




目录
获客的本质:是根据自己的产品、服务和业务模型确定潜在的用户。
| 阶段 | 任务 | 关键指标 |
| 获客阶段 | 通过手段提高产品曝光,提高产品知名度 | 流量、CAC、CTR |
第一话、用户画像揭示秘密
根据业务需求,对用户统计特征、社会属性和标签进行提炼。包括用户基本信息+用户行为
1.1 用户画像
在做用户画像之前,需要先了解用户
- 静态属性:性别、年龄、居住地
- 动态属性:上次登录日期、消费次数、月消费金额
- 心理属性:兴趣爱好、付费方式
1.2 分析工具python
- Numpy+Pandas:数据计算和数据分析
- Matplotlib+Serborn:数据可视化
- scikit-learn:机器学习
- SciPy:科学计算
- TensorFlow+PyTorch+Keras:深度学习框架
1.3 python语法
1.3.1 数组操作numpy
1)创建numpy数组
import numpy as py
npArray = np.array([1,2,3,4,5])
npArray2 = np.array([[1,2,3],[4,5,6])
npArray3 = np.arange(0,5,1)
nPArray4 = np.linspace(0,1,5)
npArray5 = np.random.rand(3,2,2)2)索引访问数组
np.Array5[2,1,1]3)对数组进行切片
# 选择第二行的前三个元素
npArray2[1,0:3]
# 选择第四列元素
npArray[:,3]1.3.2 数组操作pandas
1)创建DataFrame
# 1)通过列表创建
data = [[111,110,100],
[78,87,95],
[100,95,75]]
index = ["张三","李四","王五"]
columns = ["语文","数学","英语"]
df = pd.DataFrame(data=data, index=index, columns=columns)
# 2)通过字典创建
df2 = pd.DataFrame(
{'语文':[111,110,100],
'数学':[78,87,95],
'英语':[100,95,75]}, index=['张三','李四','王五']
)
# 3)通过Series创建
data = {'语文':pd.Series([111,110,100],['张三','李四','王五']),
'数学':pd.Series([78,87,95],['张三','李四','王五']),
'英语':pd.Series([100,95,75],['张三','李四','王五'])
}
df3 = pd.DataFrame(data)
2)DataFrame属性和方法
df.shape # 数据集形状
df.index # 行索引
df.columns # 列索引
df.describe() # 数值列描述
df['user_id'].value_counts() # 字段计数
df.sort_value(by='年龄',ascending=False) # 排序
# 求“年收入”大于3万元的女生中“年消费”字段的最大值。
df[(df['性别']=='女') & (df['年收入']>=30000)]['年消费'].max()
3)选择数据
如果行索引是数值类型,那么行索引=行序号,loc也可以用序列号指定
# 通过行索引名或序列号选择数据
# loc()行名;iloc()序列号
df.iloc[[0,1,2]]
df.loc[['用户01','用户02']]
如果行索引是数值类型,那么行索引=行序号,loc也可以用序列号指定切片数据范围不同:
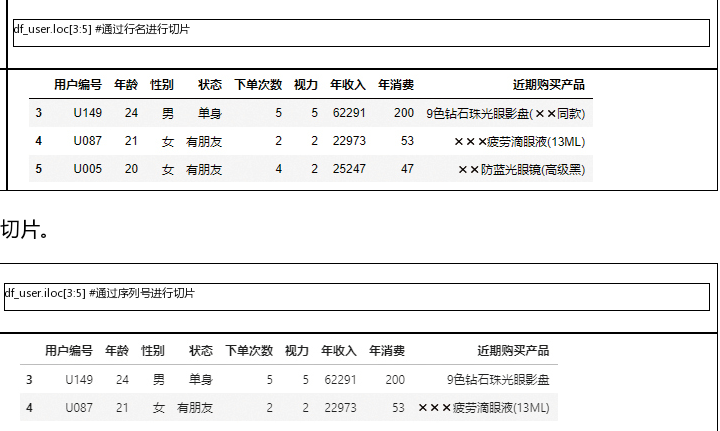
# 同样的,loc用于列索引名,iloc用于列序号
df.loc[:,['用户编号','年龄']]
df.iloc[:,0:2]
# 同时选择行列
df.loc[0:2, ['用户编号','年龄']]
# 加上筛选条件
df.loc[df['年收入']>10000, '用户编号':'年收入']4)分组
df.groupby(['性别'])['年收入'].mean()5)数据透视表
df.pivot_table(['年收入','年消费'],['视力'],aggfunc='mean')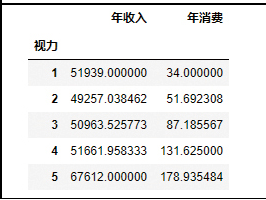
1.3.3 数据可视化
1)Matplotlib
特殊代码
# 特殊代码
%matplotlib inline #用于在笔记本内联显示matplotlib图表
%config InlineBackend.figure_format = 'svg' #确保图表以SVG格式显示
plt.rcParams["font.sans-serif"] = 'Microsoft YaHei' #解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False #解决负号无法显示图表样式设置和画布
# 设置图表样式
plt.style.use('ggplot')
# 设置画布大小
plt.figure(figsize=(10,6))基本元素设置
# 坐标轴标题
plt.xlabel()
plt.ylabel()
# 图表标题
plt.title(label, fontsize, color, loc, pad, fontweight)
# 图例
plt.legend()
# 轴显示设置 —— 设置坐标轴范围
plt.axis(option)基本图表设置
# 点、线设置
df.plot()
# 坐标轴刻度
plt.xticks(ticks, labels, rotation, fontsize, color)
plt.yticks(ticks, labels, rotation, fontsize, color)
# 坐标轴范围
plt.xlim(1,100)
plt.ylim(1,100)
# 网格线
plt.grip()
如何选择图表?
- 折线图——plt.plot
- 柱状图——plt.bar
- 散点图——plt.scatter
- 饼图——plt.pie
- 条形图——plt.barh
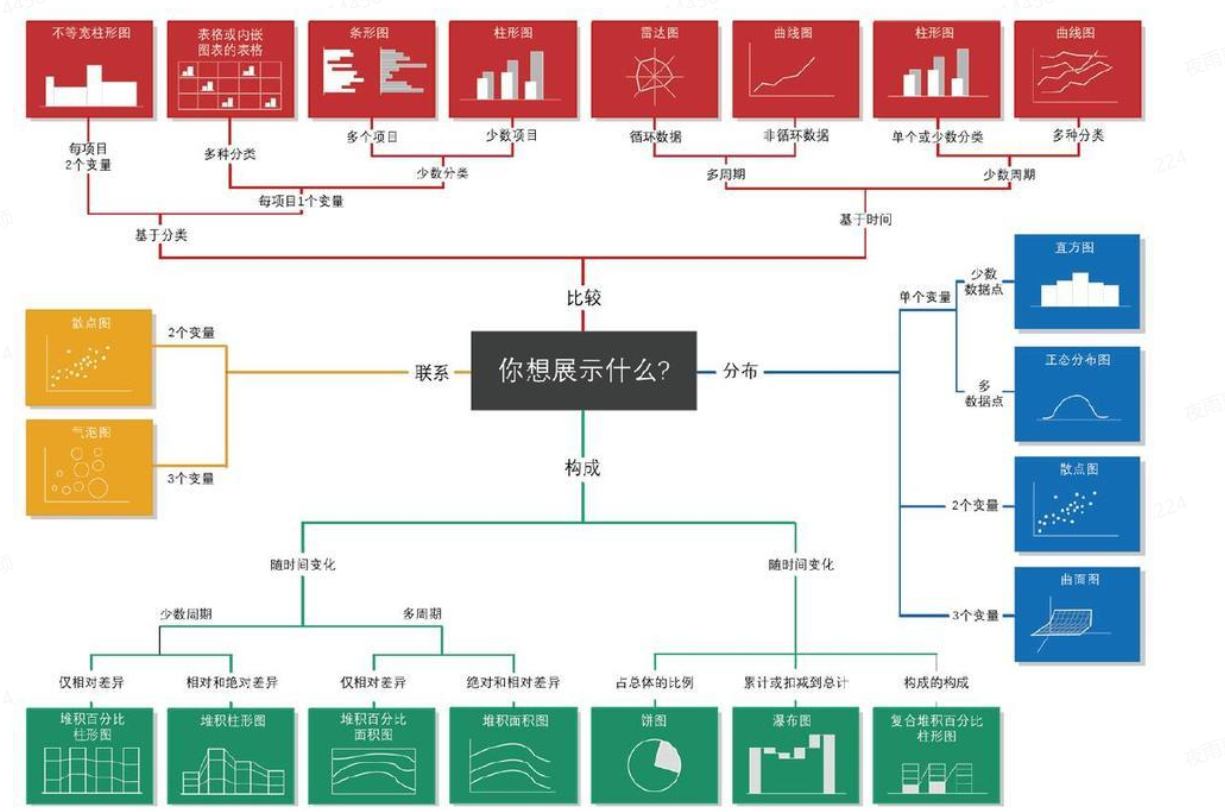
2)Seaborn
import seaborn as sns
tips = sns.load_dataset("tips") # 导入数据集
sns.lmplot(x='total_bill',y='tip',hue='smoker',data=tips) # 含线性回归模型的散点图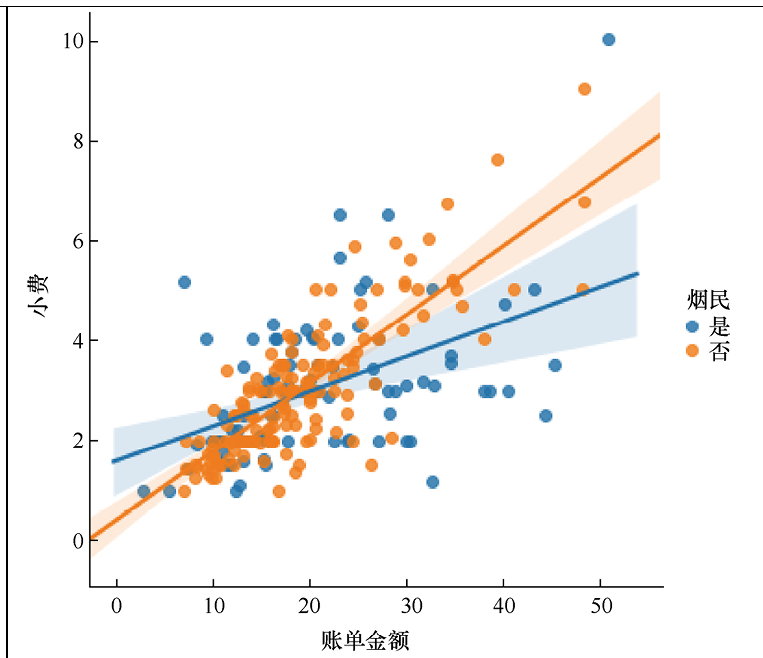
sns.countplot(x,data) # 绘制的子计数图是跨分类变量的直方图3)特殊代码
crosstab():
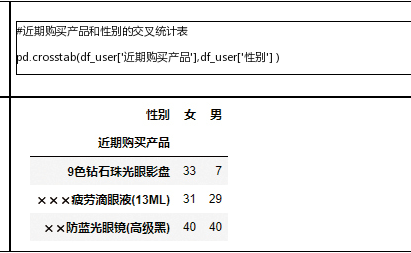
sns.displot() 分布直方图(带核密度估计曲线)
第一话总结:根据具有不同特点的用户群体设计并推出不同版本的推广方案。
第二话、聚类实现RFM细分
2.1 问题:如何通过细分用户指导运营
基于历史数据,通过用户的特征和行为数据对用户进行细分,从而了解用户,有的放矢的促销用户获客、用户管理等活动。
2.2 用户细分
2.2.1 用户画像
获客三部曲:
1)了解自己的产品和内容
2)了解用户的属性和消费习惯
3)产品和用户匹配,选择合适的获客策略
2.2.2 用户行为数据指导精细化运营
记录用户行为》》发现用户真正想要的内容/对哪些内容不满意》》分析出用户痛点》》将产品与市场进行更好的匹配
2.2.3 进行同期群分析揭示获客时的秘密
一种常见的分组方法是把同一时间段内新注册的用户群体视为同期群
形成同期群》》追踪一段时间后的活跃程度,留存率和流失率》》推出用户的粘性、忠诚度,评价获客,促销工作的效率
通过对比思维,看不同月份的留存率,进而评估获客手段或促销方式
2.2.4 根据特征和价值进行用户分组
- 按区域划分:不同城市、不同国家
- 按行业,背景和个人爱好划分
- 按注册来源:自然注册、付费推广、老用户推荐
- 按设备类型划分、付款方式等划分
2.3 工具:RFM分析和聚类算法
R——最近一次消费时间;(提高用户粘性)
F——消费频次;(提高消费频率)
M——消费总金额;(与F结合找准优质用户,分配资源)
聚类:就是一种机器学习算法,让机器将数据集中的样本按照特征分组,这个过程没有标签的存在,因此是无监督学习。(通过特征将数据进行聚类)
标签是指在机器学习的数据集中,只有一个标签字段,就是监督学习要预测的字段
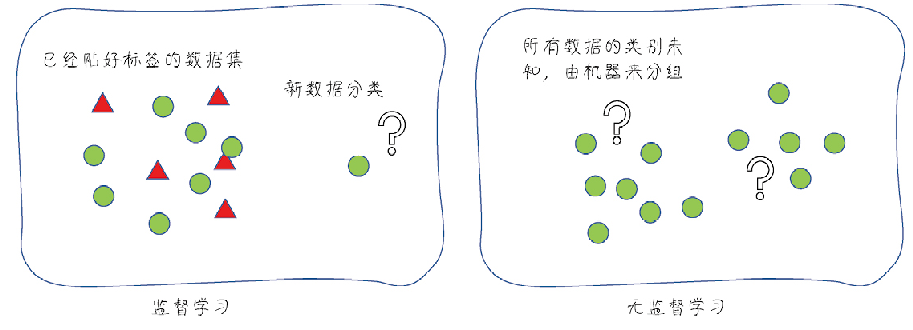
2.3.1 监督学习和无监督学习
监督学习:数据集中存在的标签(例如高价值用户),即我们要预测的结果字段,其他的字段称为特征(RFM值、层级),机器学习就是通过对特征的学习,找出能够正确预测标签的模型的过程。
无监督学习:数据集中并没有一个字段指明了用户价值。把这个数据集输入机器,让机器在没有标签做指导的情况下自动将这些用户分组。这就是一个典型的无监督学习过程
算法:指宏观上的工具、方法,如聚类、神经网络;
模型:是指算法对具体数据集拟合之后的成品。
2.3.2 K-means算法是常见的聚类算法
第一步:指定K的数值;
第二步:在数据集随机挑选K个数据做质心;
第三步:遍历数据点,计算与每一个质心距离,然后归类到最近的簇;
第四步:聚集数据点之后,重新计算质心;
之后重复第三步,第四步... 直到质心收敛完成,簇形成。
2.3.3 通过手肘法确定K值
2.4 实战:基于RFM模型的用户细分
2.4.1 思路
第一步:进行数据清洗和可视化工作,通过聚类算法,从RFM三个维度进行分组;
第二步:每一个具体维度,都要
- 输出分布直方图
- 通过手肘法确认K值
- 根据K值进行聚类
- 确认每位客户的簇(用户层)
第三步:将三个维度进行汇总,确定最终客户所处的层级
2.4.2 数据导入与可视化
2.4.3 根据R值为用户新近度分层
1、构建用户层级表
2、加入特征值
3、输出特征值的直方图
4、导入聚类模块
5、定义手肘函数

6、根据K=3值进行聚类拟合,求出层级
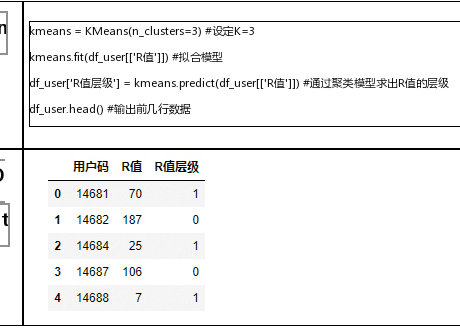
7、给无意义的聚类结果排序

2.4.4 根据F值为用户消费频率分层(重复上述步骤)
2.4.5 根据M值为用户消费金额分层(重复上述步骤)
2.4.6 汇总3个维度,确定用户价值分层
注意,在df_user对象中添加字段总分
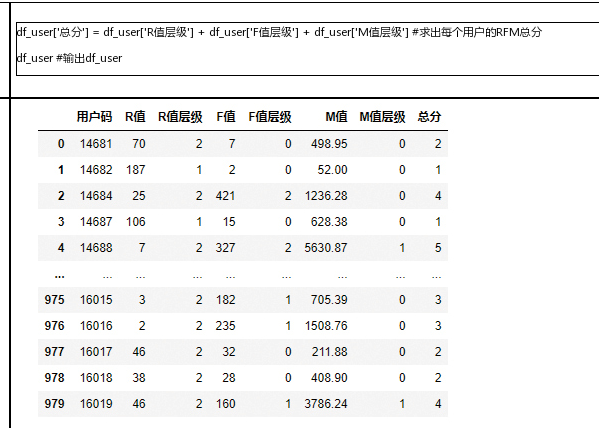
在df_user对象中添加“总体价值”字段
绘图

第三话、回归预测用户LTV
数据时代,流量是影响增长的重要因素,因此需要核算获客成本。用户生命周期价值LTV是否可以覆盖成本。衡量投入产出比ROI
通过监督学习中的回归预测用户LTV,以此估算获客成本
3.1 能从用户身上赚多少钱?
ROI = LTV/CAC
通过现有数据找到一个模型预测出,用户的生命周期价值,指导获客成本的多少才能盈利。
3.2 用户生命周期价值
投资回报率 = 用户终身价值÷获客成本
考虑获客成本的时候,不要简单地认为增长就是好的,甚至盲目拉新。要考虑生命周期价值能不能超越获客成本。
估算用户的LTV:一种实用的方法是通过机器学习中的回归模型来预测
3.3 工具:回归分析
3.3.1 机器学习中的回归分析
基本的回归是线性回归,通过线性函数对变量间的定量关系进行统计分析。
y=ax+b 简单的一元线性回归
y= ax1+ bx2+ … + n 多元线性回归
3.3.2 训练集、验证集和测试集
1)机器学习实战一般的五个流程:
- 问题定义
- 数据的收集和预处理
- 机器学习模型的选择
- 训练机器,确定参数
- 超参数调试和性能优化
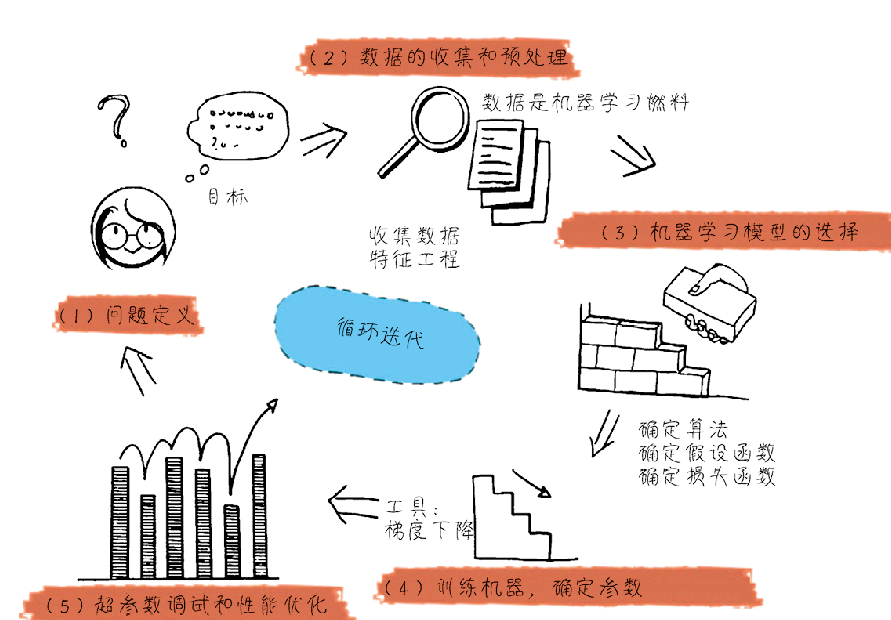
1)用训练集让机器“学”知识,拟合数据集中特征和标签之间的关系,形成初步的模型;
2)用验证集做“课后小测验”,看看得到的模型好不好,如果模型不能够很好地应用于验证集就接着用其做测验;
3)用测试集做“期末大考”,评估训练集和验证集都可用的模型的最终效果,如果效果不好,还要重新训练模型
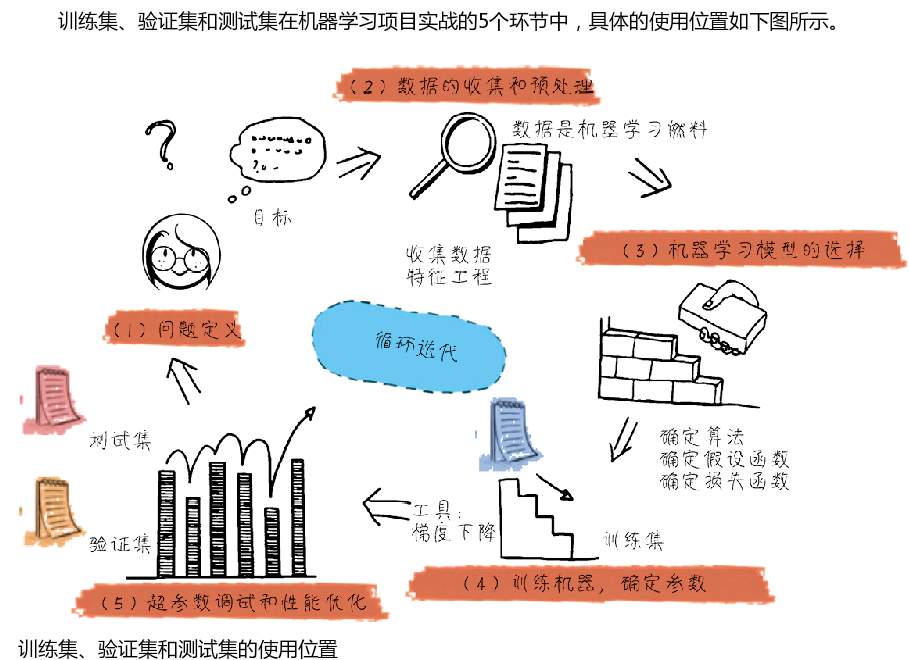
2)如何拆分训练集、验证集、测试集
- 对于小规模样本(几万),训练集60%——验证集20%——测试集20%
- 对于大规模样本(百万级),验证集和测试集中的数据数量足够,1万条验证集和测试集就够
- 如果超参数少,或者超参数容易调整,那么可以降低验证集数据的比例,将更多的数据分配给训练集
3)k 折交叉验证——动态划分验证集步骤
- 随机清洗数据,区分训练集和测试集
- 将训练集分成K组
- 选择其中一组作为验证集,剩下的做训练集,重复k次;
- 在训练集中拟合模型并在测试集中对其评估;
- 丢弃模型,但保留评估分和超参数;
- 通过k次训练,得到k个不同的模型
- 评估k个模型的效果,从中挑选效果最好的模型的超参数
- 使用最优的超参数将k组数据作为训练集重新训练,得到最终模型
- 使用测试集评估最终模型的分数
注意:k值的选择很重要。如果选择不好,可能导致方差过大或偏差过大。
数据量小的时候,可以设置较大k值;数据量大的时候,可以设置较小k值。一般k=10
3.3.3 如何将预测的损失最小化
如何评估模型的好坏——损失,即误差
针对所有样本,找到一组平均损失较小的模型。即预测值与真实值的几何距离大小。
针对每一组不同的参数,机器都会基于样本数据集用损失函数计算一次平均损失,而机器学习的最优化过程就是逐步减小训练集损失的过程。
回归模型的拟合,关键环节就是通过梯度下降逐步优化模型的参数,使训练集的误差值尽量达到最小误差值
线性回归中的误差计算方法是求数据集中真实值与预测值之间的残差平方和;
梯度下降:是在用训练集拟合模型时将误差最小化,此时调整的是模型内部参数

















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









