







1.背景:
conductor的主分支在2022-11-01这天提交了一个变更,即worker从server端拉取任务时是批量拉取;如此,worker作为消费端能减少
pull任务时的耗时,批次越大,每次拉取任务的平均耗时就越低,此在梳理下其相关逻辑。
2.关键代码:
2.1 拉取批量的配置
配置代码:
com.netflix.conductor.client.spring.ClientProperties#taskThreadCount

这是之前就有的一个配置项,用于精细化配置每个worker的执行执行线程数
在applicaiton.properties中:
conductor.client.task-thread-count.aaa=5
或者
conductor.client.taskThreadCount.aaa=5
若不配置 conductor.client.taskThreadCount,则会通过 conductor.client.threadCount计算,该参数配置的是所有worker的执行线程池大小
若不配置conductor.client.threadCount,则默认取worker的数量,即平均一个worker一个执行线程
代码: com.netflix.conductor.client.automator.TaskRunnerConfigurer#TaskRunnerConfigurer
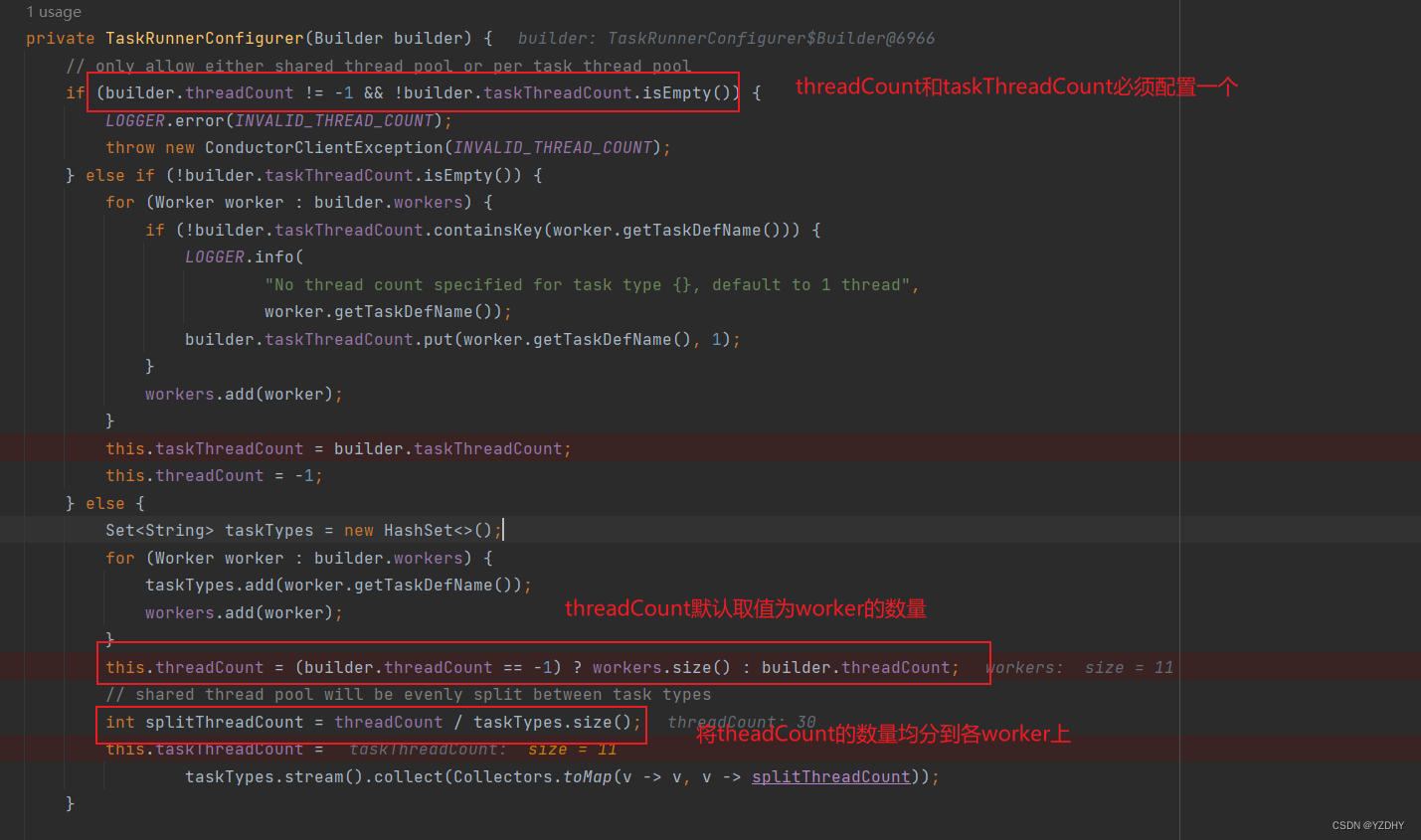
注意:conductor.client.taskThreadCount 和 conductor.client.threadCount 不能同时配置,否则报错

2.2 批量拉取动作
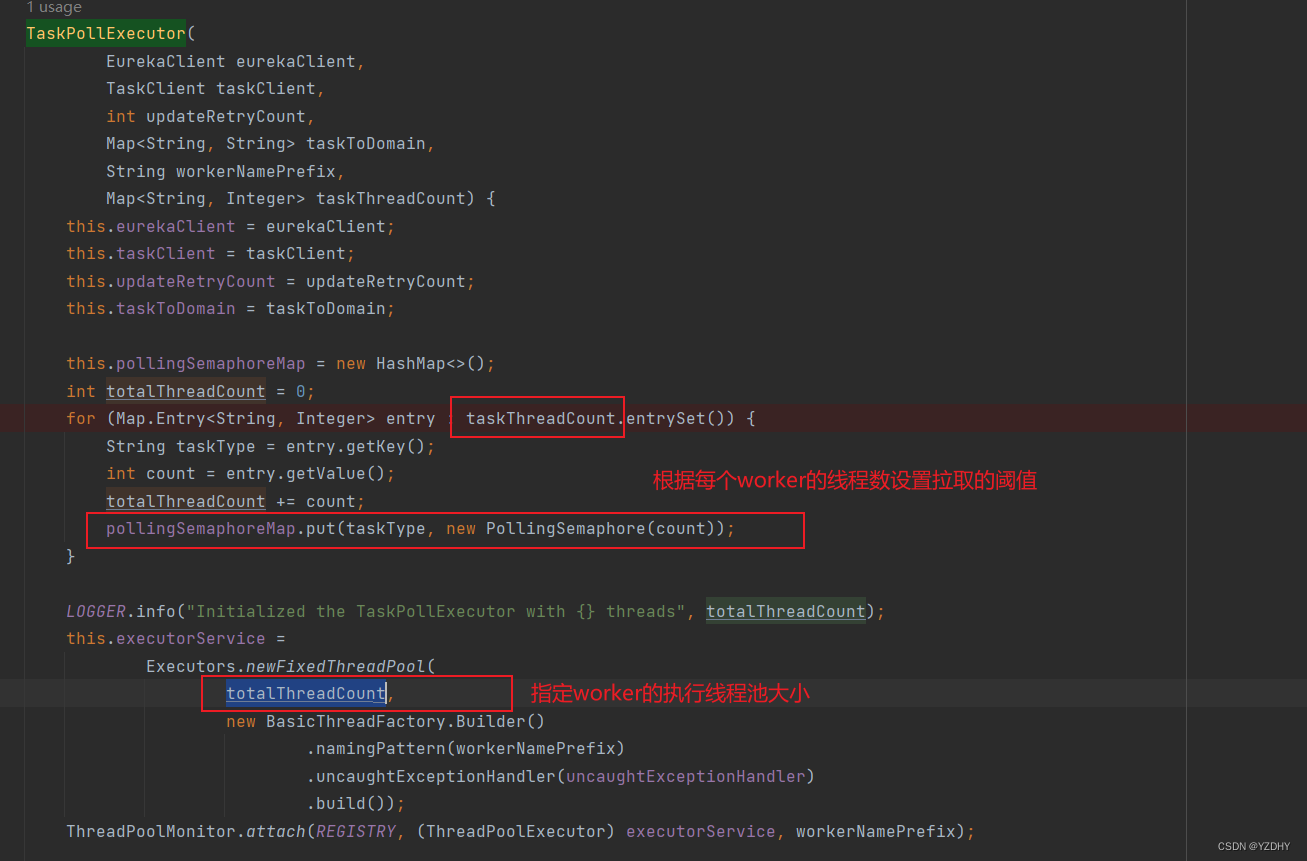
com.netflix.conductor.client.automator.TaskPollExecutor#TaskPollExecutor
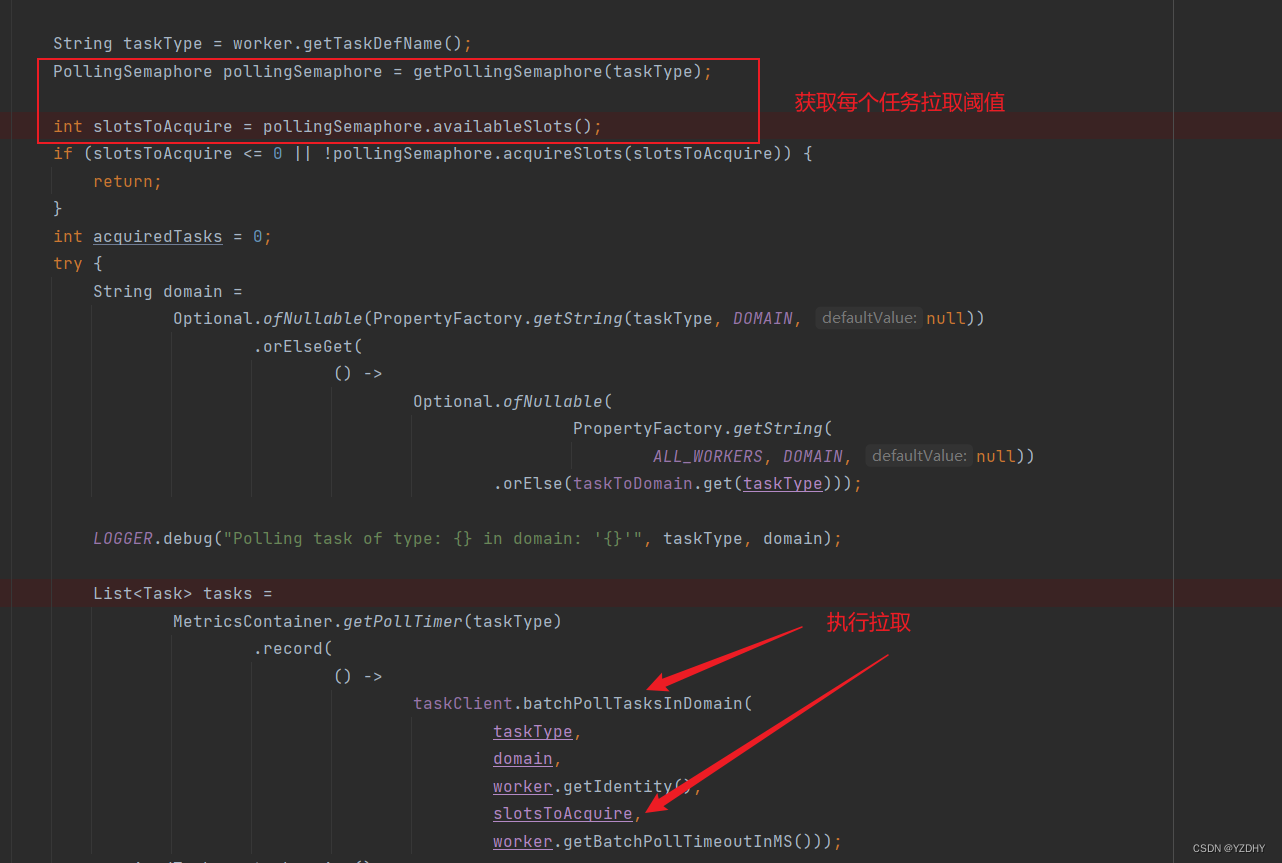
拉取任务:
com.netflix.conductor.client.automator.TaskPollExecutor#pollAndExecute
3.一批次pull数量设置的取舍
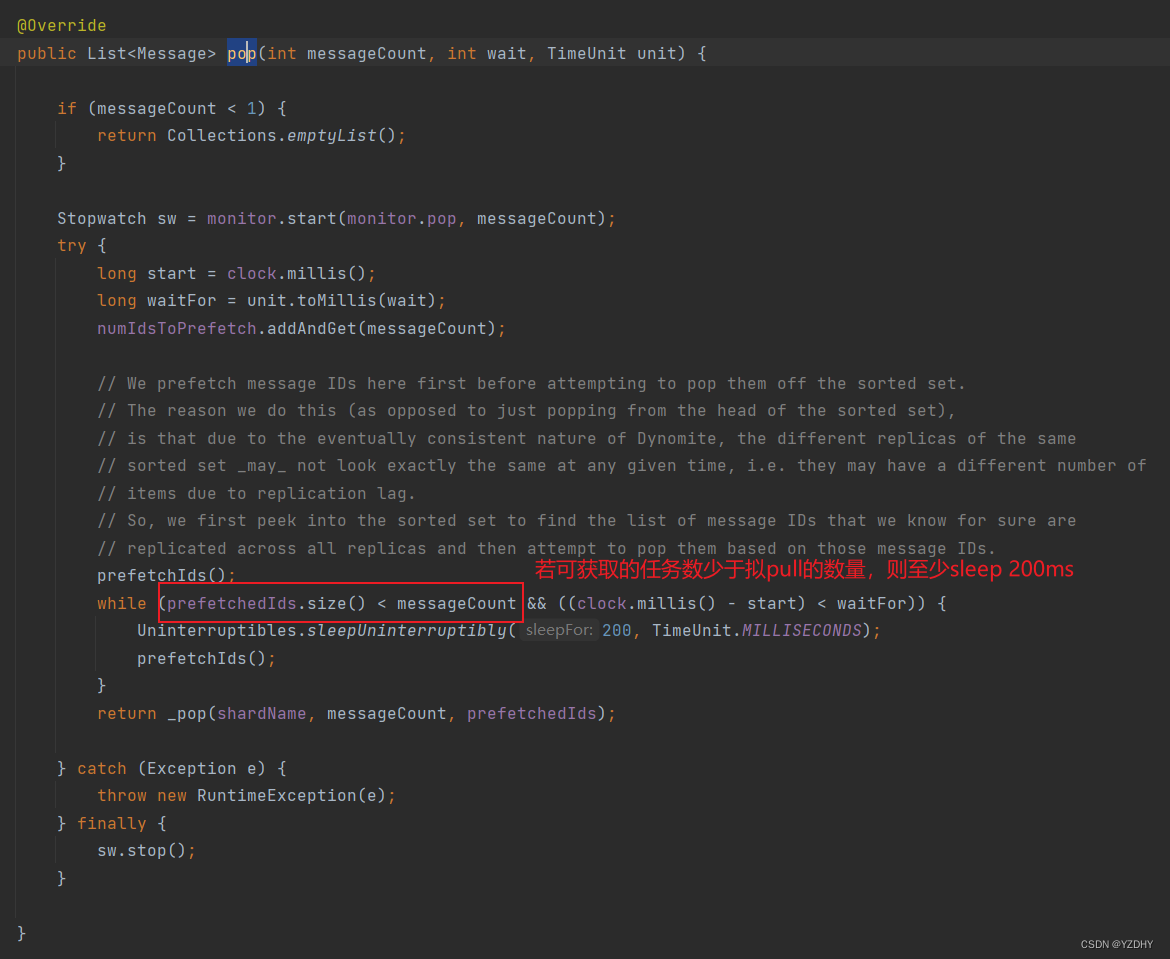
** 在任务积压时,一次pull的任务数量越多,理论上在pull上的平均耗时就越少,消费能力越强,但是,若设置太大,会影响低负载时的耗时;**
执行批量拉取时,请求的rest接口为 : GET /api/tasks/poll/batch/{taskType}
com.netflix.conductor.rest.controllers.TaskResource#batchPoll
com.netflix.conductor.service.ExecutionService#poll(java.lang.String, java.lang.String, java.lang.String, int, int)
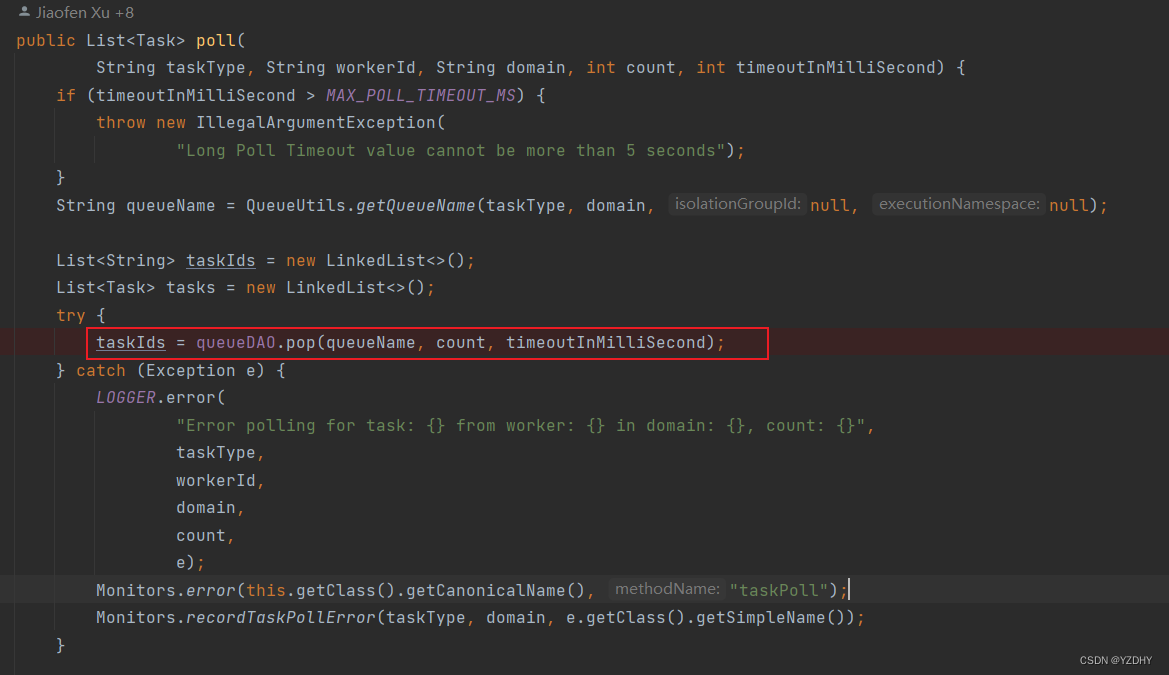
com.netflix.conductor.redis.dao.DynoQueueDAO#pop

我们走的实现为:com.netflix.dyno.queues.redis.RedisDynoQueue#pop














 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









