







论文介绍
题目:SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model
论文:https://arxiv.org/abs/2504.09644
主页:https://github.com/earth-insights/SegEarth-R1
年份:2025
单位:西安交通大学,武汉大学,中科院
注:本篇由论文原作者审阅
【遥感图像分类项目实战链接,点击即可跳转学习页面】
创新点
-
提出新任务:Geospatial Pixel Reasoning
-
相较于传统语义分割与指代分割,首次引入“隐式语言引导+空间推理”结合的任务形式,允许通过隐性自然语言问题生成遥感图像中的目标区域掩码。
-
例子:不仅回答“哪里是足球场”,而是“哪里适合作为地震紧急避难区域”。
-
构建首个相关数据集:EarthReason
-
包含5434张图像&掩码,30000+隐式语言QA对,涵盖28种遥感场景类别,分辨率范围从0.5m到153m。
-
所有掩码均为人工标注,部分借助SAM辅助,并含有空目标样本用于提升泛化能力。
-
新架构:SegEarth-R1
利用大语言模型(LLM)处理语言指令,同时考虑遥感图像的高分辨率和小目标特性,设计了:
-
多尺度视觉编码器(Swin Transformer)
-
视觉Token压缩器(高冗余遥感图像上特别有效)
-
语义-空间融合的描述投影器(D-Projector)
-
无需预定义Mask Token的轻量分割器

数据
EarthReason
首个面向遥感图像“地理像素推理(Geospatial Pixel Reasoning)”任务的数据集,突破了传统明确指令的分割范式,支持隐式语言描述下的掩码预测。
图像与掩码概况
-
数据集共包含5434 张遥感图像,来自分类任务的公开数据集。
-
每张图像都配有人工标注的掩码,目标区域明确且质量较高。
-
图像分辨率从0.5米到153米不等,涵盖卫星与航空影像的多尺度特性。
-
图像尺寸从123×123 到 7617×7617 像素,大图像比例较高。
场景和目标多样性
-
场景覆盖28 个遥感类别,如:机场、水坝、农业温室、居民区、风电场等。
-
选取标准是具有空间推理意义的典型地物类型,而不是仅依赖视觉外观。
语言指令构建
-
每张图像对应多个隐式自然语言问题,平均每张图像生成 6 个问题和 3 个回答。
-
指令通过 GPT-4o 生成,结合图像及其类别信息自动构建。
-
为提升语言多样性,使用 GPT-3.5 对问题进行改写重述,增强模型泛化能力。
-
问题强调语义推理,例如:“如果发生地震,该区域最安全的避难场所在哪里?”而非直接点名“足球场”。
空目标样本设计
-
特别构建了约200张“空目标图像”,即问题描述的目标实际上不在图中。
-
用于训练模型判断“无目标”场景,防止其总是强行生成掩码。
掩码标注方式
-
所有掩码均由遥感和计算机视觉领域的多位专家人工完成。
-
简单目标可借助 Segment Anything 模型(SAM)辅助生成。
-
对于复杂或边界模糊的目标(如温室、风机),则完全由专家手工绘制多边形掩码。
-
标注过程严格交叉审核,确保数据质量。
数据划分与设计原则
-
数据集被划分为训练、验证和测试三部分,分别为 2371、1135 和 1928 张图像。
-
某些类别仅出现在验证和测试集中,用于评估模型对未见场景的泛化能力。
-
指令语言平均长度为约21词,回答为约27词,语言复杂度适中。
数据集的优势
-
支持更贴近人类实际需求的“隐式”目标查找与区域理解。
-
图像具有丰富的空间层次、尺度多样性和复杂场景结构。
-
语言问题设计自然灵活,且全部与图像语义高度相关。
-
提供新任务探索平台,推动语言与遥感影像的深度融合。
-

方法
整体框架
-
SegEarth-R1 是一种面向遥感图像的语言引导像素级推理模型。
-
目标是在自然语言隐式描述的指引下,定位并分割遥感图像中的目标区域。
-
模型由三大核心部分组成:视觉编码器、大语言模型(LLM)模块、掩码生成器。
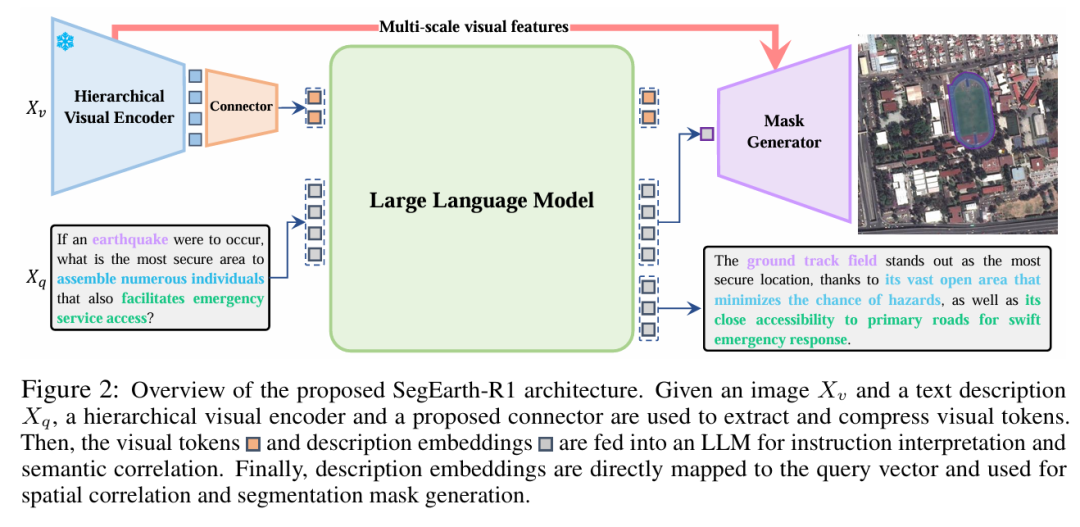
模块一:多尺度视觉编码器
-
采用 Swin Transformer 作为主干网络,适配遥感图像中的多尺度和小目标问题。
-
构建了层级化的特征表示,从浅层提取高分辨率细节,到深层获取全局语义。
-
保留多个尺度的图像特征(如1/4、1/8、1/16、1/32分辨率),为后续空间推理打下基础。
-
适用于遥感中存在的极端尺度变化(如从小棚屋到大片机场跑道等)。
模块二:大语言模型与视觉语言融合
1. 融合方式
-
将图像特征与语言描述共同嵌入到一个统一的多模态空间。
-
使用轻量大语言模型(如 phi-1.5)进行语义理解与推理,但不直接参与掩码生成。
2. 视觉Token压缩机制
-
遥感图像分辨率极高,直接输入会导致LLM计算开销极大。
-
为此设计了一个Token压缩模块,通过卷积与层归一化等操作显著降低特征维度,
保留关键语义信息的同时大幅减少LLM的输入量。 -
基于遥感图像冗余性高的特点(从信息熵和空间相似度两方面进行了分析)进行优化。
模块三:掩码生成器与空间推理机制
1. 掩码生成思路
-
参考 Mask2Former 架构,但做了重要简化:取消了预定义的mask token。
-
直接使用语言描述的向量表示作为查询向量,生成对应的目标掩码。
2. 描述投影器(D-Projector)
-
面对长度不一的语言输入,D-Projector将整段文字压缩为一个全局语义向量。
-
然后用该语义向量与图像多尺度特征进行跨模态注意力交互,建立空间对齐关系。
-
最终输出一个用于掩码生成的空间查询向量,具有更强的语义空间融合能力。
训练策略与优化方法
-
在训练时使用预训练的视觉编码器和语言模型,仅微调连接模块与掩码生成器。
-
所有图像被统一缩放至固定大小,保持宽高比,通过填充处理不等尺寸图。
-
损失函数采用两种主流分割评估方式的组合,用于稳定训练和提升边界预测效果。
-
使用bf16精度加速训练,并在两张A100显卡上进行高效训练。
-
实验与结果
-
SegEarth-R1 在遥感图像的语言引导分割任务中表现出显著优势,优于现有多模态和传统分割方法。它在多个数据集和任务上均取得了领先性能,首次实现大语言模型在遥感空间推理任务上的突破。
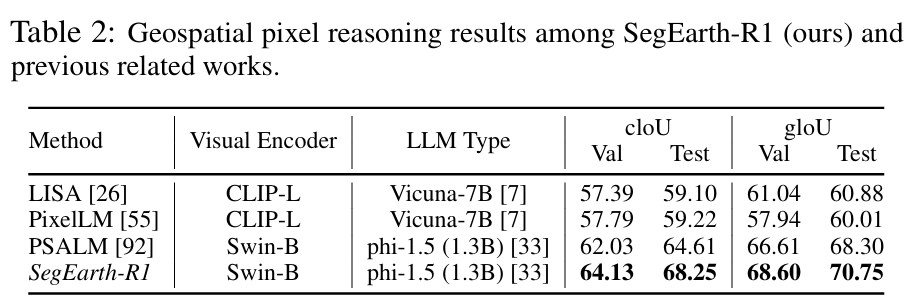
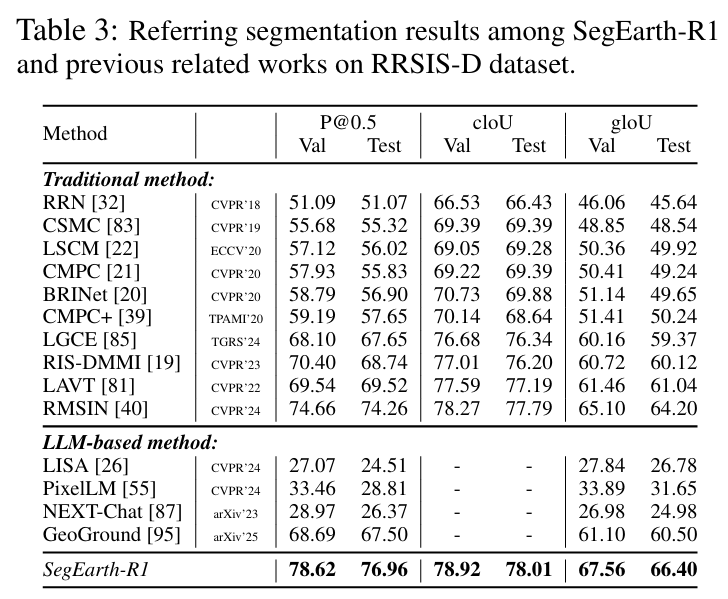
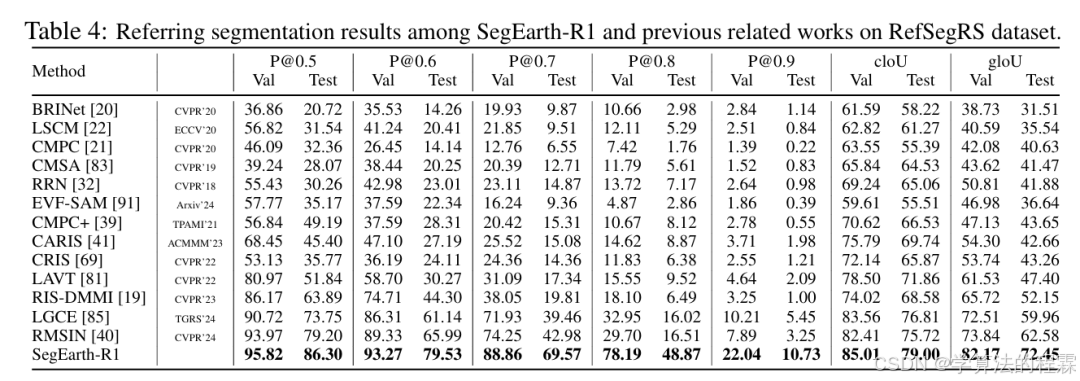



【遥感图像分类论文链接,点击即可跳转学习页面】

















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









