 PoTion: 姿态运动表示
PoTion: 姿态运动表示








 本文总结了《PoTion:PoseMoTionRepresentationforActionRecognition》论文,介绍了一种新的行为识别方法PoTion。该方法利用人体关节热图,通过颜色编码时间信息,形成一种简洁的姿势运动表示。文中详细阐述了PoTion的提取、聚合方案及CNN架构,并通过实验验证了其有效性。
本文总结了《PoTion:PoseMoTionRepresentationforActionRecognition》论文,介绍了一种新的行为识别方法PoTion。该方法利用人体关节热图,通过颜色编码时间信息,形成一种简洁的姿势运动表示。文中详细阐述了PoTion的提取、聚合方案及CNN架构,并通过实验验证了其有效性。
行为识别I3D+PoTion《PoTion: Pose MoTion Representation for Action Recognition》读后总结
前言
这是一些对于论文《PoTion: Pose MoTion Representation for Action Recognition》的简单的读后总结,首先先奉上该文章的下载超链接:点击这里下载论文。
这篇文章是由Inria和NAVER LABS Europe的人员合作完成,作者分别是Vasileios Choutas、 Philippe Weinzaepfel、Jerome Revaud和Cordelia Schmid。该文章是UCF-101的榜首,其在HMDB51上排名第8。该文章仅于双流网络中多加入了一个PoTion流,使得网络性能得到了改善。
文章主要内容与贡献
该文章的贡献为:
- 提出PoTion;
- 针对PoTion设计了一个与之匹配的简单卷积神经网络;
- 做了多个实验验证PoTion的有效性。
提出PoTion
PoTion实际上是Pose moTion的一个结合,作者使用人体关节作为这些关键点和术语,即PoTion姿势运动表现。
下图是PoTion的获取方式以及结果:
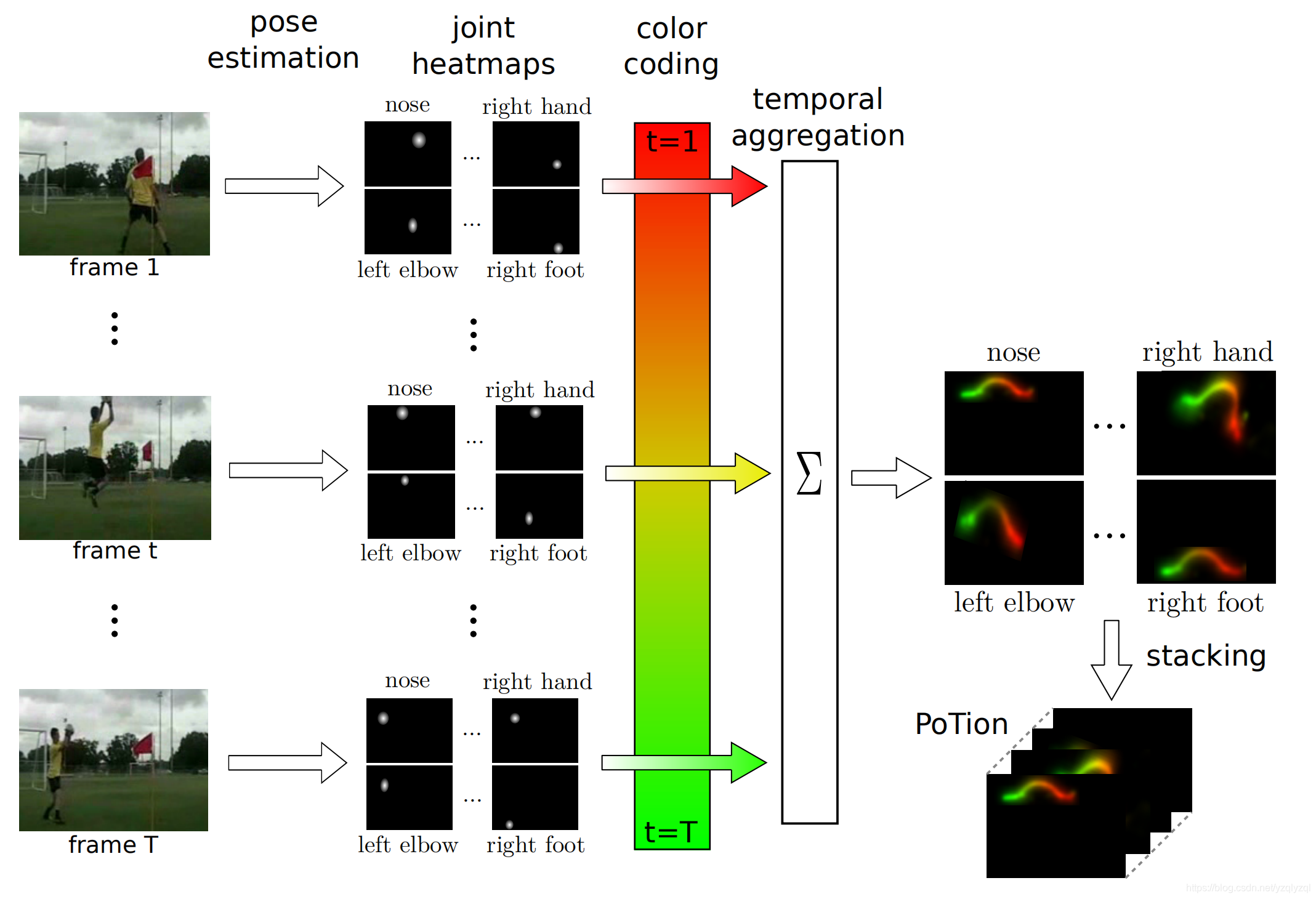
其将视频中人类的一些特定部位的运动轨迹分别分离出来,每个视频都有一组轨迹图,关键的一点就是作者使用颜色来区分轨迹的是怎样运动的。其主要思想是将第一帧染成红色,最后一帧用绿色着色,中间一帧用相同比例(50%)的绿色和红色着色。红色和绿色的确切比例是相对时间t的线性函数。
提取关节热图
提取关节热图部分,作者为每个视频帧运行 Part Affinity Fields
Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi-person 2D pose estimation using part affinity fields. In CVPR, 2017. 1, 2, 3, 7, 8
,在MS Coco数据集上对关键点定位任务进行了训练。Part Affinity Fields能处理多个人的存在,并且对遮挡和截断具有很强的鲁棒性。得到19个热图:18个人体关节各一个(4个四肢各3个,头部5个,身体中心1个),背景1个。用 H j t H^t_j Hjt表示帧t中连接j的热图。 H j t [ x , y ] H^t_j[x,y] Hjt[x,y]是像素 ( x , y ) (x,y) (x,y)在帧 t t t处包含连接 j j j的似然度。
聚合方案
其有三种不同的聚合方案,如下图所示:

对于在几个取样点(左图中的圆圈)观测到的联合j的轨迹,用C=3(最好用颜色观察)来说明不同的聚合方案(Uj、Ij和NJ)。作者提出了不同的彩色化方案(即
o
(
t
)
o(t)
o(t)的定义),对应于不同数目的输出通道C。对于C=2,有
o
(
t
)
=
(
t
−
1
T
−
1
,
1
−
t
−
1
T
−
1
)
o(t)=(\dfrac {t-1}{T-1},1-\dfrac {t-1}{T-1})
o(t)=(T−1t−1,1−T−1t−1),在时间
t
t
t处,像素
(
x
,
y
)
(x,y)
(x,y)和通道
c
c
c的连接点
j
j
j的彩色热图由以下方法给出:
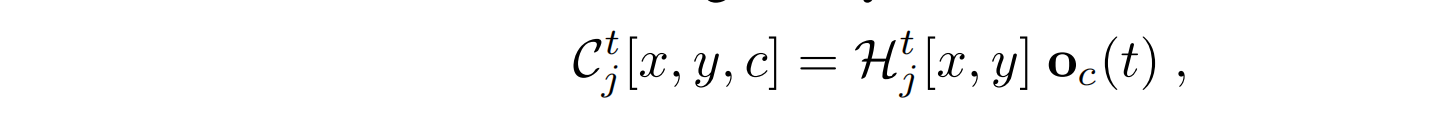
作者的目标是获得不依赖于视频剪辑持续时间的固定大小表示。因此用不同的方法对着色的热图进行聚集实验。首先计算每个关节j随时间变化的彩色热图之和,从而得到c通道图像
S
j
S_j
Sj:
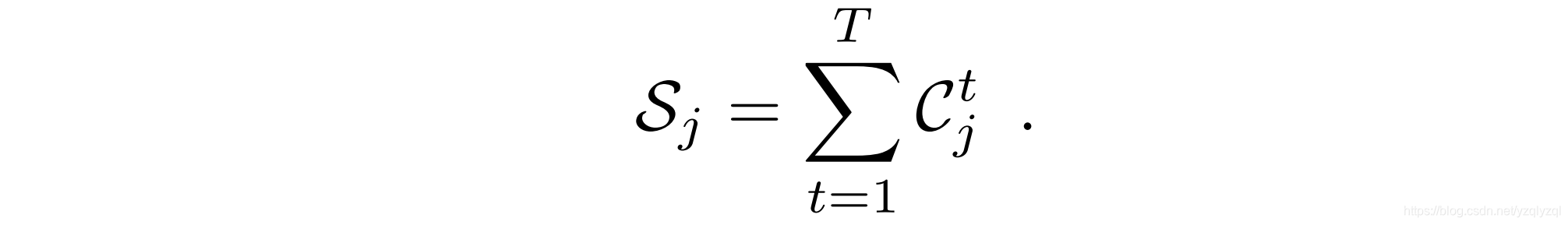
请注意,
S
j
S_j
Sj的值取决于帧T的数目。为了获得不变量表示,将每个通道c通过除以所有像素上的最大值独立地进行。当使用其他归一化时,实验观察到类似的性能,例如将每个通道除以
T
T
T或
∑
t
o
(
T
)
\sum_t{o}(T)
∑to(T)。如此获得了一个C通道图像
U
j
U_j
Uj,称为PoTion表示:
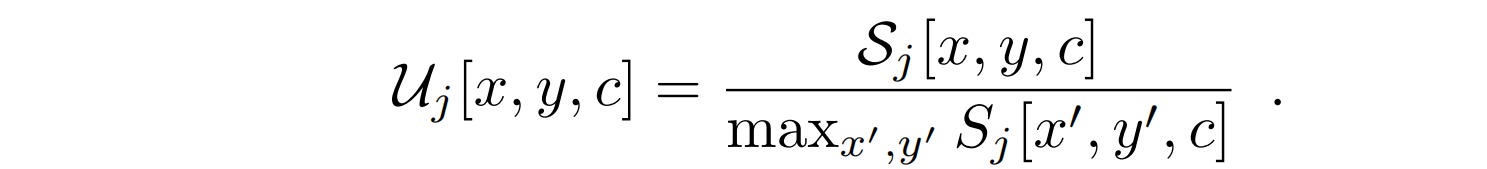
上图第二列显示左列上所示轨迹C=3的结果图像。可以观察到,关键点位置的时间演变是由颜色编码的。如果关节在给定的位置停留一段时间,就会积累更强的强度(轨道的中部)。这种现象可能是有害的,所以作者提出了第二种归一化强度的变体。
首先通过计算每个像素的所有通道的值来计算强度图像
I
j
I_j
Ij。
I
j
I_j
Ij是一个具有单一通道的图像:
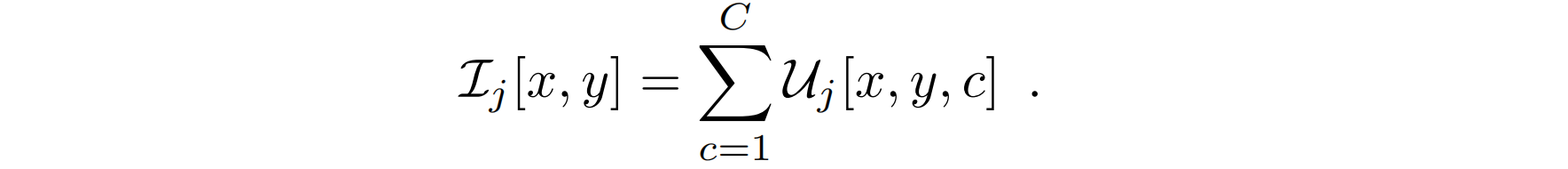
强度图像的示例如上图第三列所示,这种表示没有关于时间顺序的信息,但是编码了一个联合在每个位置停留的时间。通过将
U
j
U_j
Uj除以强度
I
j
I_j
Ij,现在可以得到规范化的PoTion表示。即一个如下的C通道图像
N
j
N_j
Nj:
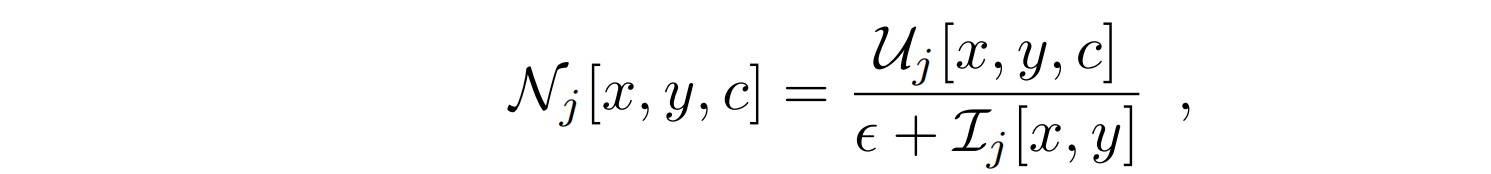
ϵ
=
1
\epsilon=1
ϵ=1避免分母为0。上图最右显示了N的一个示例。在这种情况下,所有位置的运动轨迹都是同等加权的,无论在每个位置花费的时间。实际上,轨迹中的瞬时停止比
U
j
U_j
Uj和
I
j
I_j
Ij中的其他轨迹位置加权得更多,
N
j
N_j
Nj消除了这种影响。
针对PoTion设计了一个与之匹配的简单卷积神经网络
由于PoTion结构简单且尺寸较小,因此作者设计了一个小型的卷积神经网络来训练PoTion,如下图所示:
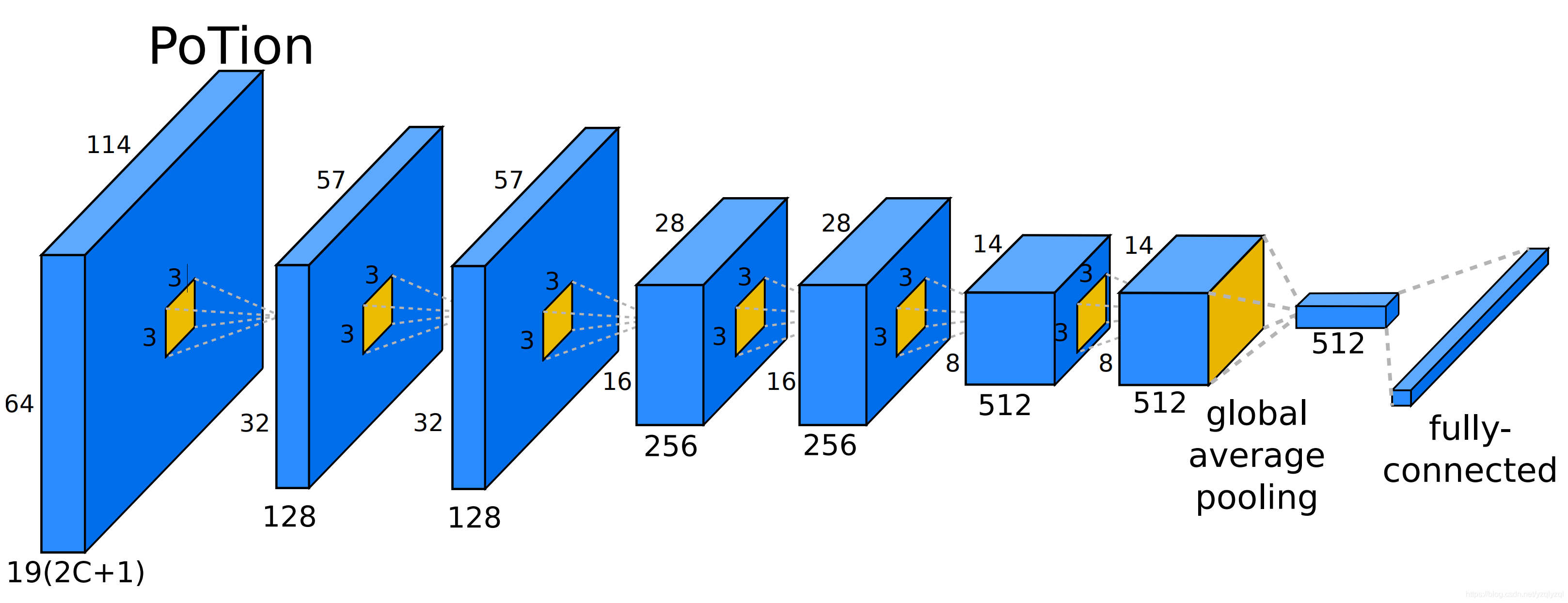
当堆叠
U
j
U_j
Uj,
I
j
I_j
Ij和
N
j
N_j
Nj的所有关节时,它有
19
×
(
2
C
+
1
)
19\times(2C+1)
19×(2C+1)个通道。19是联合热图的数目,
U
j
U_j
Uj,
I
j
I_j
Ij和
N
j
N_j
Nj分别具有
C
C
C、
1
1
1和
C
C
C个通道。
做了多个实验验证PoTion的有效性
PoTion参数实验
通道数量
首先研究了药剂表示中通道数的影响。下图显示了在改变颜色通道C的数量时,JHMDB和HMDB的第一次拆分的平均分类精度。
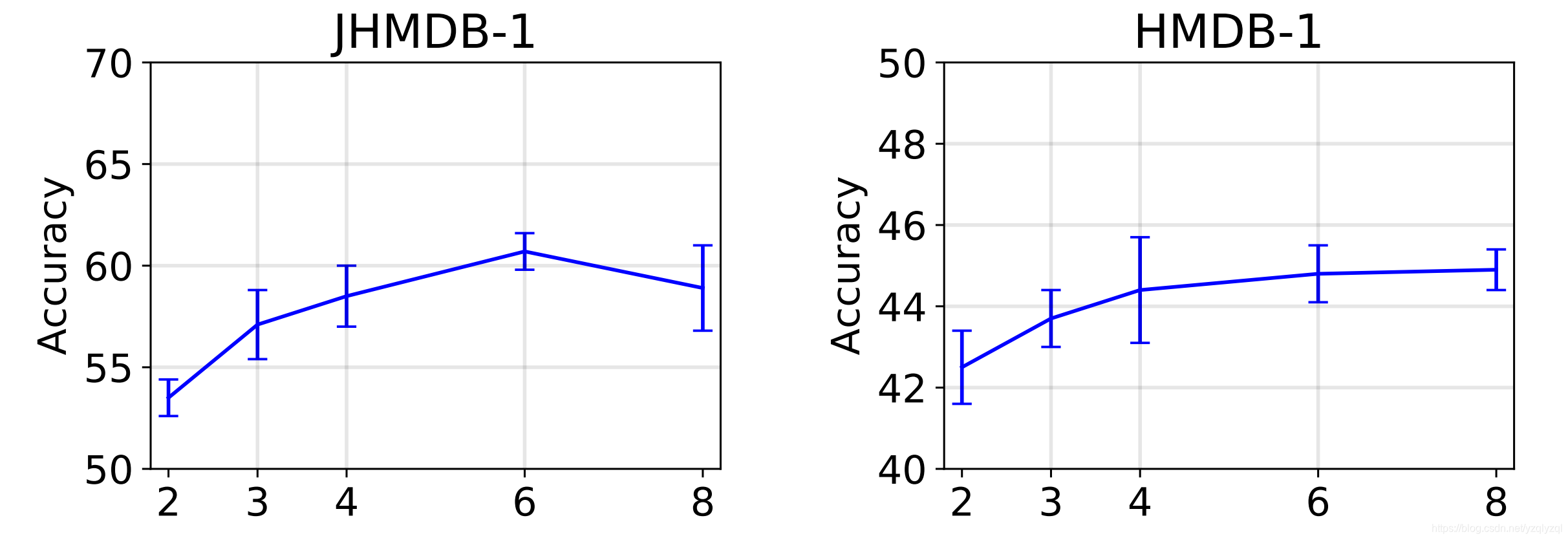
由上图可知,性能首先明显增加,直到
C
=
4
C=4
C=4为止。然后,在HMDB和JHMDB上,性能分别在
C
=
6
C=6
C=6或
C
=
8
C=8
C=8处饱和或下降。在其余的实验中,作者使用C=4,因为它是精确性和紧凑性之间的一个很好的折衷。
聚合技术
作者研究了不同聚合方案对PoTion表示的影响,首先用三种聚合技术训练不同的模型:
U
U
U、
I
I
I和
N
N
N,性能如下表所示:
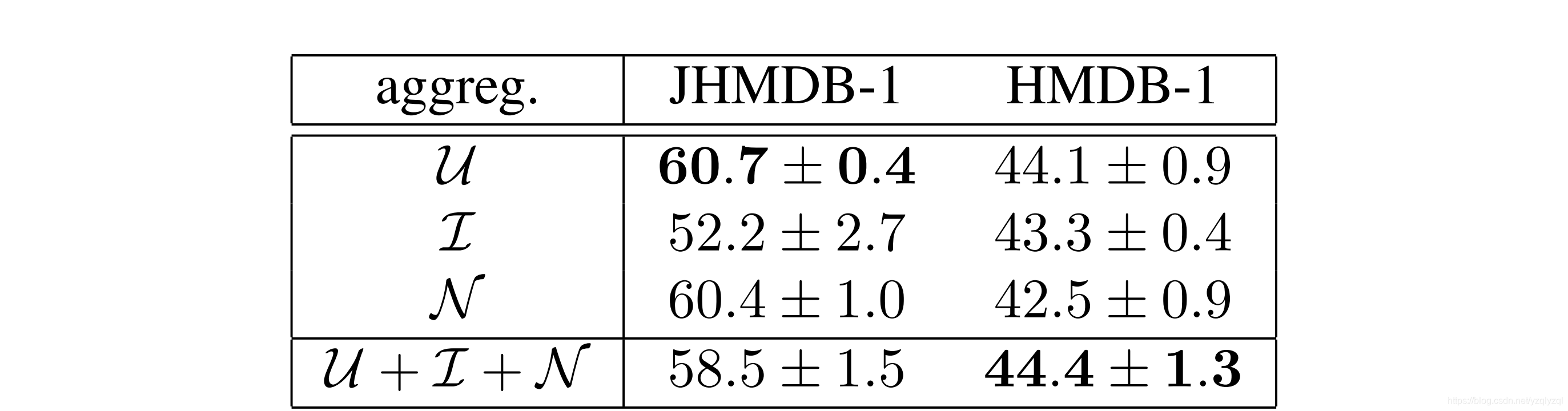
由上可知,对于小数据集JHMDB-1,
U
+
I
+
N
U+I+N
U+I+N略逊于
U
U
U和
N
N
N方案,对于稍大的HMDB,
U
+
I
+
N
U+I+N
U+I+N略优于单个的方案,考虑到后面的更大的数据集,因此在其余实验中,采用3种叠加聚合方案
U
+
I
+
N
U+I+N
U+I+N。
PoTion的CNN架构
数据增强
下表比较了在训练期间增加翻转数据的性能:

可以观察到,这种数据增强策略是有效的。特别是,在最小的数据集JHMDB上,准确率提高了7%。对较大的HMDB数据集(约1%)的影响不太重要。因此,在随后的所有实验中都使用翻转数据增强。
网络结构
比较了不同的网络架构。一个网络由几个block组成,其中的空间分辨率保持不变,如下表所示:
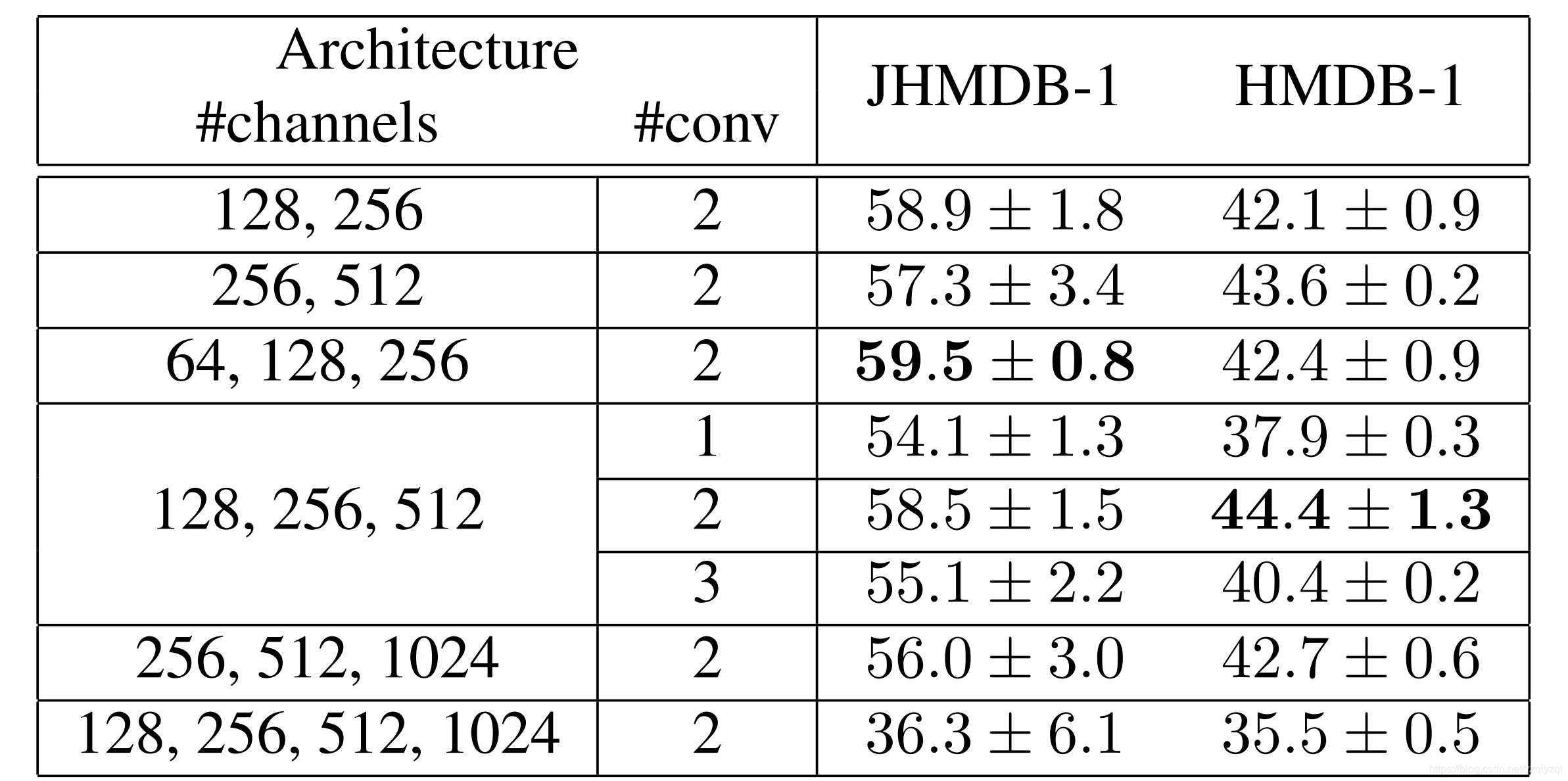
由上可知,网络太小导致大数据集过拟合严重,而网络过大导致欠拟合严重。因此选择了每个block 2层卷积层,3个block分别有128、256和512通道的卷积层。
姿态估计的影响
作者分析了由于姿态估计而产生的误差的影响。为了做到这一点,从JHMDB的带注释的木偶中获得了 ground truth 2D姿态,其中注释包括每个木偶关节的 x x x, y y y坐标。作者综合地从它们生成联合热图,类似于
Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi-person 2D pose estimation using part affinity fields. In CVPR, 2017. 1, 2, 3, 7, 8
在训练中使用的热图。
这些热图是通过将高斯集中在带注释的联合位置上得到的。请注意,木偶有15个关节,而Part Affinity Fields提取的热量图有19个。由下表可知:

使用木偶姿势在JHMDB上获得了大约4%的精度。同时试验了以木偶为中心的帧裁剪版本。此变体允许聚焦于演员并稳定视频,但是仅限于当我们知道是哪个演员在表演,并且我们能追踪到他时。后面的部分中GT-JHMDB指的是使用木偶造型与裁剪框架。
将该文提出的方法与最先进的方法进行了比较
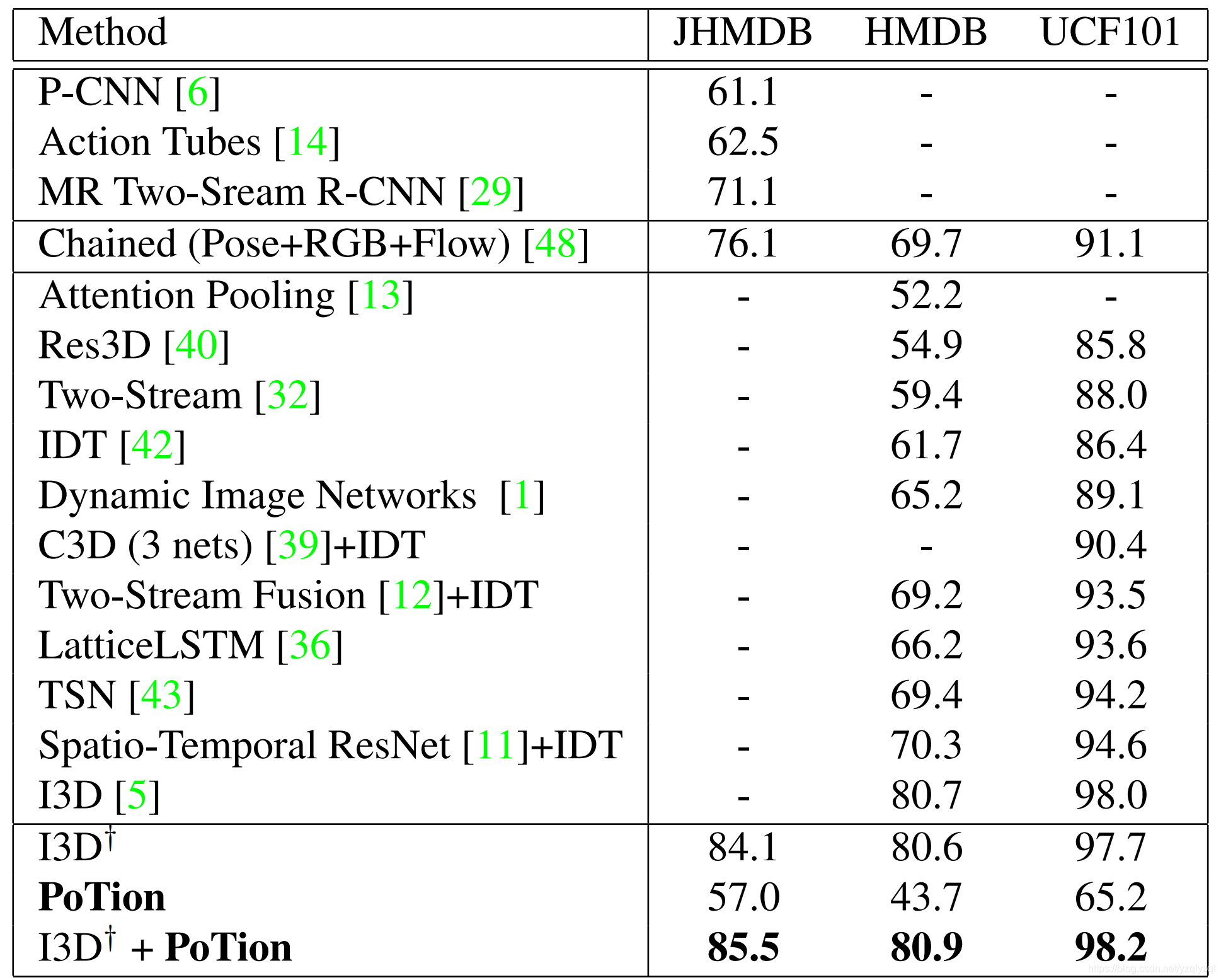
显而易见,I3D+PoTion的结果都是最好的。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









