







目录
Map接口
Map接口是双列集合类中的顶级接口,Map中存储的是键--值对的数据,并且数据不是按添加的顺序存储的,将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值
Map集合中的方法:
V put(K key,V value),向集合中添加一个元素
V remove(Object key),根据键删除一个键值对,并返回元素中的值
void clear(),清空集合中的元素
boolean containsKey(Object key),根据键判断集合中是否含有对应的元素
boolean containsValue(Object value),根据值判断集合中是否含有对应的元素
boolean isEmpty(),判断集合是否为空集合
int size(),获取集合中的元素数
V get(Object key),根据键或者集合中对应的元素
Collection<V> values(),获取一个由全部值组成的单例集合
Set<K> keySet(),获取一个由全部键组成的Set集合
Set<Map.Entry<K,V>> entrySet(),返回此集合中包含的映射的Set视图
HashMap类
HashMap中键是无序的,且可以也只可以存储一个键为null的键值对
HashMap<String,String> hmap=new HashMap<>();
hmap.put("a","aa");
hmap.put("b","bb");
hmap.put("c","cc");
hmap.put("d","dd");
hmap.put("a","yy");//存储重复的键的时候会判断,如果原来存在同样的键,则会覆盖原来的键值对
hmap.put("e","aa");
hmap.put("x","aa");
hmap.put(null,"ff");//HashMap中可以且只能存储一个null的键
System.out.println(hmap);//{a=yy, b=bb, c=cc, d=dd, e=aa, x=aa}//覆盖了"a"对应的键值对
//Map集合中的共有方法
System.out.println(hmap.get("a"));//根据键返回值
System.out.println(hmap.remove("c"));//根据键删除一个键值对,并且返回该键对应的值
//hamp.clear();清空集合中的元素
System.out.println(hmap.containsKey("d"));//判断是否存在指定键的键值对
System.out.println(hmap.containsValue("aa"));//判断是否存在指定值的键值对
System.out.println(hmap.isEmpty());//判断集合中是否存在元素
System.out.println(hmap.size());//返回集合中的键值对个数
hmap.replace("x","xx");//根据键来替换值
Collection<String> a=hmap.values();//返回一个由所有值构成的单列集合
Set<String> s=hmap.keySet();//返回一个由所有键构成的set集合哈希结构
无论是HashSet类还是HashMap类都不可以添加重复的元素或者是键,这是在增加时就判断了元素是否重复。
这个判断是通过add()方法在底层调用了hashCode(),equals()两个方法,作为判断条件
Object类中的hashCode()方法:public native int hashCode();//该方法会获取对象在内存中的地址值,被native修饰的方法是本地操作系统中的方法,java不实现只是调用
equals():除了Object类中的方法是比较地址值,其余类中重写的equals()方法都是比较对象中的内容是否相同
使用hashCode()与equals()方法来做判断的原因:
在往hash结构中添加元素的时候都是添加的类的实例对象,若是调用的Object类中的hashCode()方法的话无法判断对象中的内容是否相同,故一般会重写hashCode()方法利用对象中的具体内容来计算哈希值,equals()方法用来比较对象中的具体内容也需要重写。
hashCode()方法作为判断重复有一个弊端就是,可能会出现对象中的内容不同但是算出来的哈希值却相同的情况也就是这种方法不是安全的(例如"通话"与"重地"这两个字符串对象就是例子),此时就需要使用equals()再做一次判断,这就是使用两个方法的原因
String s1=new String("通话");
String s2=new String("a");
String s3=new String("b");
String s4=new String("重地");
HashSet<String> set1=new HashSet<>();
set1.add(s1);
set1.add(s2);
set1.add(s3);
set1.add(s4);//计算出来的哈希值可能会出现内容不同但是值相同的情况,例如"通话"与"重地"就是一个例子,此时会根据equals方法再判断一遍
System.out.println(set1);
Car car1=new Car(1,"宝马");
Car car2=new Car(2,"奔驰");
Car car3=new Car(3,"大众");
Car car4=new Car(1,"宝马");
HashSet<Car> set2=new HashSet<>();
set2.add(car1);
set2.add(car2);
set2.add(car3);
set2.add(car4);
System.out.println(set2);
_________________________________________________________________________________________
//Car类中重写的代码
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return no == car.no &&
nam.equals(car.nam);
}
@Override
public int hashCode() {
return Objects.hash(no, nam);
}HashMap类的底层存储结构(java8以后引入红黑树)
3种数据结构:1.数组(哈希表) 2.链表 3. 红黑树
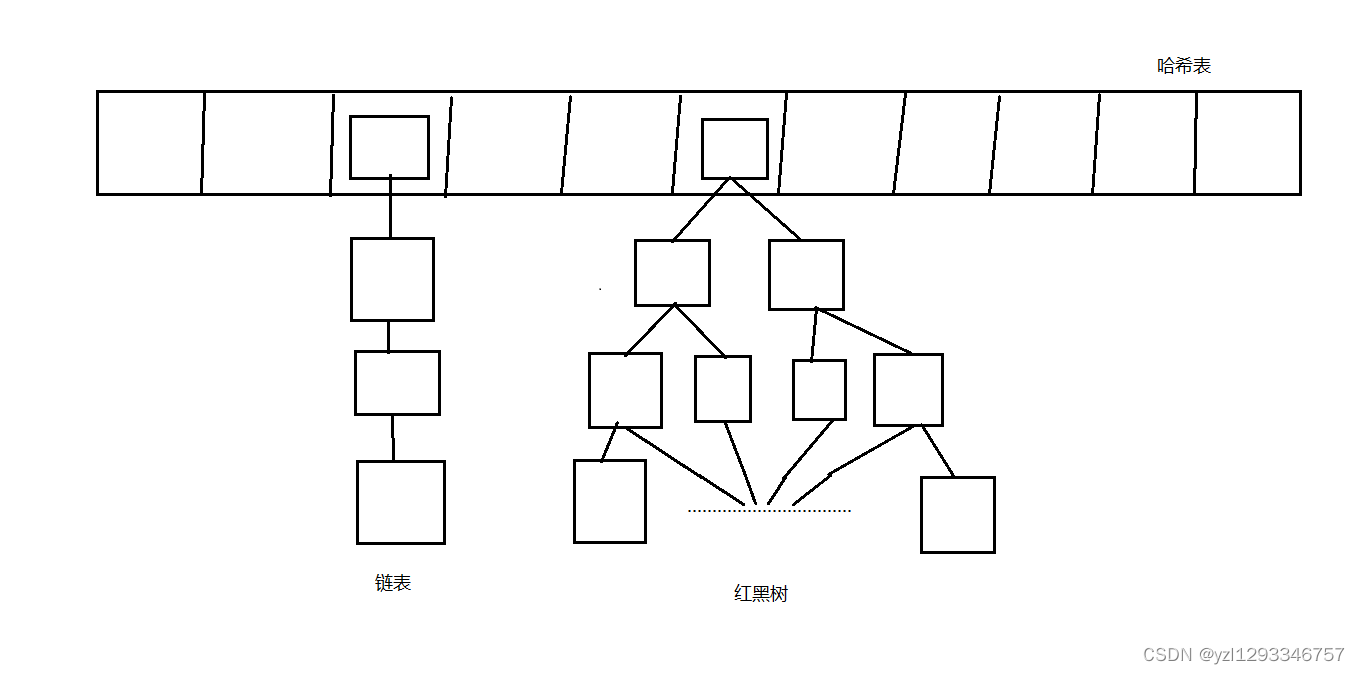
哈希表:默认长度是16,负载因子是0.75(即数组中存储的元素超过3/4后会扩容),每次扩容会扩容一倍
链表:在哈希表中每个位置上存储的数据结构(哈希表上对应的位置不是存储链表就是存储红黑树)
红黑数:在链表的长度超过8且哈希表的长度超过64时,链表会转换为红黑树
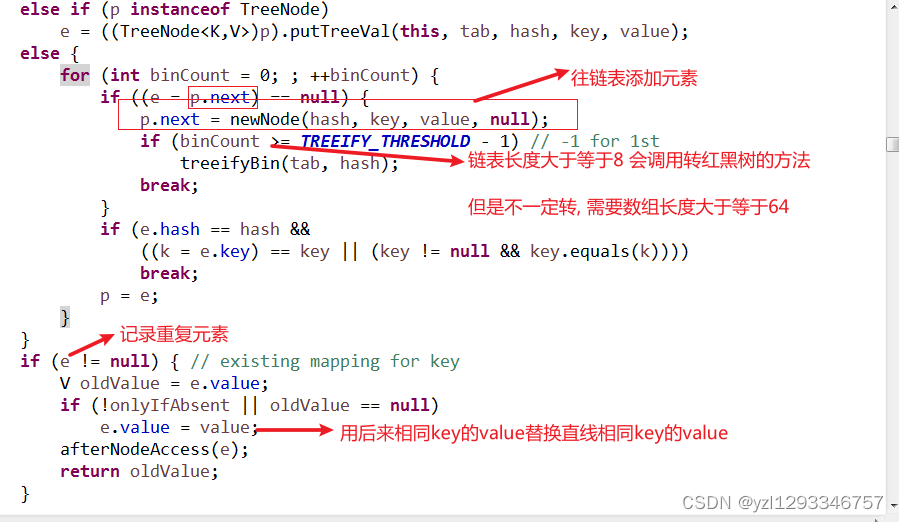
HashMap集合中添加元素的顺序:
1.第一次存储的时候会判断哈希表是否为null或者长度是否为0,是则初始化一个哈希表
2.根据元素的内容计算哈希值(例如a的哈希值为97),并取mod运算计算出该元素在数组中的存储位置,然后将元素存储在Node对象(链表)中(底层代码中的mod运算使用的是&运算符,例如:n-1&hash与hash%n是等价的)
3.下一次增加的元素在相同的位置的话,会增加到这个位置的元素对应链表的下一个位置上
4.若是链表满足红黑树的转换条件则会转换为红黑树,若是该位置上本来就是红黑数则会直接加到红黑树中
5.若是增加哈希值相同的元素,则会修改哈希表中的元素的值,将其覆盖

HashTable类
底层实现是HashMap类相同,但是是线程安全的,但是键和值都不可以为null
Hashtable<String,String> htable=new Hashtable<>();
htable.put("a","aa");
htable.put("b","bb");
htable.put("c","cc");
htable.put("d","dd");
htable.put("a","yy");//存储重复的键的时候会判断,如果原来存在同样的键,则会覆盖原来的键值对
htable.put("e","aa");
htable.put("x","aa");
//htable.put(null,"ff");HashTable中无法创建null值的键
//其余方法与HashMap相同TreeMap类的
键值对按照键的自然顺序排序故在键的位置存储引用类型的时候,该类一定要实现Comparable接口,才能比较键的大小
TreeMap<String,String> tmap=new TreeMap<>();
tmap.put("a","aa");
tmap.put("a","yy");//存储重复的键的时候会判断,如果原来存在同样的键,则会覆盖原来的键值对
tmap.put("e","aa");
tmap.put("x","aa");
tmap.put("g","FF");
tmap.put("f","FF");
tmap.put("b","bb");
tmap.put("c","cc");
tmap.put("d","dd");
//Map接口中的方法都可以实现
System.out.println(tmap);//{a=yy, b=bb, c=cc, d=dd, e=aa, f=FF, g=FF, x=aa}
TreeMap<Car,String> tmap1=new TreeMap<>();//在键的位置存储引用类型的时候,该类一定要实现Comparable接口
Car car1=new Car(1,"baoma1");
Car car2=new Car(2,"baoma2");
Car car3=new Car(3,"baoma3");
tmap1.put(car1,"c1");
tmap1.put(car2,"c2");
tmap1.put(car3,"c3");
System.out.println(tmap1);
//Car类的代码
public class Car implements Comparable<Car> {
private int no;
private String nam;
public Car(int no, String nam) {
this.no = no;
this.nam = nam;
}
@Override
public String toString() {
return "Car{" +
"no=" + no +
", nam='" + nam + '\'' +
'}';
}
@Override
public int compareTo(Car o) {
return this.no-o.no;
}
}
Map集合的遍历
1.通过Key对应的单列集合来进行遍历
2.使用Entry类进行遍历
Entry是专门用来遍历Map集合的类,可以存储键值对的信息,Entry类中含有getKey与getValue方法可以获取Map集合的key值和Value值
entrySet(),获得Entry类的Set集合
//Map集合遍历
HashMap<String,String> map=new HashMap<>();
map.put("a","aa");
map.put("b","bb");
map.put("c","cc");
/*
遍历方式1
通过单列集合遍历
keySet()方法获取键的单列集合,再通过键去遍历Map集合
*/
Set<String> set1=map.keySet();//获取键的一列
for (String set:set1) {
String value=map.get(set);
System.out.println(set +"="+ value);
}
/*
遍历方式2
通过Entry类的Set集合来遍历
*/
Set<Map.Entry<String,String>> entrymap=map.entrySet();
for(Map.Entry<String,String> set:entrymap){
System.out.println(set.getKey()+"="+set.getValue());//entry类中含有getKey与getValue方法可以获取值
}














 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









