









题意
小明对数学饱有兴趣,并且是个勤奋好学的学生,总是在课后留在教室向老师请教一些问题。一天他早晨骑车去上课,路上见到一个老伯正在修剪花花草草,顿时想到了一个有关修剪花卉的问题。于是当日课后,小明就向老师提出了这个问题:
一株奇怪的花卉,上面共连有 N 朵花,共有 N−1 条枝干将花儿连在一起,并且未修剪时每朵花都不是孤立的。每朵花都有一个“美丽指数”,该数越大说明这朵花越漂亮,也有“美丽指数”为负数的,说明这朵花看着都让人不舒服。所谓“修剪”,意为:去掉其中的一条枝条,这样一株花就成了两株,扔掉其中一株。经过一系列“修剪“之后,还剩下最后一株花(也可能是一朵)。老师的任务就是:通过一系列“修剪”(也可以什么“修剪”都不进行),使剩下的那株(那朵)花卉上所有花朵的“美丽指数”之和最大。
老师想了一会儿,给出了正解。小明见问题被轻易攻破,相当不爽,于是又拿来问你。
输入格式
第一行一个整数 N (1≤N≤16000),表示原始的那株花卉上共 N 朵花。
第二行有 N 个整数,第 i 个整数 ai (−104≤ai≤104)表示第 i 朵花的美丽指数。
接下来 N−1 行每行两个整数 a,b,表示存在一条连接第 a 朵花和第 b 朵花的枝条。
输出格式
一个数,表示一系列“修剪”之后所能得到的“美丽指数”之和的最大值。
解析
树上问题往往从根结点开始,由子树逐渐往上更新到整棵树。
这里我们不妨先设 11 为根。设 dp[u] 表示以 u 为根的子树在保留 u 节点的情况下完成“修剪“后”美丽指数”之和最大是多少。
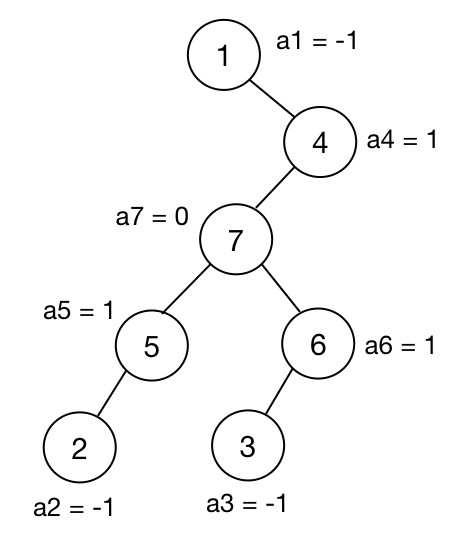
转移时我们发现如果对于 u 的子节点 v,有 dp[v]>0,那么 (u,v) 这条边就不该剪,所以状态转移方程为:
dp[u]=a[u]+∑dp[v]>0dp[v]我们找到 dp 数组的最大值即可。
#include <cstring>
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
const int inf = 0x3f3f3f3f;
const int maxn = 16010;
vector <int> G[maxn];
int a[maxn], dp[maxn];
void addedge(int u, int v) {
G[u].push_back(v);
}
int dfs(int u, int fa) {
dp[u] = a[u];
for(int i = 0; i < G[u].size(); i++){
int v = G[u][i];
if (v != fa && dfs(v, u) > 0){
dp[u] += dp[v];
}
}
return dp[u];
}
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> a[i];
}
for (int i = 0; i < n - 1; i++) {
int u, v;
cin >> u >> v;
addedge(u, v);
addedge(v, u);
}
dfs(1, 0);
int ans = -inf;
for(int i = 1; i <= n ;i++){
ans = max(ans, dp[i]);
}
cout << ans << endl;
return 0;
} 


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









