







数据挖掘
数据挖掘∶也就是data mining,是一个很宽泛的概念,也是一个新兴学科,旨在如何从海量数据中挖掘出有用的信息来。
数据挖掘这个工作Bl(商业智能)可以做,统计分析可以做,大数据技术可以做,市场运营也可以做,或者用excel分析数据,发现了一些有用的信息,然后这些信息可以指导你的
business,这也属于数据挖掘。
机器学习
机器学习:machine learning,是计算机科学和统计学的交叉学科,基本目标是学习一个x->y的函数(映射),来做分类、聚类或者回归的工作。之所以经常和数据挖掘合在一起讲是因为现在好多数据挖掘的工作是通过机器学习提供的算法工具实现的,例如广告的ctr预估,PB级别的点击日志在通过典型的机器学习流程可以得到一个预估模型,从而提高互联
深度学习
深度学习: deep learning,,机器学习里面现在比较火的一个topic,本身是神经网络算法的衍生,在图像,语音等富媒体的分类和识别上取得了非常好的效果,所以各大研究机构和公司都投入了大量的人力做相关的研究和开发。
总结︰数据挖掘是个很宽泛的概念,数据挖掘常用方法大多来自于机器学习这门学科,深
度学习也是来源于机器学习的算法模型,本质上是原来的神经网络。
MLlib基本数据模型
数据
vectors.txt
1 2.3 4.5
3 3.1 5.6
4 3.2 7.8
package cn.tedu.vector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/* 学习Vector类型,因为后面有一些模型要求将行数据封装为向量来处理
*
* */
object Driver01 {
def main(args: Array[String]): Unit = {
//创建向量类型,传入的类型是Double类型。如果是Int类型,会自动转换
val v1=Vectors.dense(1,2,3.1,4.5)
//掌握这种方式,通过传入Array[ Double]来创建向量
val v2=Vectors.dense(Array[Double](1,2,3,4))
val conf=new SparkConf().setMaster("local").setAppName("vectors")
val sc=new SparkContext(conf)
val data=sc.textFile("D://data/vectors.txt",2)
//
val r1=data.map { line => line.split(" ").map { num => num.toDouble } }
.map { arr => Vectors.dense(arr) }
r1.foreach { println }
// println(v1)
}
}
package cn.tedu.vector
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/*
* 学习向量标签类型 */
object Driver02 {
def main(args: Array[String]): Unit = {
val v1=Vectors.dense(2.2,3.1,4.5)
//创建一个向量标签类型 1参:标签值(因变量Y)2参∶有所有自变量(X1,X2...)组成的向量
val lb1=LabeledPoint(1,v1)
// println(lb1)
//获取向量标签中的向量
// println(lb1.features)
//获取标签值
// println(lb1.label)
//处理vectors.txt其中第一列是标签值二三列是自变量
val conf=new SparkConf().setMaster("local").setAppName("vectors")
val sc=new SparkContext(conf)
val data=sc.textFile("D://data/vectors.txt")
//方式1
val r1=data.map { line => line.split(" ").map { num => num.toDouble } }
.map { arr =>
val v1=Vectors.dense(arr.drop(1))
LabeledPoint(arr(0),v1) }
r1.foreach { println }
//方式2
val r2=data.map { line =>
val info=line.split(" ")
val label=info.head.toDouble
val features=info.drop(1).map { num => num.toDouble }
LabeledPoint(label,Vectors.dense(features ))
}
// r2.foreach { println }
}
}
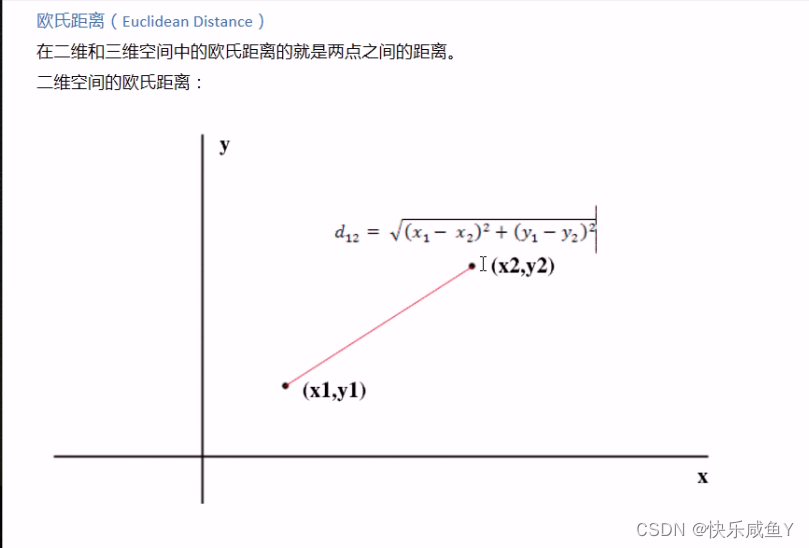
欧氏距离

曼哈顿距离

红线代表曼哈顿距离,
绿色代表欧氏距离,也就是直线距离,
而蓝色和黄色代表等价的曼哈顿距离。曼哈顿距离–两点在南北方向上的距离加上在东西方向上的距离,即d(i , j)=lxi-xi+lyi-yji]。
对于一个具有正南正北、正东正西方向规则布局的城镇街道,从一点到达另一点的距离正是在南北方向上旅行的距离加上在东西方向上旅行的距离因此曼哈顿距离又称为出租车距离,曼哈顿距离不是距离不变量,当坐标轴变动时,点间的距离就会不同.
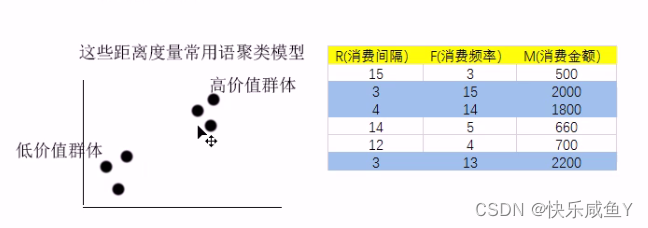
常见的距离度量和相似度度量
距离度量常见的:
1.欧式距离
2.曼哈顿距离
3.切比雪夫距离
这些距离度量常用于聚类模型
package cn.tedu.vector
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.stat.Statistics
/*
* 学习Spark提供了统计工具类
* */
object Driver03 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("statistic")
val sc=new SparkContext(conf)
val r1=sc.makeRDD(List(1,2,3,4,5))
//RDD[Int]->RDD[Vector]
val r2=r1.map { num => Vectors.dense(num) }
val result=Statistics.colStats(r2)
// r1.foreach { println }
println(result.max)
println(result.min)
println(result.mean)//均值
println(result.variance)//方差
println(result.count)
println(result.numNonzeros)//不是0的元素
println(result.normL1)//计算曼哈顿距离
println(result.normL2)//计算欧氏距离
}
}
切比雪夫距离
切比雪夫距离(Chebyshev Distance),在数学中,切比雪夫距离或是Loo度量是向量空间中的其各坐标数值差的最大值。
国际象棋中,国王走一步能够移动到相邻的8个方格中的任意一个。那么国王从格子(x1,y1)走走走试试。
你会发现最少步数总是max( | x2-x1|,| y2-y1|)步。这种距离度量方法叫切比雪夫距离。
夹角余弦公式

package cn.tedu.vector
/*
* 欧式距离
* */
object Driver04 {
def main(args: Array[String]): Unit = {
val a1=Array(1,2)
val a2=Array(4,8)
//a1 a2 两点之前的欧氏距离
//提示1:拉链方法zip
//开方方法Math.sqrt
//方式1
// val a3=a1.zip(a2)
// var sum=0
// a3.foreach{num=>
// val a=(num._1).toInt
// val b=(num._2).toInt
// sum+=(a-b)*(a-b)
// }
// println(Math.sqrt(sum))
//方式2
val a3=a1 zip a2
val a4=Math.sqrt(a3.map{line => (line._1-line._2)*(line._1-line._2)}.sum)
// println(a4)
//计算出a1和a2向量之间的夹角余弦
val cos1=a3.map{line=> line._1*line._2}.sum
val cos2=Math.sqrt(a1.map{line=> line*line}.sum)
val cos3=Math.sqrt(a2.map{line=> line*line}.sum)
println(cos1/(cos2*cos3))
}
}
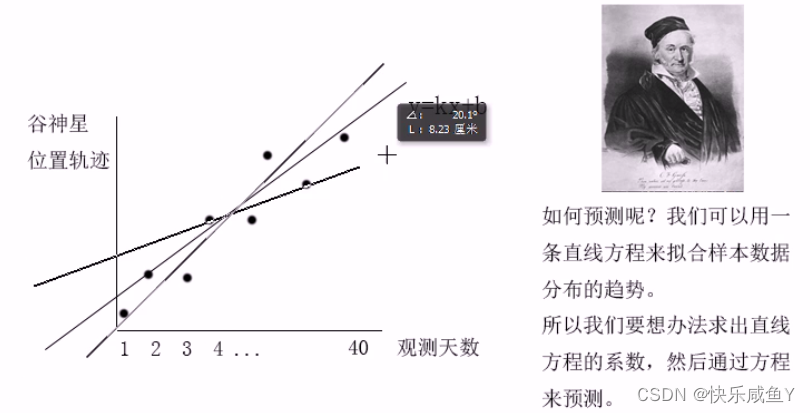
最小二乘法
介绍
最小二乘法(又称最小平方法)是一种数学优化扶术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化嫡用最小二乘法来表达。
考虑的问题1:
符合趋势的方程有很多,到底选择哪一个?如何选择?选最优的那个方程
考虑的问题2:
最优条件如何定义?
希望每天的误差和最小,则认为是最优
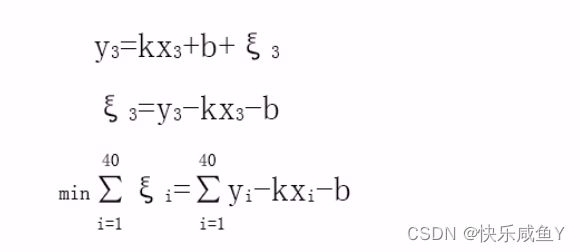
但是注意:用误差和来衡量,存在误差正负号抵消的问题。处理方式:
①绝对值法
②平方法
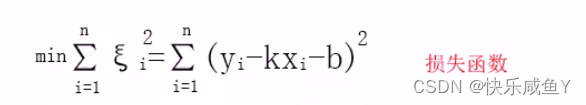
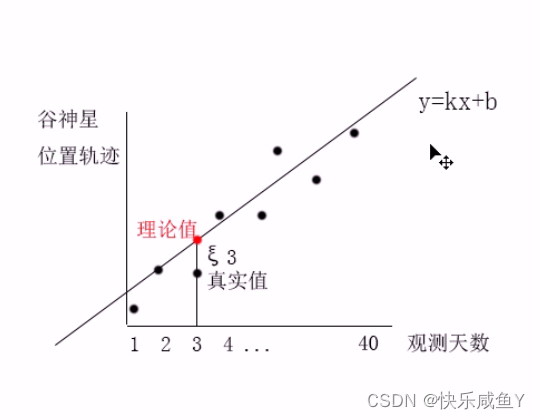
求解一组k和b,使得误差平方和最小(残差平方和RSS),得到对应的最优解。
建模相关的概念补充:
1.建立目标方程去拟合样本数据,目标方程不固定,可以是线性方程,也可以是非线性方程
2.求解目标方程的系数。目的是找出目标方程系数的最优解。所以需要找出目标方程的CostFunction(损失函数,代价方程)
3.通过损失函数得到最优解
3.通过损失函数得到最优解
补充:损失函数不固定,目标方程不同,损失函数也随之变化
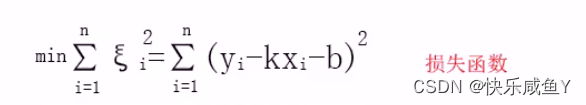
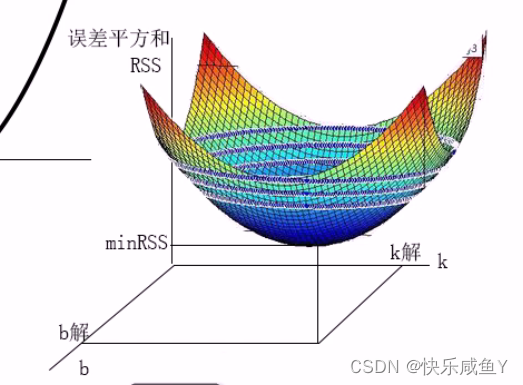
分别对k和b求偏导=0从而解出k和b

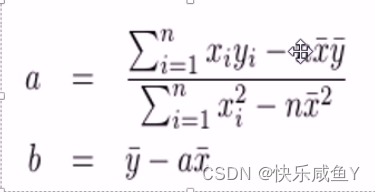
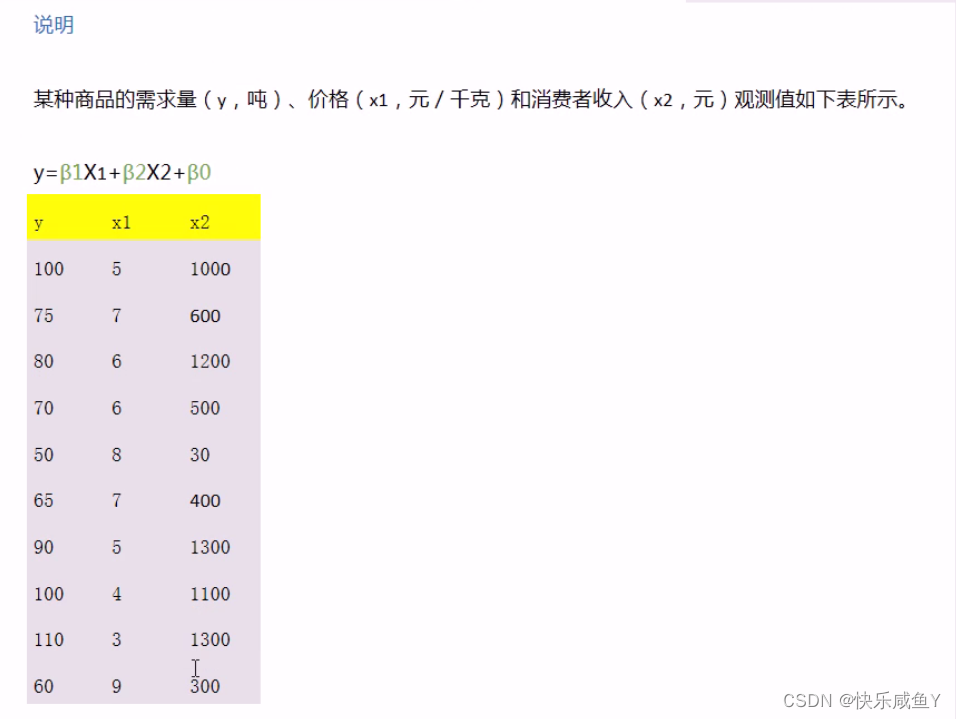
数据
100|5 1000
75|7 600
80|6 1200
70|6 500
50|8 30
65|7 400
90|5 1300
100|4 1100
110|3 1300
60|9 300
package cn.tedu.lritem
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
object Driver {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("statistic")
val sc=new SparkContext(conf)
//创建SparkSql的上下文对象,用于创建DataFrame(数据框,也可以看做是一张表)
val sqc=new SQLContext(sc)
val data=sc.textFile("D://data/ml/lritem.txt")
//第一步:RDD[ String]->RDD[(×1,x2,Y)]
val r1=data.map { line =>
val info=line.split("\\|")
val Y=info(0).toDouble
val X1=info(1).split(" ")(0).toDouble
val X2=info(1).split(" ")(1).toDouble
(X1,X2,Y)
}
//第二步:RDD[(×1,×2, Y)]->DataFrame(×1,x2,Y)
//将一个RDD转为一个DataFrame,指定列名
//注意事项:①转为DataFrame的条件是,RDD里的元素类型必须是元组类型
//②分配列名时,个数和顺序要对应一致
val df1=sqc.createDataFrame(r1).toDF("X1","X2","Y")
// df1.show
//第三步,为了满足建模需要,DataFrame(X1,X2,V)->DataFrame(Vector(X1,X2))
//创建向量转换工具类,setInputcols:指定哪些列是自变量列
//setoutputcol:为所有的自变量列起一个别名(自定义的)
val ass=new VectorAssembler().setInputCols(Array("X1","X2"))
.setOutputCol("features")
val df1Vectors=ass.transform(df1)
//第四步:调用Spark MLlib库,建立线性回归模型,底层用最小二乘法来求解系数
//setFeaturescol∶指定自变量列名
//setLabelcol:指定因变量列名
//setFitIntercept :true表示计算截距项系数
//fit:代入样本集数据建模
val model=new LinearRegression().setFeaturesCol("features")
.setLabelCol("Y")
.setFitIntercept(true)//---函数(y=kx+b)中的b
.fit(df1Vectors)
//获取自变量系数
val coef=model.coefficients
//获取截距项系数
val intercept=model.intercept
println(coef)
println(intercept)
//[-6.497089660950071,0.01631790530613304]
//106.36879716405959
//获取模型的R方值,最大值为1.越趋近1,说明模型对数据的拟合越好
//在生产环境下,R方值在0.55以上都可以接受
val R2=model.summary.r2
println(R2)
//-获取模型的误差平方和
val RSS=model.summary.residuals
//第五步,通过模型实现预测
//回代原样本集,获取预测结果
val predict=model.transform(df1Vectors)
// predict.show
//预测×1=1x2=350 时,预测Y=?
//RDD[ (X1,X2,Y)]->DataFrame(X1,X2,Y)->DataFrame(Vector(X1,X2), Y)
val testRDD=sc.makeRDD(List((10,350,0)))
val testDF=sqc.createDataFrame(testRDD).toDF("X1","X2","Y")
val testDFVector=ass.transform(testDF)
val testpredict=model.transform(testDFVector)
testpredict.show
}
}
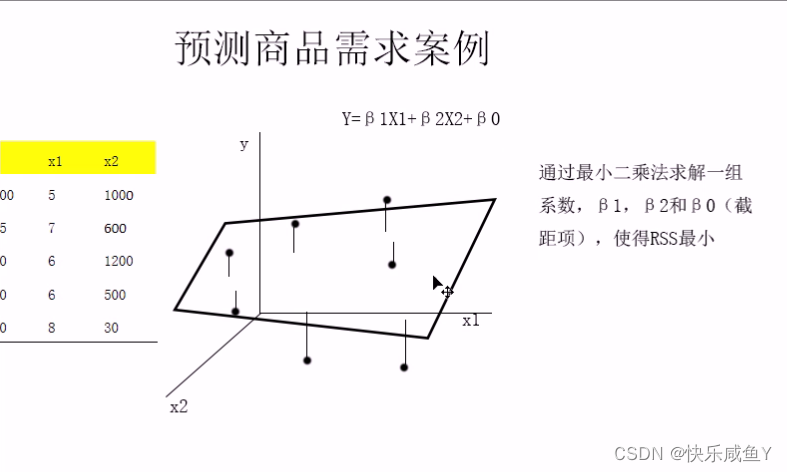
针对预测商品需求案例,我们建立的是多元线性回归模型;
1)回归模型是用于预测的,对于回归模型的种类:
①最小二乘回归
②梯度下降回归
③岭回归
④Lasso回归
2)如果自变量只有一个,则是一元。如果自变量超过1个,都可以称为多元。
3)目标方程,如果是直线方程,平面方程,超平面方程,这些都属于超平方面方程。线性方程的形式固定,比如:
直线方程:Y=β 1X1 +β0
平面方程:Y= β1X1+β 2X2+β 0
超平面方程:Y=β 1X1+β 2X2+…+β nXn+β 0
此外,目标方程也可以是一个非线性方程,比如:Y= 3 1x1+$ 2X2+β 3X1X2 …
所以非线性方程的形式不固定,不宜求解。
课后∶案例—预测谋杀率
数据
lrmurder-sample.txt
3615,3624,2.1,69.05,15.1,41.3,20,50708
365,6315,1.5,69.31,11.3,66.7,152,566432
2212,4530,1.8,70.55,7.8,58.1,15,113417
2110,3378,1.9,70.66,10.1,39.9,65,51945
21198,5114,1.1,71.71,10.3,62.6,20,156361
2541,4884,0.7,72.06,6.8,63.9,166,103766
3100,5348,1.1,72.48,3.1,56,139,4862
579,4809,0.9,70.06,6.2,54.6,103,1982
8277,4815,1.3,70.66,10.7,52.6,11,54090
4931,4091,2,68.54,13.9,40.6,60,58073
868,4963,1.9,73.6,6.2,61.9,0,6425
813,4119,0.6,71.87,5.3,59.5,126,82677
11197,5107,0.9,70.14,10.3,52.6,127,55748
5313,4458,0.7,70.88,7.1,52.9,122,36097
2861,4628,0.5,72.56,2.3,59,140,55941
2280,4669,0.6,72.58,4.5,59.9,114,81787
3387,3712,1.6,70.1,10.6,38.5,95,39650
3806,3545,2.8,68.76,13.2,42.2,12,44930
1058,3694,0.7,70.39,2.7,54.7,161,30920
4122,5299,0.9,70.22,8.5,52.3,101,9891
5814,4755,1.1,71.83,3.3,58.5,103,7826
9111,4751,0.9,70.63,11.1,52.8,125,56817
3921,4675,0.6,72.96,2.3,57.6,160,79289
2341,3098,2.4,68.09,12.5,41,50,47296
4767,4254,0.8,70.69,9.3,48.8,108,68995
746,4347,0.6,70.56,5,59.2,155,145587
1544,4508,0.6,72.6,2.9,59.3,139,76483
590,5149,0.5,69.03,11.5,65.2,188,109889
812,4281,0.7,71.23,3.3,57.6,174,9027
7333,5237,1.1,70.93,5.2,52.5,115,7521
1144,3601,2.2,70.32,9.7,55.2,120,121412
18076,4903,1.4,70.55,10.9,52.7,82,47831
5441,3875,1.8,69.21,11.1,38.5,80,48798
637,5087,0.8,72.78,1.4,50.3,186,69273
10735,4561,0.8,70.82,7.4,53.2,124,40975
2715,3983,1.1,71.42,6.4,51.6,82,68782
2284,4660,0.6,72.13,4.2,60,44,96184
11860,4449,1,70.43,6.1,50.2,126,44966
931,4558,1.3,71.9,2.4,46.4,127,1049
2816,3635,2.3,67.96,11.6,37.8,65,30225
681,4167,0.5,72.08,1.7,53.3,172,75955
4173,3821,1.7,70.11,11,41.8,70,41328
12237,4188,2.2,70.9,12.2,47.4,35,262134
数据2
lrmurder-test.txt
615,3624,2.1,69.05,0,41.3,20,50708
65,6315,1.5,69.31,0,66.7,152,566432
212,4530,1.8,70.55,0,58.1,15,113417
110,3378,1.9,70.66,0,39.9,65,51945
1198,5114,1.1,71.71,0,62.6,20,156361
541,4884,0.7,72.06,0,63.9,166,103766
100,5348,1.1,72.48,0,56,139,4862
79,4809,0.9,70.06,0,54.6,103,1982
277,4815,1.3,70.66,0,52.6,11,54090
931,4091,2,68.54,0,40.6,60,58073
868,4963,1.9,73.6,6.2,61.9,0,6425
813,4119,0.6,71.87,5.3,59.5,126,82677
11197,5107,0.9,70.14,10.3,52.6,127,55748
5313,4458,0.7,70.88,7.1,52.9,122,36097
2861,4628,0.5,72.56,2.3,59,140,55941
2280,4669,0.6,72.58,4.5,59.9,114,81787
3387,3712,1.6,70.1,10.6,38.5,95,39650
3806,3545,2.8,68.76,13.2,42.2,12,44930
1058,3694,0.7,70.39,2.7,54.7,161,30920
4122,5299,0.9,70.22,8.5,52.3,101,9891
5814,4755,1.1,71.83,3.3,58.5,103,7826
9111,4751,0.9,70.63,11.1,52.8,125,56817
3921,4675,0.6,72.96,2.3,57.6,160,79289
2341,3098,2.4,68.09,12.5,41,50,47296
4767,4254,0.8,70.69,9.3,48.8,108,68995
746,4347,0.6,70.56,5,59.2,155,145587
1544,4508,0.6,72.6,2.9,59.3,139,76483
590,5149,0.5,69.03,11.5,65.2,188,109889
812,4281,0.7,71.23,3.3,57.6,174,9027
7333,5237,1.1,70.93,5.2,52.5,115,752
11144,3601,2.2,70.32,9.7,55.2,120,12141
218076,4903,1.4,70.55,10.9,52.7,82,47831
5441,3875,1.8,69.21,11.1,38.5,80,48798
637,5087,0.8,72.78,1.4,50.3,186,69273
10735,4561,0.8,70.82,7.4,53.2,124,40975
2715,3983,1.1,71.42,6.4,51.6,82,68782
2284,4660,0.6,72.13,4.2,60,44,96184
11860,4449,1,70.43,6.1,50.2,126,44966
931,4558,1.3,71.9,2.4,46.4,127,1049
2816,3635,2.3,67.96,11.6,37.8,65,30225
681,4167,0.5,72.08,1.7,53.3,172,75955
4173,3821,1.7,70.11,11,41.8,70,41328
12237,4188,2.2,70.9,12.2,47.4,35,262134
说明
下表统计了某个国家某一时期的谋杀率( murder )和其他因素之间的影响,这些因素包括:Population人口, Income(收入) ,literacy(文盲程度),LifeExp(生活经验),HSG|ad(文献中未做具体解释),Frost(温度在冰点以下的平均天数) ,Area(地区 )
请尝试用MLlib,利用样本集(lrmurder-sample )建立预测模型,并利用模型对测试集( Irmurder-test )进行验证
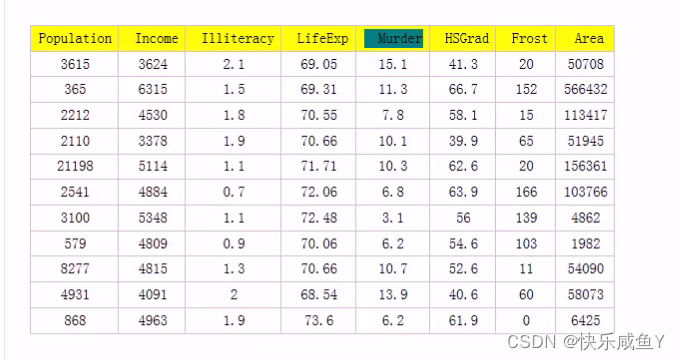
展示
package cn.tedu.lritem
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.regression.LinearRegression
//谋杀率计算
object Driver2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("murder")
val sc=new SparkContext(conf)
val data=sc.textFile("D://data/ml/lrmurder-sample.txt")
val sqc=new SQLContext(sc)
val r1=data.map { line =>
val lines=line.split(",")
val population=lines(0).toDouble//人口
val income=lines(1).toDouble//收入
val literacy=lines(2).toDouble//文盲程度
val lifeExp=lines(3).toDouble//生活经验
val hSGad=lines(5).toDouble//未知因素
val frost=lines(6).toDouble//温度
val area=lines(7).toDouble//地区
val murder=lines(4).toDouble//谋杀率
(population,income,literacy,lifeExp,hSGad,frost,area,murder)
}
//
val df1=sqc.createDataFrame(r1).toDF("population","income","literacy","lifeExp","hSGad","frost","area","murder")
//
val ass=new VectorAssembler().setInputCols(Array("population","income","literacy","lifeExp","hSGad","frost","area")).setOutputCol("features")
//
val df1Vectors=ass.transform(df1)
//
val model=new LinearRegression().setFeaturesCol("features")
.setLabelCol("murder")
.setFitIntercept(true)
.fit(df1Vectors)
// println(model.coefficients)
// println(model.intercept)
val predict=model.transform(df1Vectors)
// predict.show
val dataTest=sc.textFile("D://data/ml/lrmurder-test.txt")
val r2=dataTest.map { line =>
val lines=line.split(",")
val population=lines(0).toDouble//人口
val income=lines(1).toDouble//收入
val literacy=lines(2).toDouble//文盲程度
val lifeExp=lines(3).toDouble//生活经验
val hSGad=lines(5).toDouble//未知因素
val frost=lines(6).toDouble//温度
val area=lines(7).toDouble//地区
val murder=lines(4).toDouble//谋杀率
(population,income,literacy,lifeExp,hSGad,frost,area,murder)
}
val R2=model.summary.r2
println(R2)
val df1Test=sqc.createDataFrame(r2).toDF("population","income","literacy","lifeExp","hSGad","frost","area","murder")
//
val df1VectorsTest=ass.transform(df1Test)
//
val predictTest=model.transform(df1VectorsTest).select("prediction")
predictTest.show
//DataFrame- >RDD,便于结果的存储
val testPredictRDD=predictTest.toJavaRDD
//存储
testPredictRDD.saveAsTextFile("D://data/ml/lrmurder-result")
}
}
+----------+------+--------+-------+-----+-----+--------+------+--------------------+------------------+
|population|income|literacy|lifeExp|hSGad|frost| area|murder| features| prediction|
+----------+------+--------+-------+-----+-----+--------+------+--------------------+------------------+
| 3615.0|3624.0| 2.1| 69.05| 41.3| 20.0| 50708.0| 15.1|[3615.0,3624.0,2....|12.661154210276166|
| 365.0|6315.0| 1.5| 69.31| 66.7|152.0|566432.0| 11.3|[365.0,6315.0,1.5...|12.323375088838034|
| 2212.0|4530.0| 1.8| 70.55| 58.1| 15.0|113417.0| 7.8|[2212.0,4530.0,1....|10.109701326521787|
| 2110.0|3378.0| 1.9| 70.66| 39.9| 65.0| 51945.0| 10.1|[2110.0,3378.0,1....| 8.598800265183272|
| 21198.0|5114.0| 1.1| 71.71| 62.6| 20.0|156361.0| 10.3|[21198.0,5114.0,1...|10.900318436000305|
| 2541.0|4884.0| 0.7| 72.06| 63.9|166.0|103766.0| 6.8|[2541.0,4884.0,0....|3.6705232006178647|
| 3100.0|5348.0| 1.1| 72.48| 56.0|139.0| 4862.0| 3.1|[3100.0,5348.0,1....| 3.373379773351374|
| 579.0|4809.0| 0.9| 70.06| 54.6|103.0| 1982.0| 6.2|[579.0,4809.0,0.9...| 7.556150972388224|
| 8277.0|4815.0| 1.3| 70.66| 52.6| 11.0| 54090.0| 10.7|[8277.0,4815.0,1....|10.280592546850798|
| 4931.0|4091.0| 2.0| 68.54| 40.6| 60.0| 58073.0| 13.9|[4931.0,4091.0,2....|13.025062575661806|
| 868.0|4963.0| 1.9| 73.6| 61.9| 0.0| 6425.0| 6.2|[868.0,4963.0,1.9...| 4.328961788127188|
| 813.0|4119.0| 0.6| 71.87| 59.5|126.0| 82677.0| 5.3|[813.0,4119.0,0.6...| 4.187959497376227|
| 11197.0|5107.0| 0.9| 70.14| 52.6|127.0| 55748.0| 10.3|[11197.0,5107.0,0...| 9.127752949391294|
| 5313.0|4458.0| 0.7| 70.88| 52.9|122.0| 36097.0| 7.1|[5313.0,4458.0,0....| 6.586970761195687|
| 2861.0|4628.0| 0.5| 72.56| 59.0|140.0| 55941.0| 2.3|[2861.0,4628.0,0....|2.8899870658698745|
| 2280.0|4669.0| 0.6| 72.58| 59.9|114.0| 81787.0| 4.5|[2280.0,4669.0,0....| 3.521573660023023|
| 3387.0|3712.0| 1.6| 70.1| 38.5| 95.0| 39650.0| 10.6|[3387.0,3712.0,1....| 8.924456244647345|
| 3806.0|3545.0| 2.8| 68.76| 42.2| 12.0| 44930.0| 13.2|[3806.0,3545.0,2....|13.855588883204646|
| 1058.0|3694.0| 0.7| 70.39| 54.7|161.0| 30920.0| 2.7|[1058.0,3694.0,0....| 5.795916596181428|
| 4122.0|5299.0| 0.9| 70.22| 52.3|101.0| 9891.0| 8.5|[4122.0,5299.0,0....| 8.057526919842786|
+----------+------+--------+-------+-----+-----+--------+------+--------------------+------------------+
only showing top 20 rows
[12.169935772989035]
[12.274253245109321]
[9.782222368330366]
[8.271321306991851]
[7.625528854086099]
[3.343044242426444]
[2.882161336064243]
[7.4742812328403545]
[8.970676714085116]
[12.370104659278965]
[4.328961788127188]
[4.187959497376227]
[9.127752949391294]
[6.586970761195687]
[2.8899870658698745]
[3.521573660023023]
[8.924456244647345]
[13.855588883204646]
[5.795916596181428]
[8.057526919842786]
[5.531271883216988]
[7.932640181298581]
[2.2523969399666157]
[13.656612163793028]
[7.412430257317979]
[6.330639463084481]
[2.8250273413751046]
[8.02827295469578]
[3.97631722588973]
[7.182188605394742]
[9.441061322564934]
[43.49379230754059]
[11.331046335330257]
[1.7554029085789153]
[7.66729675100099]
[6.500445760137936]
[5.750507525521442]
[8.685649075969067]
[4.357022766232987]
[13.587001688520786]
[2.856947233597694]
[9.598065171504004]
[12.16345501615838]














 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









