







Key Problems
- the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change.
- This slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities.
- The change in the distributions of layers’ inputs presents a problem because the layers need to continuously adapt to the new distribution.
Contributions
- Batch Normalization allows us to use much higher learning rates and be less careful about initialization.
- It also acts as a regularizer, in some cases eliminating the need for Dropout.
- Applied to a state-of-the-art image classification model, Batch Normalization achieves the same accuracy with 14 times fewer training steps, and beats the original model by a significant margin.
- Using an ensemble of batchnormalized networks, we improve upon the best published result on ImageNet classification: reaching 4.9% top-5 validation error (and 4.8% test error), exceeding the accuracy of human raters.
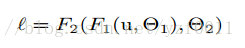
Methods
- minimize the loss
- gradient of the loss function
covariate shift can be extended beyond the learning system as a whole, to apply to its parts, such as a sub-network or a layer
gradient descent step
- normalize the inputs
- normalizing the inputs of a sigmoid would constrain them to
the linear regime of the nonlinearity. To address this, we make sure that the transformation inserted in the network can represent the identity transform.
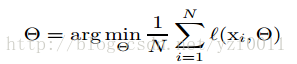
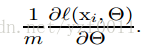
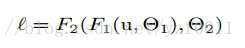
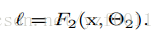
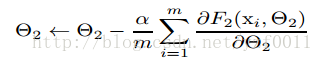
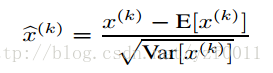
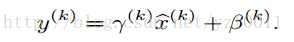
Others
- advantages of mini-batch
- First, the gradient of the loss over a mini-batch is an estimate of the gradient over the training set, whose quality improves as the batch size increases.
- computation over a batch can be much more efficient than m computations for individual examples, due to the parallelism afforded by the modern computing platforms.
- While stochastic gradient is simple and effective, it requires careful tuning of the model hyper-parameters, specifically the learning rate used in optimization, as well as the initial values for the model parameters.
- the network training converges faster if its inputs are whitened – i.e., linearly transformed to have zero means and unit variances, and decorrelated.














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









