






一、Hadoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,开发分布式程序。Hadoop充分利用集群的威力进行高速运算和存储,是大数据处理领域的核心框架之一。
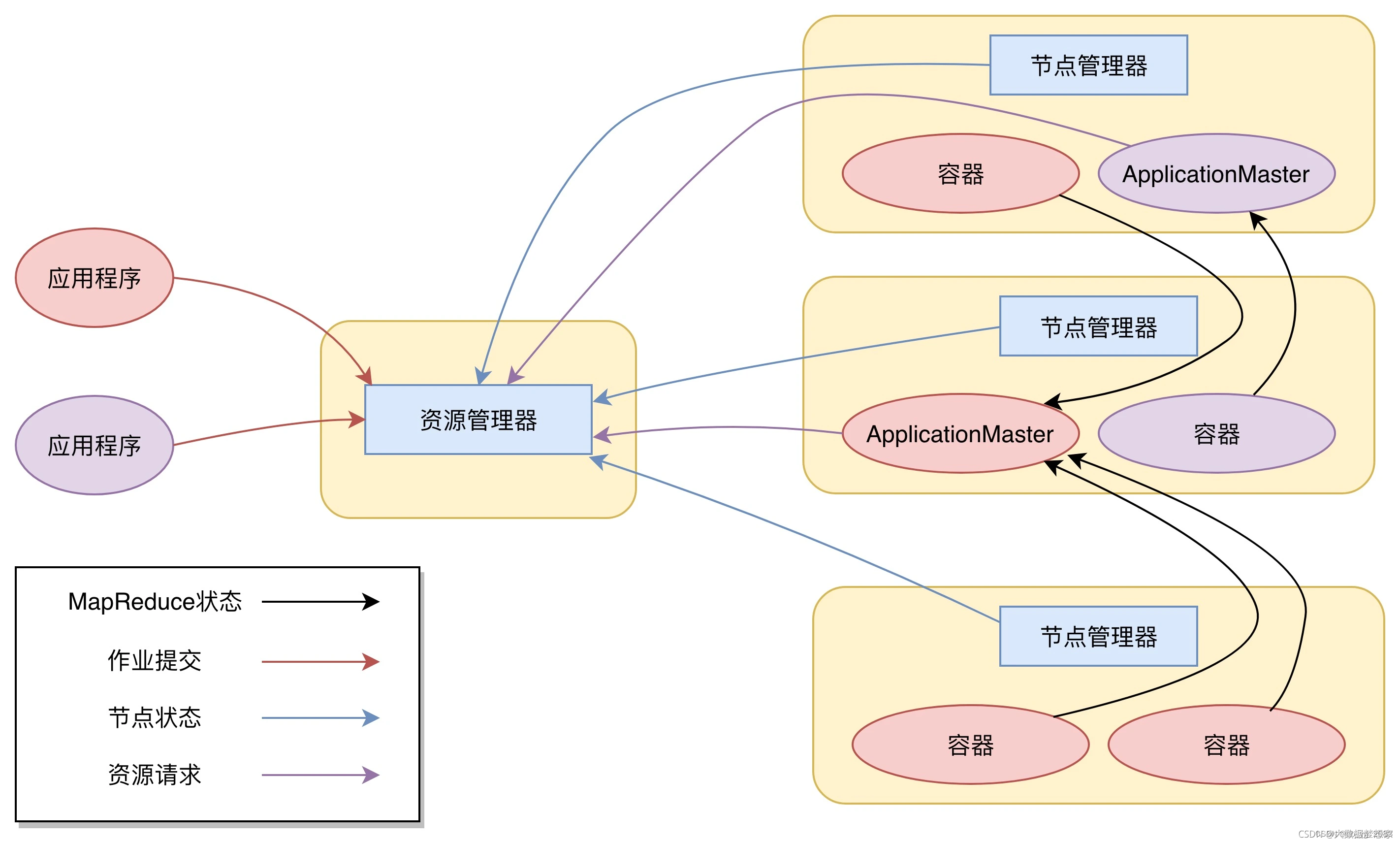
Hadoop主要包括两个核心组件:HDFS(Hadoop Distributed File System)和MapReduce。HDFS是Hadoop的分布式文件系统,具有高容错性,并设计用来部署在低廉的硬件上,以提供高吞吐量的数据访问,非常适合处理超大数据集。MapReduce则是Hadoop的分布式数据处理框架,支持大规模数据集的并行运算。
Hadoop的特点包括高可靠性、高拓展性、高效性、高容错性、低成本等。它底层维持多个副本,即使Hadoop某个计算元素或存储出现故障,也不会导致数据丢失。同时,Hadoop可以在集群间分配任务数据,方便地拓展数以千计的节点。在MapReduce的思想下,Hadoop可以并行工作,以加快任务处理速度。
Hadoop在大数据处理、数据仓库、云计算等领域有着广泛的应用。它可以处理包括结构化、半结构化和非结构化在内的各种类型的数据,为各种大数据应用提供了强大的支持。同时,Hadoop也与其他大数据技术和工具进行了良好的集成,形成了庞大的Hadoop生态圈,为大数据的处理和分析提供了更全面的解决方案。
二、Hadoop基础操作
2.1认识Hadoop安全模式
Hadoop的安全模式是一种特殊的状态,主要用于在Hadoop集群启动时保护数据和集群免受未经授权的访问。在安全模式下,Hadoop文件系统(HDFS)仅接受读数据请求,而不接受删除、修改等变更请求。这一设计主要是为了在系统启动时检查各个DataNode上数据块的有效性,并根据策略进行必要的复制或删除部分数据块。
Hadoop的安全模式包括认证、授权和数据加密等功能。它使用Kerberos认证协议来验证用户的身份,并通过访问控制列表(ACL)来授权用户对文件和目录的访问。用户必须首先通过Kerberos认证获取有效的令牌,然后才能执行Hadoop命令。这个令牌用于验证用户的身份,只有在身份验证成功后,用户才能访问受保护的资源。
此外,Hadoop的安全模式还允许管理员配置Kerberos领域和Keytab文件等必要的参数,以进一步增强集群的安全性。当系统满足一些条件时,例如所有的DataNode都成功启动并且数据块达到最小的副本数量要求,Hadoop集群会自动离开安全模式,此时用户可以执行各种数据操作。
2.2查看解除和开启Hadoop安全模式
2.2.1查看Hadoop安全模式
- 登录到Hadoop集群的主节点或管理节点。
- 打开终端窗口,输入以下命令以查看Hadoop是否处于安全模式:
hdfs dfsadmin -safemode get。如果返回结果为“Safe mode is ON”,则表示Hadoop集群当前处于安全模式。
2.2.2解除Hadoop安全模式
如果Hadoop集群处于安全模式,并且您需要进行写操作,那么您需要解除安全模式。可以使用以下步骤:
- 确保所有DataNode都已经正常启动并加入到集群中。
- 确保HDFS中的文件块满足最小副本数的要求。
- 在终端窗口中输入以下命令以退出安全模式:
hdfs dfsadmin -safemode leave。等待一段时间后,Hadoop集群应该就会退出安全模式。
2.2.3开启Hadoop安全模式
在某些情况下,您可能希望主动将Hadoop集群置于安全模式,例如在进行系统维护或数据迁移时。您可以使用以下步骤开启安全模式:
- 在终端窗口中输入以下命令以进入安全模式:
hdfs dfsadmin -safemode enter。 - 等待一段时间,直到Hadoop集群成功进入安全模式。您可以使用
hdfs dfsadmin -safemode get命令来检查是否成功进入安全模式。
三、上传文件到HDFS目录
3.1了解HDFS
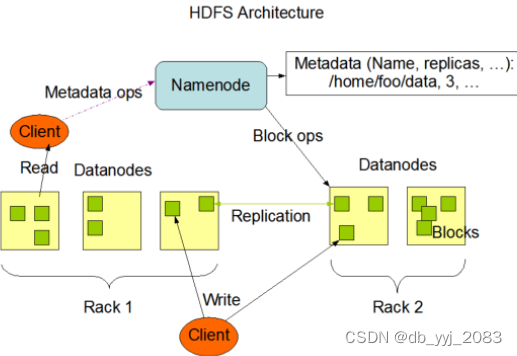
HDFS(Hadoop Distributed File System)是Hadoop项目的核心组件之一,被设计成适合运行在通用硬件上的分布式文件系统。它与其他分布式文件系统有许多共同点,但也有很多独特之处。
HDFS的主要特性包括:
- 海量数据存储:HDFS可以横向扩展,支持PB级别或更高级别的数据存储,因此非常适合处理超大数据集。
- 高容错性:HDFS的数据保存多个副本,当某个副本丢失后,系统会自动恢复,从而保证了数据的高可用性。此外,HDFS可以构建在廉价的机器上,实现线性扩展。当集群增加新节点后,系统可以进行负载均衡,将数据分发和备份数据均衡到新的节点上。
- 商用硬件:HDFS并不需要运行在昂贵且高可靠的硬件上,而是设计运行在商用硬件(廉价商业硬件)的集群上。
- 流式数据访问:HDFS放宽了POSIX的要求,可以实现流的形式访问文件系统中的数据,这对于大数据处理非常有利。
然而,HDFS也有一些局限性,例如它不能做到低延迟数据访问,因为Hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟访问数据的业务需求不适合HDFS。
HDFS的基本架构主要包括NameNode、DataNode和Secondary NameNode等组件。NameNode负责管理文件系统的元数据,DataNode负责存储实际的数据块,而Secondary NameNode则辅助NameNode进行工作,如定期合并fsimage和edits,并推送给NameNode。
3.2HDFS的基本操作
文件上传:
使用hadoop fs -put命令可以将本地文件或目录上传到HDFS中。例如:
hadoop fs -put localfile.txt /user/hadoop/hdfsdir将本地文件localfile.txt上传到HDFS的/user/hadoop/hdfsdir目录下。
文件下载:
使用hadoop fs -get命令可以将HDFS中的文件或目录下载到本地。例如:
hadoop fs -get /user/hadoop/hdfsdir/localfile.txt ./localdir将HDFS中/user/hadoop/hdfsdir目录下的localfile.txt文件下载到本地的localdir目录中。
文件查看:
使用hadoop fs -ls命令可以查看HDFS目录中的文件和子目录列表。例如:
hadoop fs -ls /user/hadoop/hdfsdir将列出/user/hadoop/hdfsdir目录下的所有文件和子目录。
文件删除:
使用hadoop fs -rm命令可以删除HDFS中的文件或目录。例如:
hadoop fs -rm /user/hadoop/hdfsdir/localfile.txt这将删除HDFS中/user/hadoop/hdfsdir目录下的localfile.txt文件。如果需要删除目录及其内容,可以使用-r选项:
hadoop fs -rm -r /user/hadoop/hdfsdir将递归删除/user/hadoop/hdfsdir目录及其所有内容。
文件重命名:
使用hadoop fs -mv命令可以重命名HDFS中的文件或目录。例如:
hadoop fs -mv /user/hadoop/hdfsdir/oldname.txt /user/hadoop/hdfsdir/newname.txt将把/user/hadoop/hdfsdir目录下的oldname.txt文件重命名为newname.txt。
文件权限管理:
可以使用hadoop fs -chmod命令来更改HDFS文件或目录的权限,类似于Unix的chmod命令。
创建目录:
使用hadoop fs -mkdir命令可以在HDFS中创建新目录。例如:
hadoop fs -mkdir /user/hadoop/newdir将在HDFS中创建/user/hadoop/newdir目录。
-
查看文件内容:
可以使用hadoop fs -cat命令查看HDFS中文件的内容。
注意:执行这些操作通常需要相应的权限,并且需要确保HDFS集群是可用的。
四、运行首个MapReduce任务
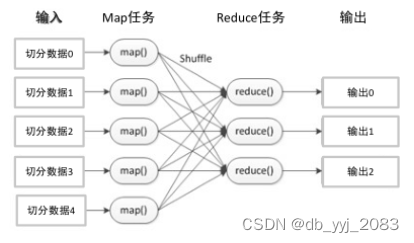
- 编写MapReduce程序:
- 首先,你需要编写MapReduce程序。这通常包括编写一个Mapper类,一个Reducer类,以及可能需要的其他辅助类。
- 确保你的程序已经编译并打包成一个JAR文件。
- 准备输入数据:
- 将输入数据上传到HDFS中。Hadoop MapReduce任务从HDFS读取输入数据。
- 确保输入数据的格式和结构与你的MapReduce程序相匹配。
- 配置作业参数:
- 设置作业的配置参数,如输入和输出路径、Mapper和Reducer类、以及其他MapReduce相关的配置。
- 这些配置通常在Java代码中通过
Configuration对象进行设置,或者通过命令行参数传递。
- 提交作业到集群:
- 使用Hadoop提供的命令行工具(如
hadoop jar)或API来提交作业到集群。 - 命令行示例:
hadoop jar your-mapreduce-job.jar com.example.YourMapReduceClass -Dmapreduce.job.queuename=your-queue -Dmapred.job.mapper.class=com.example.YourMapper -Dmapred.job.reducer.class=com.example.YourReducer -Dmapred.input.dir=/path/to/input -Dmapred.output.dir=/path/to/output - 在这个例子中,
your-mapreduce-job.jar是你的MapReduce程序的JAR文件,com.example.YourMapReduceClass是包含main方法的类,用于启动MapReduce作业。-D参数用于设置各种作业配置。
- 使用Hadoop提供的命令行工具(如
- 监控作业执行:
- 提交作业后,你可以使用Hadoop提供的Web界面(通常是YARN ResourceManager UI或MapReduce JobHistory UI)来监控作业的执行状态。
- 这些界面会显示作业的进度、状态、失败原因等信息。
- 查看输出结果:
- 一旦作业执行完成,你可以在HDFS中查看输出结果。
- 输出结果通常存储在你在作业配置中指定的输出路径下。
五、管理多个MapReduce任务
- 任务提交:
- 使用Hadoop命令行工具或API批量提交MapReduce任务。
- 为每个任务配置适当的输入和输出路径、Mapper和Reducer类以及其他相关参数。
- 任务监控:
- 利用Hadoop提供的Web界面(如YARN ResourceManager UI或MapReduce JobHistory UI)来查看任务的实时状态、进度和日志。
- 可以使用命令行工具(如
yarn application --list)列出正在运行或已完成的任务。
- 任务调度与资源分配:
- 根据集群的资源和任务的需求,合理配置任务的优先级、队列和资源需求。
- 利用Hadoop的调度器(如Capacity Scheduler或Fair Scheduler)来管理任务的调度和资源分配。
- 错误处理与日志分析:
- 定期检查任务的日志,以便及时发现和处理错误。
- 对于失败的任务,分析错误原因并进行修复,然后重新提交任务。
- 任务依赖与并行处理:
- 如果任务之间存在依赖关系,确保按照正确的顺序提交任务。
- 利用Hadoop的并行处理能力,同时运行多个独立的任务以加速数据处理。
- 使用高级管理工具:
- 考虑使用高级管理工具或框架(如Apache Oozie、Apache Airflow等),它们提供了更强大的任务调度、依赖管理和监控功能。
- 优化与性能调整:
- 根据任务的性能和资源使用情况,调整MapReduce作业的配置参数,如内存分配、并行度等。
- 定期对集群进行维护和优化,以确保其能够高效地处理多个MapReduce任务。















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









