







Day five
字符编码

8比特(bit)=1字节(byte)
一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
ASCII:
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
中文:
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是UCS-16编码,用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
例:
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
TF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。(与web梦幻联动了)
Python的字符串
ord()函数获取字符的整数表示
chr()函数把编码转换为对应的字符


知道字符的整数编码,还可以用十六进制这么写str:
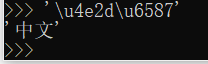
bytes类型数据
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:

本来为ASCII的直接转化
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
UTF-8编码怎么用啊?
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
到底是为什么有这么一块啊 有什么用 好难理解

貌似悟了,嘿嘿嘿

不是说大小写敏感的么?为什么这里不体现?
如果bytes中包含无法解码的字节,decode()方法会报错:
如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:

Len()函数可以用来计算str的字符数,也可以计算bytes的字节数。

注意:引号要用英文
bytes类型要有双引号
bytes的英文是原来的样子,但是中文是一串bytes代码
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3//这是为了告诉linux/os x系统,这是一个python可执行程序,windows会自动忽略这个注释
# -*- coding: utf-8 -*-//这是为了告诉python解释器,按照utf-8编码读取源代码,否则,代码中的中文可能会乱码
![]()
保证了我的文本编辑器确实是在utf-8编码下进行的。
格式化
1.%
输出格式化的字符串:(于C语言一样)
![]()
为什么’%‘没有显示内容?
![]()
%用来格式化字符串的,在字符串内部,%s表示字符串替换,%d表示用整数替换,括号里的要和符号对应好,如果只有一个,括号可以省略。
| 占位符 | 替换内容 |
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
例:
![]()
![]()
注意:不确定用什么,%s,它会把任何数据类型转换为字符串。
%%:

为什么我不理解,分号外边的是为了格式化,那里边为什么不能直接用%%?
format()
一次传入的参数一次替换字符串内的占位符,{0}、{1}、。。。。。。
f-string
最后一种格式化字符串的方法是使用以f开头的字符串,称之为f-string,它和普通字符串不同之处在于,字符串如果包含{xxx},就会以对应的变量替换:
>>> r = 2.5>>> s = 3.14* r ** 2>>> print(f'The area of a circle with radius {r} is {s:.2f}')
The area of a circle withradius 2.5is19.62
练习
小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,并用字符串格式化显示出'xx.x%',只保留小数点后1位:
法一:
s1=72
s2=85
r=(s2/s1-1)*100
print('真棒,小明,你提高了%.1f%%'%r)
法二:无,法一就挺好的















 3190
3190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









