







结论
1. nsq中MessageID是个16字节长的byte数组
2. nsq先使用雪花算法生成全局唯一的guid(int64类型,占8个字节),然后再使用hex.Encode()算法把guid转换为MessageID
3. guid中自增序列号占位12位,所以每毫秒最多4096个,相当于每秒409万个
4. 为了延长guid的可用时间范围,时间戳的起点不是通常的1970年1月1日,而是设置了一个特定时间(2012年10月28日),这样可以用到公元2081年
5. 至于为什么nsq不直接用int64类型的guid,而是又做了一次16进制的编码,目的尚待研究,哪天搞明白了再补上
详细分析
MessageID的定义,源代码在文件nsq/nsqd/message.go
const (
MsgIDLength = 16
)
type MessageID [MsgIDLength]byte可以看到MessageID本质上就是个16字节长的byte数组
再看下MessageID的生成方式,只有一个函数GenerateID(),源代码在文件nsq/nsqd/topic.go,流程也很简单,就是内部调用idFactory.NewGUID()得到int64型的id,然后再调用id.Hex()转换为MessageID
// 产生唯一消息ID
func (t *Topic) GenerateID() MessageID {
......
id, err := t.idFactory.NewGUID()
if err == nil {
return id.Hex() // uid转成message
}
......
}下面再看所谓idFactory.NewGUID()函数 和 id.Hex()函数内部是怎么实现的
源代码在文件nsq/nsqd/guid.go,代码如下,我已经加了详细的注释
const (
nodeIDBits = uint64(10) // 节点ID占10位(nsqd的节点最多1024)
sequenceBits = uint64(12) // 自增序列号占12位(每毫秒最多4096个)
nodeIDShift = sequenceBits // 节点ID偏移位数(自增序列号占位)
timestampShift = sequenceBits + nodeIDBits // 时间戳偏移位数(自增序列号占位+节点ID占位)
sequenceMask = int64(-1) ^ (int64(-1) << sequenceBits)// 自增序列号的最大值(4095,也就是111111111111)
// 特定毫秒时间戳(2012-10-28 16:23:42 UTC).UnixNano() >> 20)
// 生成唯一ID时会用当前毫秒戳减去这个值,计算出来的时间差值会比较小,能扩大时间戳占位的使用范围
// 因为生成的唯一ID是int64类型,除去第一位的符号位不能用,节点ID占10位,自增序列号占12位,还剩下41位,所以毫秒时间戳最大可用41位
// 2的41次方,即2199023255552,每年31536000000毫秒,算下来够用69年,如果从1970年1月1日0点为起点,只能用到2039年
// 所以,采用当前时间减去twepoch,相当于以twepoch为起点,这样可以用到2012年+69年=2081年,大大延长了算法可用时间
twepoch = int64(1288834974288)
)
var ErrTimeBackwards = errors.New("time has gone backwards") // 时钟倒流的error(当前时间比之前时间还小)
var ErrSequenceExpired = errors.New("sequence expired") // 同一毫秒戳内序列号越界的error
var ErrIDBackwards = errors.New("ID went backward") // ID倒流的error(新产生的ID比之前ID还小)
type guid int64
// guid生成器,产生guid(int64)
type guidFactory struct {
sync.Mutex // 多协程环境,需加锁
nodeID int64 // 唯一节点ID(nsqd唯一ID)
sequence int64 // 在 lastTimestamp 下生成的序号,从0开始
lastTimestamp int64 // 上次生成messageID时的毫秒时间戳(伪毫秒,因为是拿纳秒值除以1048576得来的)
lastID guid // 上次生成的ID(下次生成新ID时需>=本值)
}
// 根据nodeID生成一个唯一ID工厂
func NewGUIDFactory(nodeID int64) *guidFactory {
return &guidFactory{
nodeID: nodeID,
}
}
// 产生int64型唯一ID,0表出错
func (f *guidFactory) NewGUID() (guid, error) {
// 多协程环境,需加锁
f.Lock()
// 计算当前毫秒(其实是伪毫秒,右移20位等同于除以1048576,不使用除以1000000,是因为右移效率更高一点)
ts := time.Now().UnixNano() >> 20
// 比上次还小,说明时钟倒流了
if ts < f.lastTimestamp {
f.Unlock()
return 0, ErrTimeBackwards
}
if f.lastTimestamp == ts { // 同一毫秒戳情况下,自增1即可
f.sequence = (f.sequence + 1) & sequenceMask
if f.sequence == 0 { // 等于0说明是超过上限后重置了
f.Unlock()
return 0, ErrSequenceExpired
}
} else { // 不同毫秒戳了,那就重新从0开始
f.sequence = 0
}
// 更新毫秒戳
f.lastTimestamp = ts
// ID占位如下:41位的时间戳 + 10位的节点ID + 12位的序列号
id := guid(((ts - twepoch) << timestampShift) | (f.nodeID << nodeIDShift) | f.sequence)
// 新ID不可能<=旧ID
if id <= f.lastID {
f.Unlock()
return 0, ErrIDBackwards
}
// 记录最新的ID
f.lastID = id
f.Unlock()
return id, nil
}
// guid转为十六进制编码
func (g guid) Hex() MessageID {
var h MessageID
var b [8]byte
b[0] = byte(g >> 56) // 从高往低,每8位转成一个字节,下同
b[1] = byte(g >> 48)
b[2] = byte(g >> 40)
b[3] = byte(g >> 32)
b[4] = byte(g >> 24)
b[5] = byte(g >> 16)
b[6] = byte(g >> 8)
b[7] = byte(g)
// 转16进制(每4位转成1个字节,所以8字节最终转换成16字节,放在MessageID的数组)
hex.Encode(h[:], b[:])
return h
}对上面的代码再解释下
要点1:这里的毫秒戳是伪毫秒
真正的毫秒是用当前时间的纳秒值除以1000000,但这里是拿纳秒值右移20位,相当于除以1048576,好处是效率更高一点
要点2:guid跟常见的雪花算法几乎完全相同,guid是int64类型的,分3部分
自增序列号占12位,2的12次方=4096,时间戳精确到了毫秒,所以1毫秒最大可以产生4096个ID,相当于单个nsqd节点可以1分钟产生409万个ID,足够使用了
节点ID占10位,2的10次方=1024,所以nsqd最大可以开1024个
时间戳占41位,精确到毫秒。这里做了一个小技巧,常见的雪花算法一般是以UTC时间起点开始算,也就是1970年1月1日的0时,因为2的41次方=2199023255552,而每年31536000000毫秒,算下来只够用69年,如果不做优化,从1970年算的话只能用到1970+69年=2039年。所以nsqd作者把2012年10月28日为起点,再拿当前时间和2012年10月28日的差值作为时间戳,这样能用到2012+69=2081年去了
缺点也有,就是你启动nsqd的时候,时间不能设置到2012年10月28日之前,否则会出错。不过我们一般也不会这么改时间,没啥问题
要点3. 得到guid后,又对guid做了一次16进制的编码转换
至于为什么要这么做,有什么优点,我也没搞明白,这里只讲下编码转换的过程
guid是int64类型的数字,8个字节
hex.Encode()是把每4个字节按照16进制的值,再根据ASCII码表中的二进制,得到1个字节,所以guid转换完后一共16个字节,就是MessageID
如果你想仔细研究下hex.Encode()的实现原理,可以参考我的这篇博客
详解go的hex.Encode原理_YZF_Kevin的博客-CSDN博客
测试MessageID代码
我把MessageID相关的代码复制出来,给大家做一个演示,看下MessageID的格式,有十进制的打印,也有字符串的打印,效果如下图
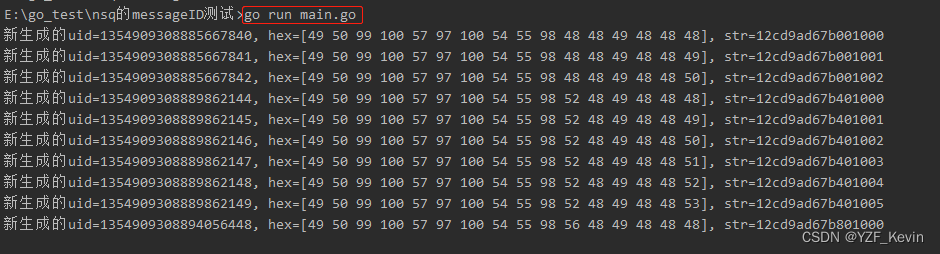
可以看到以字符串展示时,范围在1-9,a-f之间
完整代码如下,大家可以拿去在本地测试
package main
import (
"encoding/hex"
"errors"
"fmt"
"sync"
"time"
)
const (
nodeIDBits = uint64(10) // 节点ID占10位(nsqd的节点最多1024)
sequenceBits = uint64(12) // 自增序列号占12位(每毫秒最多4096个)
nodeIDShift = sequenceBits // 节点ID偏移位数(自增序列号占位)
timestampShift = sequenceBits + nodeIDBits // 时间戳偏移位数(自增序列号占位+节点ID占位)
sequenceMask = int64(-1) ^ (int64(-1) << sequenceBits) // 自增序列号的最大值(4095,也就是111111111111)
// 特定毫秒时间戳(2012-10-28 16:23:42 UTC).UnixNano() >> 20)
// 生成唯一ID时会用当前毫秒戳减去这个值,计算出来的时间差值会比较小,能扩大时间戳占位的使用范围
// 因为生成的唯一ID是int64类型,除去第一位的符号位不能用,节点ID占10位,自增序列号占12位,还剩下41位,所以毫秒时间戳最大可用41位
// 2的41次方,即2199023255552,每年31536000000毫秒,算下来够用69年,如果从1970年1月1日0点为起点,只能用到2039年
// 所以,采用当前时间减去twepoch,相当于以twepoch为起点,这样可以用到2012年+69年=2081年,大大延长了算法可用时间
twepoch = int64(1288834974288)
)
const (
MsgIDLength = 16 // 16个字节长度
minValidMsgLength = MsgIDLength + 8 + 2 // 有效消息的最小长度(8字节时间戳,2字节投递次数,16字节的ID)
)
type MessageID [MsgIDLength]byte
var ErrTimeBackwards = errors.New("time has gone backwards") // 时钟倒流的error(当前时间比之前时间还小)
var ErrSequenceExpired = errors.New("sequence expired") // 同一毫秒戳内序列号过期的error
var ErrIDBackwards = errors.New("ID went backward") // ID倒流的error(新产生的ID比之前ID还小)
type guid int64
// guid生成器,产生guid(int64)
type guidFactory struct {
sync.Mutex // 多协程环境,需加锁
nodeID int64 // 唯一节点ID(nsqd唯一ID)
sequence int64 // 在 lastTimestamp 下生成的序号,从0开始
lastTimestamp int64 // 上次生成messageID时的毫秒时间戳,伪毫秒,因为是拿纳秒值右移20位(等同于除以1048576得来的)
lastID guid // 上次生成的ID(下次生成新ID时需>=本值)
}
// 根据nodeID得到唯一ID的工厂
func NewGUIDFactory(nodeID int64) *guidFactory {
return &guidFactory{
nodeID: nodeID,
}
}
// 产生int64型唯一ID,0表出错
func (f *guidFactory) NewGUID() (guid, error) {
// 多协程环境,需加锁
f.Lock()
// 计算当前毫秒(其实是伪毫秒,右移20位等同于除以1048576,不使用除以1000000,是因为右移效率更高一点)
ts := time.Now().UnixNano() >> 20
// 时间戳比上次还小,说明时钟倒流了
if ts < f.lastTimestamp {
f.Unlock()
return 0, ErrTimeBackwards
}
if f.lastTimestamp == ts { // 同一毫秒戳情况下,自增1即可
f.sequence = (f.sequence + 1) & sequenceMask
if f.sequence == 0 { // 等于0说明是超过上限后重置了
f.Unlock()
return 0, ErrSequenceExpired
}
} else { // 不同毫秒戳了,那就重新从0开始
f.sequence = 0
}
// 更新毫秒戳
f.lastTimestamp = ts
// ID占位如下:41位的时间戳 + 10位的节点ID + 12位的序列号
id := guid(((ts - twepoch) << timestampShift) | (f.nodeID << nodeIDShift) | f.sequence)
// 新ID不可能比旧ID小
if id <= f.lastID {
f.Unlock()
return 0, ErrIDBackwards
}
// 记录最新的ID
f.lastID = id
f.Unlock()
return id, nil
}
// guid转为十六进制编码
func (g guid) Hex() MessageID {
var h MessageID
var b [8]byte
b[0] = byte(g >> 56) // 每8位转成一个字节,下同
b[1] = byte(g >> 48)
b[2] = byte(g >> 40)
b[3] = byte(g >> 32)
b[4] = byte(g >> 24)
b[5] = byte(g >> 16)
b[6] = byte(g >> 8)
b[7] = byte(g)
// 转16进制(每4位转成1个字节,所以8字节最终转换成16字节,放在MessageID的数组)
hex.Encode(h[:], b[:])
return h
}
func main() {
factory := NewGUIDFactory(1)
fmt.Printf("sequenceMask=%v \n", sequenceMask)
for i := 0; i < 10; i++ {
uid, err := factory.NewGUID()
if err != nil {
fmt.Println("生成uid失败, err=", err)
return
}
msgID := uid.Hex()
fmt.Printf("新生成的uid=%v, hex=%v, str=%v\n", uid, msgID, string(msgID[:]))
}
}















 4466
4466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









