









前言
这是一些对于论文《Faster Training of Very Deep Networks Via p-Norm Gates》的简单的读后总结,首先先奉上该文章的下载超链接:p范数门控
这篇文章是由Deakin University, Geelong Australia的Center for Pattern Recognition and Data Analytics部门的人员合作完成的,作者分别是Trang Pham、Truyen Tran、Dinh Phung和Svetha Venkatesh。其提出了p范数门控的思想,通过将普通门控(gates)改为p范数门控,使得网络能更快收敛且结果更好。
文章主要内容与贡献
该文章的贡献为:
- 提出了p范数门控。
提出了p范数门控
文中指出,带有门控的优秀网络——Highway Networks和GRU共同使用的一个约束就是:
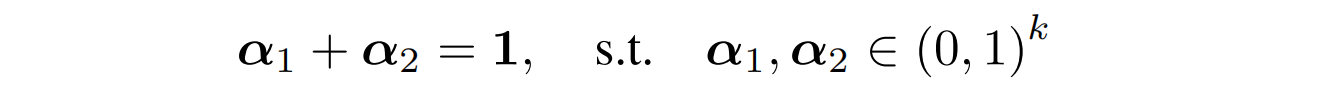
以此为引,作者尝试将该约束改为:
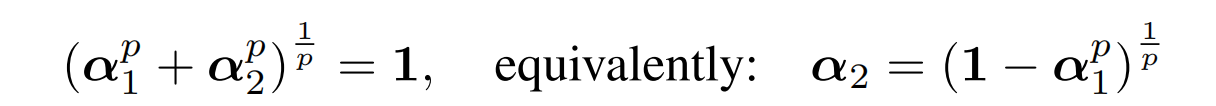
这样,固定
α
1
=
0.9
\alpha_1=0.9
α1=0.9,当
p
=
1
p=1
p=1时,
α
2
=
0.1
\alpha_2=0.1
α2=0.1;当
p
=
2
p=2
p=2时,
α
2
=
0.4359
\alpha_2=0.4359
α2=0.4359;当
p
=
5
p=5
p=5时,
α
2
=
0.865
\alpha_2=0.865
α2=0.865;当
p
→
∞
p\rightarrow\infty
p→∞时,
α
2
→
1
\alpha_2\rightarrow1
α2→1。即p越大,门控允许流过的信息就越多。
接下来简单的看一下实验:

上述实验是用换成p范数门控的Highway Networks来在两个大型UCI数据集:图(a)MiniBooNE粒子识别(MiniBooNE particle identification,MiniBoo)和图(b)无传感器驱动诊断(Sensorless Drive Diagnosis,Sensorless)上来做的实验。由上可知p在等于3时收敛最快计算结果最好,p在小于1时效果差。
下述实验室带p范数门控的GRU:

数据集是 UCI 路透社的数据集,其中包含 50 位作者的文章写作版画。图(a)是训练集上的学习曲线;图(b)是每字符位测量验证集的结果。可以看见由上可知p在等于3时收敛最快计算结果最好,p在小于1时效果差。















 4884
4884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









