







未标注中英文标点,实操时注意亲自手写
笔记
FHS规范
- 可分享:可以给其他系统挂载使用的目录
- 不可分享:自己机器上运作的配置文件
- 可变:需要经常更改的
- 不可变:有些数据不会经常随意更改
- /根目录
- usr:二级目录,相当于windows的C盘
- bin:必要命令,系统放置可执行文件
- home:家目录
- etc:配置文件
- var:动态数据
VFS
- 全称: 虚拟文件系统
- 内核层抽象出通用的文件系统接口
- 支持文件、网络、特殊文件系统
VFS抽象对象
- 超级块:文件系统
- 索引节点:具体文件
- 文件:进程打开的文件
- 目录项:文件路径
Linux文件系统特点
- 树形分层结构
- 一切皆文件(文件、设备统一管理)
Linux文件系统(XFS) - 高性能64位日志文件系统
- 带有日志功能防止宕机丢数据
- 原生提供备份工具(xfsdump/xfsrestore)
xfsdump备份
xfsrestore恢复
数据盘挂载
挂载:指的就是将设备文件中的顶级目录连接到Linux根目录下的某一目录,最好是空目录,访问此目录就等同于访问设备文件。
并不是根目录下任何一个目录都可以作为挂载点,由于挂载操作会使得原有目录中文件被隐藏,因此根目录以及系统原有目录都不要作为挂载点,会造成系统异常甚至崩溃,挂载点最好是新建的空目录。
df -Th
查看当前挂载文件
分区工具fdisk
sudo fdisk -l
可以查看当前的磁盘分区情况
fdisk 路径
就可以进行分区操作
会提示按m获取帮助
格式化mkfs.xfs 路径
挂载mount 路径(dev/sda3) 挂载目的点(u1)
取消挂载umount 已挂载的设备源(dev/sda3)或已挂载目的点(u1)
目录存储结构
- inode:存储数据的元数据(权限、时间、字节数等)
- 数据块:存储数据本身
Linux系统不用文件名来识别文件而是使用inode的号码来识别文件,每个inode都有一个号码(也有这种情况:就是虽然磁盘还有空间但是inode用光了,也会导致无法创建文件)
| 对象 | 命令 | 备注 |
|---|---|---|
| inode | stat file_name | 单文件元数据 |
| df -i | inode使用情况 | |
| 数据 | df -h | 磁盘使用情况 |
硬链接:ln 原文件 文件
这样就创建了原文件的一个硬链接
Linux常见命令
| 类别 | 命令 | 含义 | |
|---|---|---|---|
| 路径 | pwd、tree | 路径查看 | (pwd 查看当前目录、tree以树的形式呈现当前目录有什么) |
| 查询 | find、tar | 查找和归档 | 例:【以名字为查找方式(find -name “* .结尾”查找当前目录下为该结尾的所有文件)(find / -name “* .结尾查找/目录下的为该结尾的所有文件)】【man tar 可以查看帮助,tar cvf a.tar b.txt a.txt把b.txt 和a.txt压缩到压缩包a.tar里,tar xvf a.tar解压缩,还有tar -zcvf a.tar.gz b.txt a.txta.tar.gz是一种压缩包格式,解压用-zxvf】 |
| 进程 | ps、ss | 查看进程 | 【ps -A查看所有进程,ps -u root查看用户当前进程,ps -ef查看所有进程并知道它是通过什么来执行的(常用)】 |
| 查看 | cat、head | 查看文本 | 【cat 文件查看文件,cat -n b.txt >d.txt将b.txt里的内容加上行号存入d.txt中】【 head -n 2 b.txt查看b.txt的前2行或者head -2 b.txt也可】 |
| 统计 | uniq、sort | 排序和过滤 | (要求换行,以行为单位来排序和过滤)【sort 文件按ASCII码排序次从小到大输出,sort -u 文件可以过滤重复的,sort -r 文件逆序输出sort -n 文件按数字大小排序】 |
| 网络 | tcpdump | 网络抓包分析 | tcpdump host baidu.comtcpdump是抓包命令,host表示本机,baidu.com是抓包的网址,也可以用ip,把网址改成ip,tcpdump dst host 39.156.69.79是本机到ip,tcpdump src host 39.156.69.79是ip到本机(这里我也每太懂) |
| 性能 | top、htop、free | 内存CPU查看 | 【使用时直接输入即可,htop是top的高级版,比top好看,free可以这样free -m以兆的形式来查看,当然 以其他单位也可】 |
(因符号|与表格格式冲突所以写在这里)
ps -ef | grep ssh筛选查看ssh的进程(常用)
uniq 文件去除相邻行重复内容所以用它来去除重复可以与sort一起用 sort 文件 | uniq 也可以sort 文件 | uniq -c来显示重复次数
linux用户管理
Linux用户类型
| 用户类型 | UID | 备注 | |
|---|---|---|---|
| 管理员用户 | 0 | root | |
| 系统用户 | 1-499 | 可用于程序运行 | |
| 普通用户 | >1000 | 普通可登录用户 |
Linux用户
| 配置文件 | 命令 | ||
|---|---|---|---|
| 用户 | /etc/passwd | useradd/del | |
| 密码 | /etc/shadow | passwd | |
| 用户组 | /etc/group | groupadd/del |
Linux用户字段
| root | x | 0 | 0 | root | /root | /bin/bash |
|---|---|---|---|---|---|---|
| 用户名 | 密码 | 用户ID | 组ID | 用户全称 | 用户家目录 | 用户使用shell |
Linux用户命令
| 命令 | 选项 | 备注 |
|---|---|---|
| useradd | -s | Shell指定 |
| -p | 指定登录密码 | |
| -e | 指定账户过期日期 | |
| -f | 账号过期几天后永久停止 | |
| -g/G | 指定用户组 |
useradd 名字就可以创建一个用户,同时自动生成一个用户组
续表Linux用户命令
| 命令 | 选项 | 备注 |
|---|---|---|
| groupadd | -g | 指定gid |
| passwd | -S | 查看当前用户密码状态 |
| usermod | -aG | 将用户添加到指定组 |
| userdel | 删除用户 | |
| groupdel | 删除用户组 |
su 用户名来登录用户
whoami用来查看当前登录的用户
exit返回上一用户
Linux文件管理
Linux文件类型
| 文件标识 | 备注 | |
|---|---|---|
| - | 普通文件 | |
| d | 目录 | |
| l | 链接文件 | |
| s | 套接字 | |
| b | 块设备 | 与存储设备有关 |
| c | 字符检查 | 键盘 |
| p | 管道 | 进程中通信 |
绝对路径:以根目录/开头的
相对路径:相对于当前目录的关系
.表示当前目录
..表示上一级目录
增
mkdir目录名创建新目录(例:mkdir imooc)
touch 文件名 创建一个文件(方法有很多比如vim)(例:touch new.txt)
改
mv 原文件名 新文件名 改名字(例:mv new.txt 1.txt)
mv 文件名 路径 移动文件到某目录(例:mv 1.txt ../)
cp 文件1 文件2 将文件1内容复制到文件2中(例:cp 1.txt 2.txt)
cp -r 目录1 目录2 将目录1完全复制到目录2(例:cp -r old new)
查
cd和cat
删
rm 文件名 删除文件
rm -r 目录名 删除目录
关于链接文件
硬链接:ln 文件一 文件二 两个文件指向同一个inode号码,当查看文件信息时(ls -l或ll)文件显示的是普通文件
软连接:ln -s 文件一 文件二 文件二指向文件一(通过文件名)
这时查看文件信息时就会看到文件二是一个链接文件
Linux权限管理
Linux文件图解
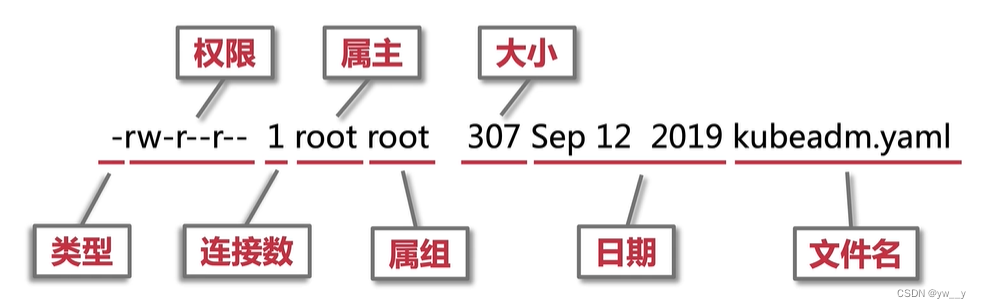
Linux权限所有者
| 类型 | 含义 | 备注 |
|---|---|---|
| owner | 属主 | 文件所有者 |
| group | 属组 | 所属组内用户 |
| other | 其他 | 上述用户之外的 |
Linux权限类型
| 类型 | 含义 | 权限缩写 |
|---|---|---|
| read | 可读 | r |
| write | 可写 | w |
| execute | 可执行 | x |
Linux权限数字解析
| 数字 | 权限类型 | 符号 |
|---|---|---|
| 0 | 无权限 | — |
| 1 | 执行权限 | –x |
| 2 | 写 | -w- |
| 3 | 执行+写 | -wx |
| 4 | 读 | rw- |
| 7 | 读+写+执行 | rwx |
用1 2 4就可以表示所有的权限类型
比如:1(执行)+2(写)=3 3表示写+执行
Linux权限操作
| 命令 | 对象 | 操作 | 权限模式 |
|---|---|---|---|
| chmod | u | + | r |
| g | - | w | |
| o | = | x | |
| a |
例:chmod u+w 文件名表示给用户加上写的权限
还可以通过数字加减权限
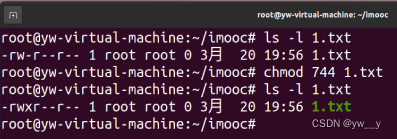
-w就是去除写的权限
=就是赋值号
| 命令 | 对象 | 命令 |
|---|---|---|
| chown | user | chown x:file |
| group | chown :y file |
chown 用户1:用户1 文件1 表示将文件1的权限给用户1
Linux ACL权限
- Access Control List(访问控制列表)
- UGO 权限加强版
( 本机不支持,此处笔者就先不写了)
Linux文本操作(三剑客)
Awk
- 样式扫描和处理语言,用于文本处理
- AWK、NAWK、GAWK(不同版本)
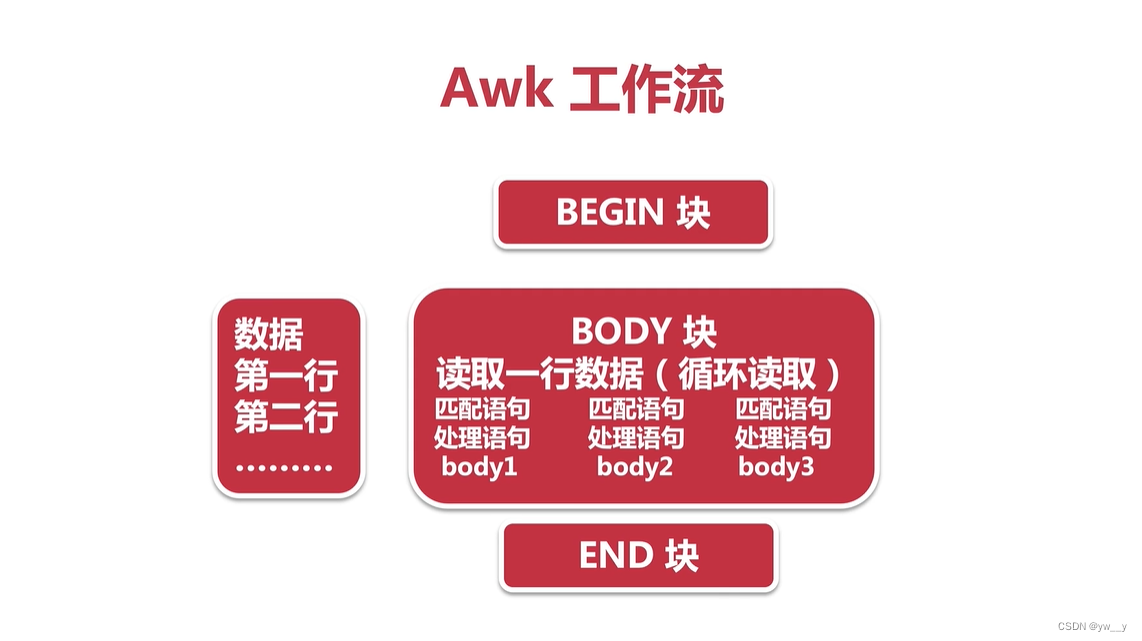
- BEGIN块:程序开始时候执行,只执行一次
- BODY块:会循环针对每一行执行命令
- END块:程序最后执行
Awk内置变量
| 变量 | 说明 |
|---|---|
| NR | 已输入记录条数 |
| NF | 当前记录域的个数 |
| FS | 域分隔符 |
| RS | 当前记录分隔符 |
| OFS | 输出域分隔符 |
| ORS | 输出记录分隔符 |
| OFMT | 输出数字格式 |
-
数据过滤特定列
awk '{print $1}' a.txt打印第一个域(一整列)(默认分隔符是空格)
$代表指定域,
$1就是第一个域
awk -F ":" '{print $1}' a.txt表示把”:”作为分隔符分隔域并打印第一个域 -
内置变量的应用
awk 'BEGIN{FS=":"} {print $1}' a.txt打印第一个域
awk 'BEGIN{FS=":";total=0} {print $1;total+=1;}END{print tatal}'在BEGIN中设置分隔符,在主体中设置一个变量,在结尾输出变量 -
AWK操作符
略(例:+= == --之类) -
AWK数组
-
流程控制、循环
相关语法有些多,暂时不写,有我没学过的
Grep
- 文本搜索工具
- 也有不同版本grep、egrep、fgrep
正则表达式
| 字符 | 说明 |
|---|---|
| ^ | 匹配字符串开始 |
| $ | 匹配字符串结束 |
| * | 匹配前面子表达式零次或多次 |
| + | 匹配前面子表达式 |
| ? | 匹配前面子表达式零次或一次 |
| {n} | 匹配n次 |
| {n,m} | 匹配n到m次 |
Grep命令选项
| 选项 | 说明 |
|---|---|
| -c | 只打印匹配的文本行的行数 |
| -i | 忽略字母大小写 |
| -h | 当搜索多个文件时,不显示匹配文件前缀名 |
| -n | 列出所有的匹配的文本行,并显示行号 |
| -v | 只显示不匹配的文本行 |
| -w | 匹配整个单词 |
| -E/P | 支持扩展/Perl正则表达式 |
实操
- 多个文件匹配待定后缀名文件
ls -l | grep txt查找后缀名为txt的文件(当前目录)
ps aux | grep ssh查找关于ssh的进程 - 匹配文件特定上文
grep mu 1.txt查找在1.txt中的mu
grep -n mu 1.txt查找并显示行号
也可以在后面放多个文件 - 递归查找子目录
grep -r com其中-r表示递归查找com是查找的内容,这个查找可以递归到子目录里面的文件
grep -r --exclude-dir=child com表示忽略子目录child中文件查找com(在查找代码忽略库时常用) - 结合正则匹配特定IP或者邮箱
匹配IP
grep ^192 3.tt表示查找在3.tt中的192开头的IP
grep $[89] 3.tt表示查找在3.tt中的以89结尾的IP
(正则符号表格在前面)
匹配邮箱
grep -E "[[:alnum:]]{4,18}@[[:alnum:]]{2,14}.(com|net|cn|org)" 2.txt[[:alnum:]]表示字符串,{4,18}表示查找4~18次,整个语句表示查找2.txt中符合引号内的格式的邮箱 - 忽略查找
grep -i wu 1.txt忽略大小写查找1.txt里的wu
Sed - 流编辑器
- 前身时ed编辑器
- 文本处理工具
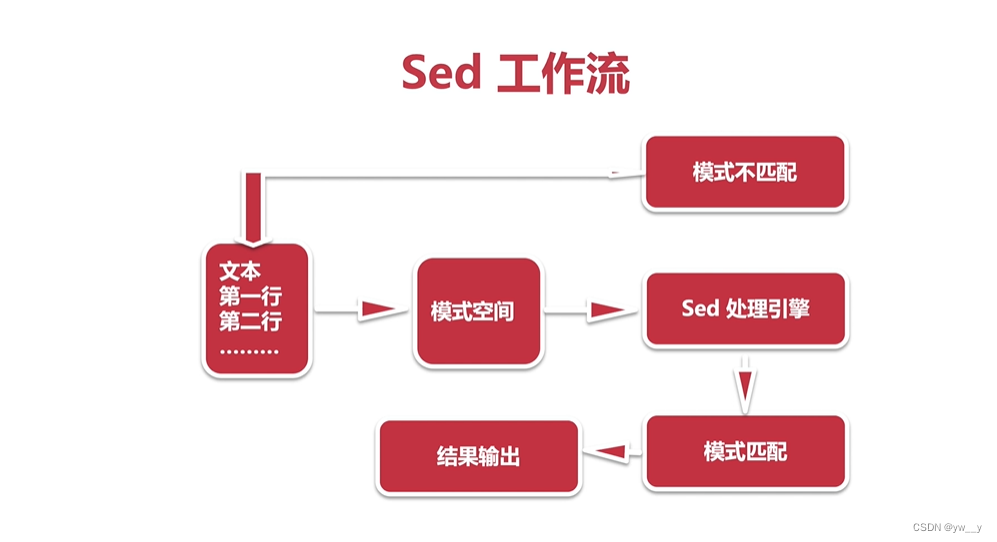
工作模式 - 读取行:输入流中读取一行到模拟空间缓冲区
- 执行:针对读取的行应用sed脚本
- 显示:经过处理后输出流,并清空模式空间缓冲区
sed命令选项
| 选项 | 说明 |
|---|---|
| -n | 安静模式 |
| -e | 直接应用sed命令 |
| -r | 扩展正则表达式 |
| -i | 直接修改读取行内容 |
| -f | 输出到指定文件中 |
sed动作
| 选项 | 说明 |
|---|---|
| a | 新增 |
| c | 取代 |
| d | 删除 |
| i | 插入 |
| p | 打印 |
| s | 替换 |
实操
- 查找替换特定字符
sed ‘s/a/a1/’ 1.txt替换1.txt中a为a1(没有更改原文件,因为默认只是处理缓冲区输出到终端)
若要修改则sed -i ‘s/a/a1/’ 1.txt - 删除某行或某几行
sed ’2d‘ 1.txt表示删除第二行
sed '2,5d' 1.txt表示删除第二到五行 - 文本插入
sed ‘2i\a2’ 1.txt在第二行插入文本a2 - 字符拼接
sed ‘s/love/very &/’ 1.txt这句中&是匹配符,在本句匹配的是love,输出时将very加到love前面一起输出 - 文本行编号















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









