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
finally{
try {
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}
}

sql的一个注入漏洞
例如: select * from emp where empno=’123’ and ename=’dd’
select * from emp where empno=’任意’ and ename=’ 任意‘ or 1=’1’
这样也同样可以查到信息
下面是一个案例:
代码如下:
package com;
import java.sql.*;
public class Test3 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Connection ct=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
ct=DriverManager.getConnection("jdbc:odbc:animal","sa","as");
ps=ct.prepareStatement("select * from pet where name=? and age=? ");
ps.setString(1, "花花");
ps.setInt(2, 2);
rs=ps.executeQuery();
while(rs.next()){
System.out.println(rs.getString(1)+""+rs.getInt(2));
}
} catch (Exception e) {
e.printStackTrace();
// TODO: handle exception
}
finally{
try {
if(rs!=null){
rs.close();
}
if(ps!=null){
ps.close();
}
if(ct!=null){
ct.close();
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}
}Jdbc直接操作数据库
1. 先引入java.sql包和三个扎包
2. 定义需要的对象
3. 循环取出结果集的数据时,按编号和按名都行
下面是一个案例
代码如下:
package com;
import java.sql.*;
public class TestJdbc {
public static void main(String[] args) {
Connection ct=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver");
ct=DriverManager.getConnection("jdbc:microsoft:sqlserver://127.0.0.1:1433;databaseName=animal","sa","lhz8989518.");
ps=ct.prepareStatement("select * from dept");
rs=ps.executeQuery();
while(rs.next()){
System.out.println(rs.getInt(1)+" "+rs.getString(2)+" "+rs.getString(3));
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
finally{
try {
if(rs!=null){
rs.close();
}
if(ps!=null){
ps.close();
}
if(ct!=null){
ct.close();
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
}
}127.0.0.1表示你要连接到的数据库的ip
1433表示sql server默认端口
Sql 1433
Oracle 1521
Mysql 3306
Tomcat 8080
查看端口信息
Cmd>> netstat –an
Sql编程实战















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









