






网址:https://2y7c3.github.io/3DV-TON/
情况:未开源代码,使用两个试衣图像开源数据集dressCode,VITON-HD和一个视频试衣开源数据集ViViD 数据集。
简介:利用econ人体重建的额外信息做试衣视频
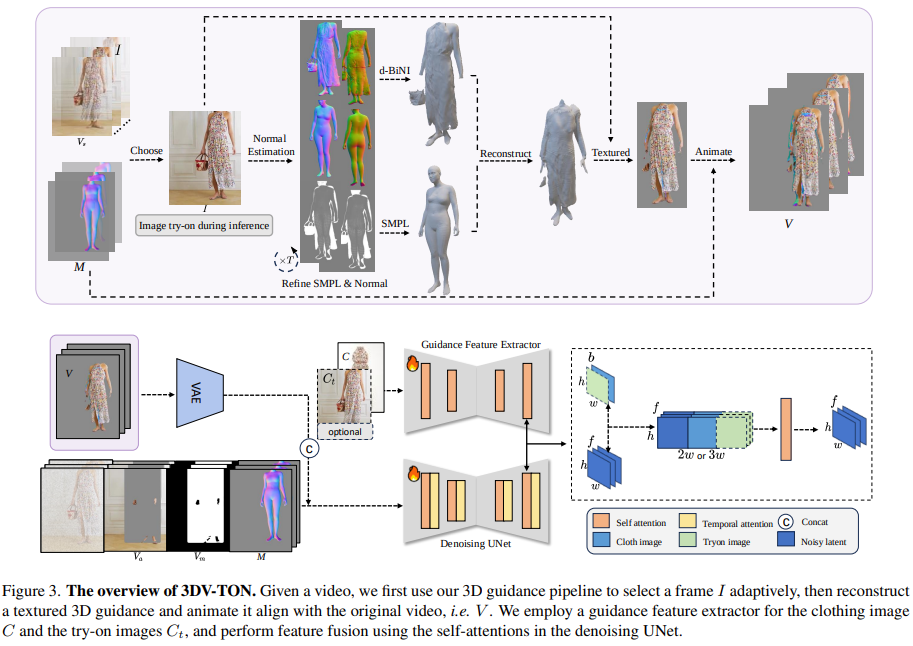
论文理解
上半部分 试衣人体三维重建:
推理时,先从视频中挑选一帧用图像试衣算法做图像层面的换衣,
再基于econ进行人体重建:先法线图估计,然后用简单的smplx优化算法得到初始smplx参数(smplx模型渲染为法线图)(M)初始化,之后优化,其中优化过程更注重服装的优化,所以只对 SMPL-X’s shape β, translation t parameters and
camera scale s, focusing on minimizing silhouette and normal loss,不对人体pose参数优化。然后dBiNI重建,之后纹理映射,无法映射的部分用法线像素代替。最终用smplx pose M参数驱动后得到V。
下部分 视频虚拟试衣:
将试衣人体图像V输入VAE编码后和噪声图,Va(去掉了身体和服装),Vm(去掉了身体和服装的mask图),M(smplx法线图)concat以后输入diffusion,用自注意力将C(服装图)或者Ct(人体试衣图)的特征作为条件输入,最终输出得到试衣视频。
训练时上下两个部分用的都是同一套服装同一个人的视频或者图像进行训练,下半部分的V、Ct、C的三个输入按概率分别不输入,这样在推理时就可以更鲁棒。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









