







1.Mysql数据库的优化技术
对mysql优化时一个综合性的技术,主要包括
a: 表的设计合理化(符合3NF)
b: 添加适当索引(index) [四种: 普通索引、主键索引、唯一索引unique、全文索引]
c: 分表技术(水平分割、垂直分割)
d: 读写[写:update/delete/add]分离
e: 存储过程 [模块化编程,可以提高速度]
f: 对mysql配置优化 [配置最大并发数my.ini, 调整缓存大小 ]
g: mysql服务器硬件升级
h: 定时的去清除不需要的数据,定时进行碎片整理(MyISAM)
什么样的表才是符合3NF (范式)
表的范式,是首先符合1NF,才能满足2NF , 进一步满足3NF
1NF: 即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只有数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sqlserver),就自动的满足1NF
☞ 数据库的分类
关系型数据库:mysql/oracle/db2/informix/sysbase/sql server
非关系型数据库: (特点: 面向对象或者集合)
NoSql数据库: MongoDB(特点是面向文档)
2NF: 表中的记录是唯一的, 就满足2NF, 通常我们设计一个主键来实现
3NF: 即表中不要有冗余数据, 就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放. 比如下面的设计就是不满足3NF:
反3NF : 但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
问题是: 如何从一个大项目中,迅速的定位执行速度慢的语句. (定位慢查询)?
① 首先我们了解mysql数据库的一些运行状态如何查询(比如想知道当前mysql运行的时间/一共执行了多少次select/update/delete.. / 当前连接)
show status
常用的:
show status like ‘uptime’ ;
show stauts like ‘com_select’ showstauts like ‘com_insert’ ...类推 update delete
☞ show [session|global] status like .... 如果你不写 [session|global] 默认是session 会话,指取出当前窗口的执行,如果你想看所有(从mysql 启动到现在,则应该 global)
show status like ‘connections’;
//显示慢查询次数
show status like ‘slow_queries’;
② 如何去定位慢查询
构建一个大表(400 万)-> 存储过程构建
默认情况下,mysql认为10秒才是一个慢查询.
修改mysql的慢查询:
show variables like ‘long_query_time’ ; //可以显示当前慢查询时间
set long_query_time=1 ;//可以修改慢查询时间
构建大表->大表中记录有要求, 记录是不同才有用,否则测试效果和真实的相差大.
#创建表DEPT
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
# 随机产生字符串
#定义一个新的命令结束符合
delimiter $$
#删除自定的函数
drop function rand_string $$
#这里我创建了一个函数.47-61行是一个函数定义过程
#rand_string(n INT) rand_string 是函数名 (n INT) //该函数接收一个整数
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
#chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ',字符总长为52;
#concat 连接参数并返回
#substring SUBSTRING(str FROM pos FOR len) 带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。
#floor(x) 返回不大于X的最大整数值
#and(N) 返回一个随机浮点值 v ,范围在 0 到1 之间 (即, 其范围为 0 ≤ v ≤ 1.0)。
#若已指定一个整数参数 N ,则它被用作种子值,用来产生重复序列。
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
select rand_string(6);
# 随机产生部门编号
delimiter $$
drop function rand_num $$
#这里我们又自定了一个函数
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
select rand_num();
#******************************************
#向emp表中插入记录(海量的数据)
delimiter $$
drop procedure insert_emp $$
#创建存储过程
#随即添加雇员[光标] 400w
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
#调用刚刚写好的函数, 1800000条记录,从100001号开始
call insert_emp(100001,4000000);
#**************************************************************
# 向dept表中插入记录
delimiter $$
drop procedure insert_dept $$
create procedure insert_dept(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into dept values ((start+i) ,rand_string(10),rand_string(8));
until i = max_num
end repeat;
commit;
end $$
delimiter ;
call insert_dept(100,10);
#------------------------------------------------
#向salgrade 表插入数据
delimiter $$
drop procedure insert_salgrade $$
create procedure insert_salgrade(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
ALTER TABLE emp DISABLE KEYS;
repeat
set i = i + 1;
insert into salgrade values ((start+i) ,(start+i),(start+i));
until i = max_num
end repeat;
commit;
end $$
delimiter ;
#测试不需要了
#call insert_salgrade(10000,1000000);
#----------------------------------------------
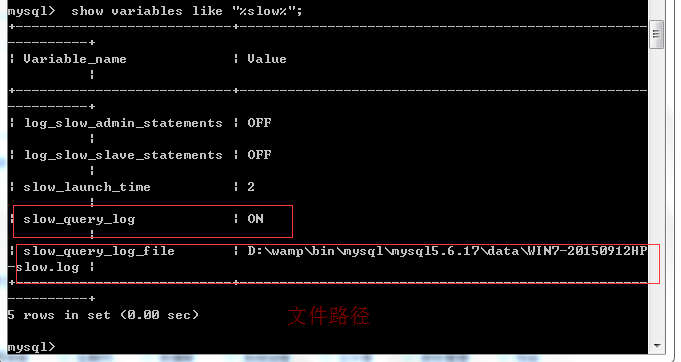
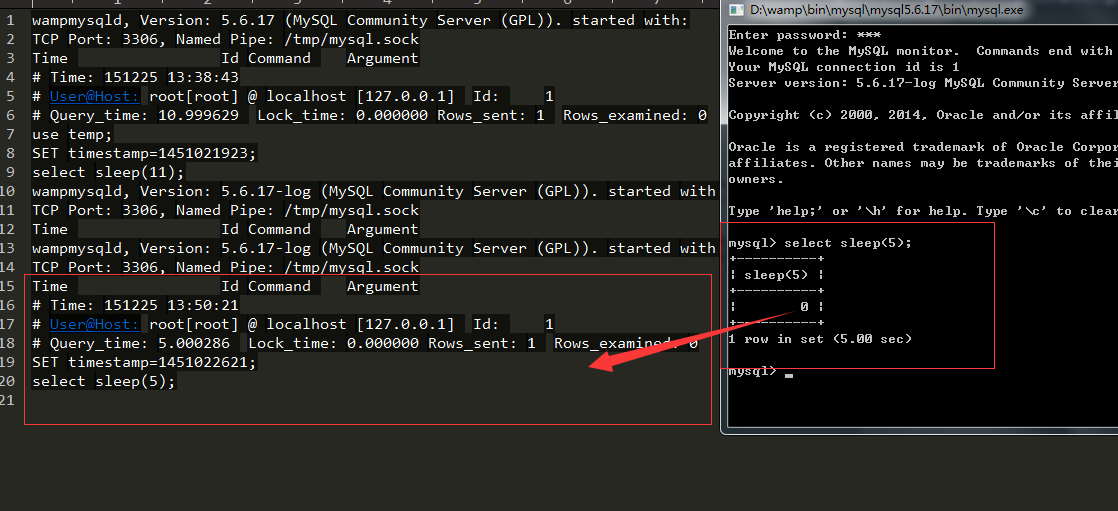
开启mysql慢查询日志
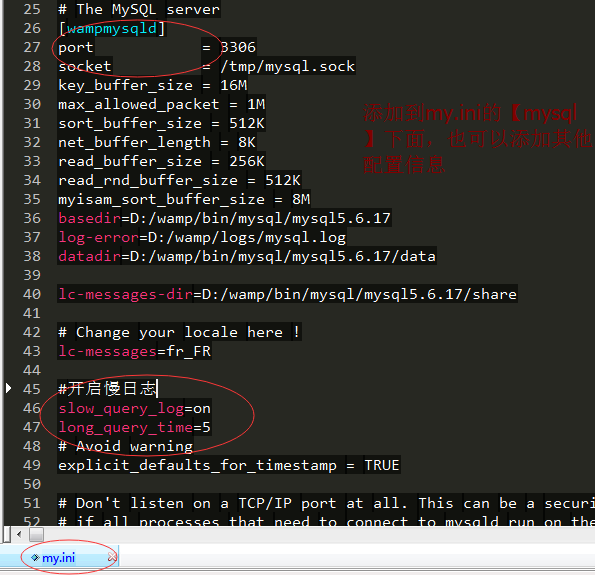
修改配置文件后,重启mysql服务















 1595
1595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









