






ICCV 是首屈一指的国际计算机视觉盛会,由主会议和多个同期举办的研讨会和教程组成。
2023年的ICCV于23年10.4-10.6在巴黎举行,总共有 1,000 多篇论文被提交,今天学长给大家精选了 ICCV 2023 排名前10篇论文,并对每篇论文的精华部分进行了总结翻译。
这10篇论文分别是
【1】DEVA: Tracking Anything with Decoupled Video Segmentation
DEVA:通过解耦视频分割跟踪任何内容
【2】Effective Whole-body Pose Estimation with Two-stages Distillation
两阶段知识蒸馏的有效全身姿态估计
【3】EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
EfficientViT:用于高分辨率密集预测的多尺度线性注意力
【4】FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT:使用结构化重新参数化的快速混合视觉Transformer
【5】LightGlue: Local Feature Matching at Light Speed
以光速进行局部特征匹配
【6】ProPainter: Improving Propagation and Transformer for Video Inpainting
ProPainter:改进传播和Transformer以实现视频修复
【7】Segment Anything
任意分割
【8】Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
Text2Room:从 2D 文本到图像模型中提取带纹理的 3D 网格
【9】Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
Text2Video-Zero:文本到图像的扩散模型是零样本视频生成器
【10】ViperGPT: Visual Inference via Python Execution for Reasoning
ViperGPT:通过Python进行视觉推理
计算机视觉可复现论文合集!!!![]() https://www.bilibili.com/opus/1057395247213969429?spm_id_from=333.1387.0.0
https://www.bilibili.com/opus/1057395247213969429?spm_id_from=333.1387.0.0
DEVA: Tracking Anything with Decoupled Video Segmentation
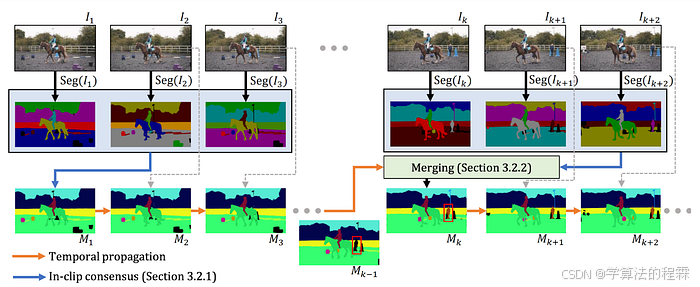
总结:DEVA 将 Segment Anything(见下文)扩展到视频,以实现开放世界的视频分割
在传统方法里,训练视频分割模型是一项耗时且成本高昂的任务。
这在很大程度上是由于端到端视频分割模型需要密集注释的视频数据,这意味着需要为每一帧进行分割掩码。
虽然这并没有证明对特定的视频分割任务具有抑制作用,但这意味着需要对每个所需的任务进行等效的努力。
换句话说,花费在密集注释视频对象分割数据集上的时间不会转化为视频全景分割任务,这需要其自己的注释。
去耦合视频分割通过将视频分割分为两个步骤来翻转脚本,第一步是特定任务的图像级分割任务,第二步是任务无关的双向时间传播。
简单来说,就是你拿一个图像分割模型并将其应用于视频中的帧。接着来自不同帧的“假设”分割掩模会用连贯的方式融合。
这个时间传播模块只需要训练一次,然后可以与任何图像分割模型结合使用——甚至是像 Segment Anything 这样的开放词汇模型!
两阶段知识蒸馏的有效全身姿态估计
Effective Whole-body Pose Estimation with Two-stages Distillation
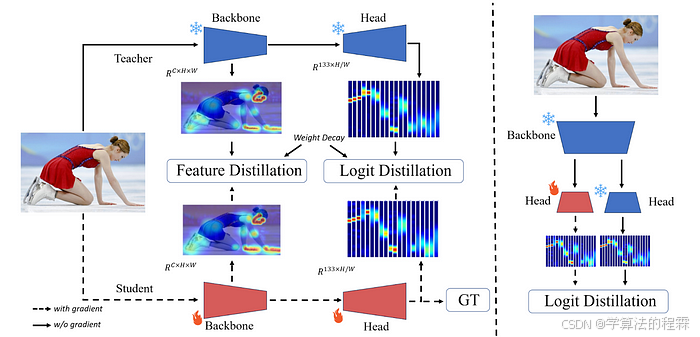
总结:最先进的 2D 人体姿势估计
姿态估计是指识别、定位和定向人体上各个关键点的任务。该任务的“全身”变体涉及从头到脚同时检测和定位关键点,是许多下游计算机视觉应用的关键组成部分,从合成运动生成到虚拟或增强现实环境中的人体跟踪。
虽然存在像RTMPose这样非常精确的全身姿势估计,但该领域目前面临的挑战之一是在更低的延迟下实现类似的精度水平。
在这篇论文中,作者提出了用于全身姿势估计的两阶段知识蒸馏方法DWPose。
首先,学生模型从更大的教师模型中学习。然后,学生模型的骨干被冻结,其头部(即负责生成最终输出的部分)被更新,这个阶段后学生模型实际上是从它自己的输出中学习,而不是继续依赖教师模型。
简单来说DWPose能够在COCO-WholeBody基准上实现最先进的性能。
EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction
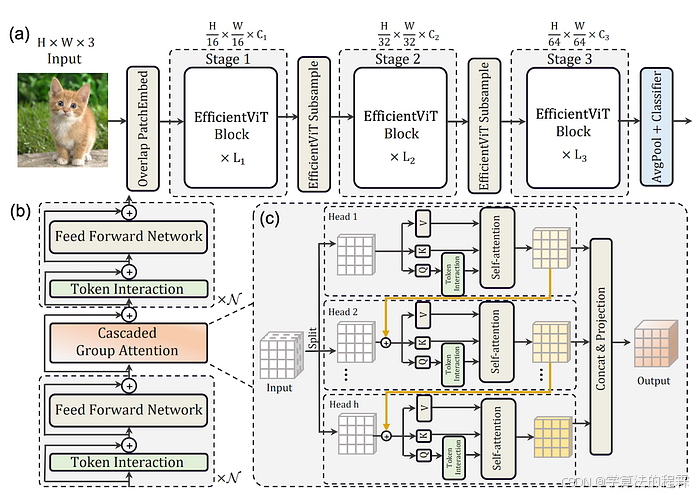
总结:提高内存效率并减少冗余👉,实现超快的视觉transformer
现在transformer 模型可以说是独领风骚,视觉 transformer (ViT) 在计算机视觉的许多领域占据了领先地位。
然而,标准视觉 transformer 的缺点之一是在推理过程中产生了大量的计算成本。
在很大程度上,这阻碍了它们在实时计算机视觉应用中的采用,但这种情况可能即将改变。
通过EfficientViT,香港中文大学和微软研究院的研究人员对ViT架构进行了两项惊人的改进。
首先,它们通过用记忆效率高得多的前馈网络(FFN)层交换一些记忆约束的自注意层来减少特征通道之间的通信时间。
接着通过一种新的级联组注意力(CGA),它们可以最大限度地减少在多个注意力头发生的冗余计算。
再加上一些巧妙的网络参数重新分配,它们能够将ViT带入新的领域。
仅举一个例子,EfficientViT-L0 for Segment Anything可以在A100 GPU上每秒处理1000多个图像,是MobileSAM的3倍多,同时实现平均交集超过 Union (mIoU)。
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
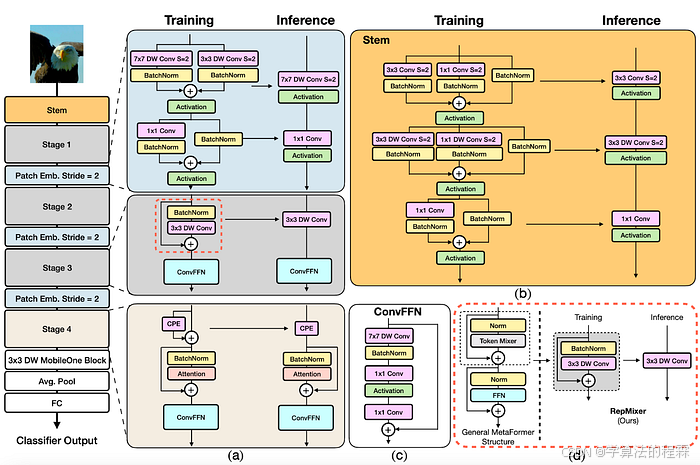
总结:在混合transformer模型中,通过调整或重新定义模型的某些结构参数,可以删除模型中的跳跃连接。
这种调整有助于在准确性和延迟之间找到一个更好的平衡,从而创建一个更稳健的模型。
通过FastViT,苹果的研究人员着手解决与EfficientViT类似的问题:视觉transformer的高计算成本。
他们的方法基于最大限度地发挥新兴视觉transformer模型和旧卷积神经网络的优势,来形成快速混合transformer。
在设计 FastViT 时,该团队结合了三个核心原则。首先,它们减少了跳过连接,其高内存访问对推理延迟有很大影响。接着,他们分解密集卷积,减少参数的数量,并使用一种称为过度参数化的技术增加它们的表示“容量”。
最后,它们在早期阶段用卷积核替换了一些计算密集型的自注意力层。
总的来说,这些设计决策导致的架构在从图像分类到 3D 网格回归的任务的准确性和延迟方面优于竞争模型。
以光速进行局部特征匹配
LightGlue: Local Feature Matching at Light Speed
总结:更快、更准确的稀疏特征匹配,适应问题难度
图像匹配是将一张图像中的选定点与另一张图像中的点相关联,从而“对齐”这两张图像的任务。
它用于各种下游应用,从相机跟踪到 3D 重建。在 CVPR 2020 上,Magic Leap 推出了 SuperGlue,这是一种基于 transformer 的图神经网络,在匹配来自稀疏点集的图像和拒绝异常值(两个图像不是来自同一场景的情况)方面取得了巨大的成功。
然而,基于Transformer的模型的计算强度阻碍了它在低延迟应用中的使用。
LightGlue 重新审视了 SuperGlue 的一些设计决策,进行了一些更改,这些更改提高了内存、计算、准确性和可训练性。
该模型同时计算“匹配性分数”,即一张图像中的点可以与第二张图像中的点匹配的置信度,以及成对点的“成对相似性”。
另外这个模型包含一个分类器,如果它高度自信,则可以停止匹配过程。这意味着匹配工作越容易,匹配过程将越快终止。
ProPainter:Improving Propagation and Transformer for Video Inpainting
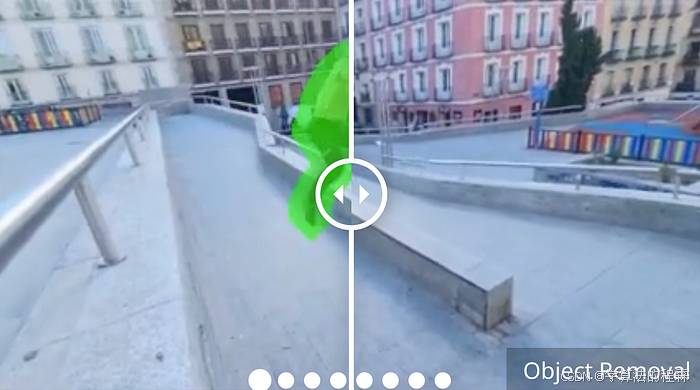
总结:通过双重传播(特征和图像)实现更快、计算效率更高的视频修复
与视频分割非常相似,视频修复是基于图像的任务(在本例中为修复)对视频的扩展,在空间和时间上是连贯一致的。
视频修复方法通常分为两个部分:图像传播和特征传播。图像传播本身会导致“unpleasant artifacts” and “texture misalignment”。
另一方面,由于 Transformer 的内存和计算限制,使用 Transformer 架构的特征传播通常仅限于短序列和较低分辨率的视频。
ProPainter(ProPagation和高效的Transformer)结合了图像传播和特征传播的优势,实现了双域传播。
该模型的实现涉及一系列改进,从将 CPU 密集型进程转换为 GPU 计算、用于完成流程的高效递归神经网络 (RNN),以及丢弃 Transformer 查询和键/值空间中不必要/冗余的段。
总而言之,该模型在峰值信噪比 (PSNR) 方面明显优于现有技术水平,同时减少了内存消耗!
Segment Anything

总结:这是一个改变游戏规则的基础视觉模型,它对于提示和未提示的分割任务有着重要的影响,这个模型还使用了有史以来最大的分割数据集。
借助 Segment Anything (SAM),Meta AI 将图像分割提升到了一个新的水平。
SAM 开源且易于使用,为广泛的领域带来了高质量的零样本分割。
基于 Vision Transformer 的模型有三种尺寸,支持多种分割模式。
在自动分割模式下,它将为所有事物(不同的实体)和事物(如“天空”等概念)生成预测的分割掩码。还可以使用边界框和/或关键点提示模型!
为了生成SAM,该团队构建了SA-1B,这是迄今为止最大的分割数据集,由1100万张图像中的1B掩码组成。
数据集的标注和模型的训练是在循环过程中进行的:模型用于辅助人类标注者,这些标注用于重新训练模型!
它已经通过蒸馏或借助 SA-1B 数据集开发了一系列较小的分割模型,如 FastSAM、MobileSAM 和 NanoSAM,并激发了看似无穷无尽的相关“<插入任务>任何东西”模型,从 Track Anything 到 Inpaint Anything。
Meta AI 的 FACET 基准测试(见下文)也改编自 SA-1B 的一个子集。
SAM 由计算机视觉库 FiftyOne 原生支持,这可以让你的数据分割比以往任何时候都更容易!
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models

总结:扩散模型的二维图像➕从新视角渲染➕融合图像👉room-scale3D网格
三维场景的网格表示在计算机图形学以及为增强现实和虚拟现实环境创建 3D 资产时非常有用。
然而,生成这些 3D 网格会遇到多重挑战。这些挑战中最主要的是缺乏高质量的 3D 数据进行训练。
由于收集 3D 数据的成本更高且时间更长,数据集通常较小,或者主要由简单的对象和场景组成。
虽然神经辐射场 (NeRF) 有望生成 3D 场景,但将其扩展到房间级尺度存在其自身的困难。
Text2Room 通过利用文本到图像扩散模型的 2D 图像生成功能,并巧妙地将 2D 图像组合成逼真的 3D 场景,从而绕过了这些问题。
该方法首先生成场景的单个图像。单目深度估计用于将场景反向投影为三维,并从中生成初始 3D 网格。
从那里,网格从新颖的视角迭代渲染,任何孔都被涂上,图像融合在一起。
在测试中,Text2Room 在一系列定量指标上的表现优于竞争对手,从感知质量 (PQ) 到 3D 结构完整性 (3DS)。
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators

总结:运动动力学➕跨帧注意力 👉 现成的文本到图像模型可以应用于生成视频
Text2Room 利用 2D 文本到图像模型的强大功能来生成高质量的 3D 网格,而 Text2Video-Zero 则利用这些相同的 2D 模型来执行低成本的零镜头文本到视频生成。
也就是说,Text2Video-Zero提出了一种从文本提示生成视频的方法,不需要微调或优化。
Text2Video不是独立地对每个帧随机采样潜在代码(扩散模型的输入),而是通过迭代翘曲过程来构建潜在代码。这鼓励了生成帧之间的时间一致性,但本身仍然是一个不足的约束。
除此之外,Text2Video用跨帧注意力层代替扩散模型中的自注意力层,将每个帧连接到第一帧。
Text2Video-Zero最令人惊讶的地方是,基本方法也适用于其他视频任务,如条件视频生成,甚至是指令引导的视频编辑!
你可以在文本到视频模式下运行该模型,也可以在Hugging Face的扩散器库的这两种附加模式下运行该模型!
ViperGPT: Visual Inference via Python Execution for Reasoning
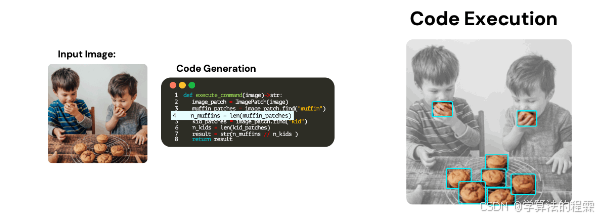
总结:使用代码生成模型来组合视觉语言模型👉,使其在视觉推理任务上具有最先进的性能
ViperGPT(之所以如此命名,是因为它执行 Python 代码)采用模块化方法来进行视觉推理。
ViperGPT 不依赖于捆绑视觉处理和推理但缺乏可解释性的端到端模型,而是使用 GPT-3 Codex 生成执行特定子例程来回答查询的 Python 代码。
例如,在上面的 gif 中,ViperGPT 可以使用对象检测模型来确定有多少松饼,然后使用这个结果来推理查询的正确答案。
通过定义简单的、特定任务的API,ViperGPT能够利用现有模型的代码生成和推理能力,而无需进行微调。
此外,代码生成模型的输出是代码,比端到端模型更易于解释。
最重要的是,ViperGPT在多种零样本任务上达到了最先进的性能,包括一般视觉问答、基于上下文的问答,甚至指代表达式任务!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









