






import re
import jieba
import numpy as np
from gensim.models import Word2Vec
import random
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm
# 设置随机种子,保证结果可复现
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
# 1. 数据加载与预处理
def load_and_preprocess_data(file_path):
# 读取文件
with open(file_path, "r", encoding="utf-8") as f:
text = f.read()
# 第一步: 保留中文和常见的标点
text = re.sub(r"[^\u4e00-\u9fa5,。!?;:]", "", text)
# 第二步: 按标点分割句子
raw_sentences = re.split(r"[,。!?;:]", text)
# 第三步: 过滤过短或过长的句子
sentences = [s.strip() for s in raw_sentences if 5 <= len(s.strip()) <= 20]
# 第四步: 区分五言和七言诗句
five_lines = [s for s in sentences if len(s) == 5]
seven_lines = [s for s in sentences if len(s) == 7]
return sentences, five_lines, seven_lines
# 2. 分词处理 - 使用字级别分词
def char_level_tokenize(sentences):
return [[char for char in sentence] for sentence in sentences]
# 3. 训练Word2Vec词向量模型
def train_word2vec_model(tokenized_sentences, vector_size=100, window=5, min_count=1):
model = Word2Vec(
tokenized_sentences,
vector_size=vector_size,
window=window,
min_count=min_count,
workers=4,
sg=1, # 使用Skip-gram模型
epochs=50 # 训练轮数
)
return model
# 4. 可视化词向量
def visualize_word_vectors(model, top_n=100):
words = list(model.wv.index_to_key[:top_n])
vectors = np.array([model.wv[word] for word in words])
# 使用PCA降维到2D
pca = PCA(n_components=2)
vectors_pca = pca.fit_transform(vectors)
# 使用t-SNE降维到2D
tsne = TSNE(n_components=2, perplexity=15, random_state=42)
vectors_tsne = tsne.fit_transform(vectors)
# 可视化
plt.figure(figsize=(16, 8))
plt.subplot(1, 2, 1)
plt.scatter(vectors_pca[:, 0], vectors_pca[:, 1], alpha=0.7)
for i, word in enumerate(words):
plt.annotate(word, (vectors_pca[i, 0], vectors_pca[i, 1]), fontsize=10)
plt.title('PCA Visualization of Word Vectors')
plt.subplot(1, 2, 2)
plt.scatter(vectors_tsne[:, 0], vectors_tsne[:, 1], alpha=0.7)
for i, word in enumerate(words):
plt.annotate(word, (vectors_tsne[i, 0], vectors_tsne[i, 1]), fontsize=10)
plt.title('t-SNE Visualization of Word Vectors')
plt.tight_layout()
plt.savefig('word_vector_visualization.png', dpi=300)
plt.show()
# 5. 构建诗词生成模型 - LSTM网络
class PoetryDataset(Dataset):
def __init__(self, poems, word2idx, seq_length=4):
self.poems = poems
self.word2idx = word2idx
self.seq_length = seq_length
self.data = []
self.target = []
# 构建训练样本
for poem in poems:
poem_ids = [word2idx.get(char, word2idx['<UNK>']) for char in poem]
for i in range(len(poem_ids) - seq_length):
self.data.append(poem_ids[i:i+seq_length])
self.target.append(poem_ids[i+seq_length])
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return torch.tensor(self.data[idx]), torch.tensor(self.target[idx])
class PoetryModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers=1):
super(PoetryModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(
embedding_dim,
hidden_dim,
num_layers=num_layers,
batch_first=True,
dropout=0.2 if num_layers > 1 else 0
)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden=None):
embed = self.embedding(x)
output, hidden = self.lstm(embed, hidden)
output = self.fc(output[:, -1, :])
return output, hidden
# 6. 训练诗词生成模型
def train_poetry_model(poems, word2vec_model, device='cpu', epochs=100):
# 构建词汇表
vocab = word2vec_model.wv.index_to_key
word2idx = {word: idx for idx, word in enumerate(vocab)}
word2idx['<UNK>'] = len(vocab) # 未知词
# 创建数据集和数据加载器
dataset = PoetryDataset(poems, word2idx)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
# 初始化模型
vocab_size = len(vocab) + 1 # 加上<UNK>
embedding_dim = word2vec_model.vector_size
hidden_dim = 256
model = PoetryModel(vocab_size, embedding_dim, hidden_dim, num_layers=2).to(device)
# 使用预训练的词向量初始化嵌入层
embedding_weights = torch.zeros(vocab_size, embedding_dim)
for word, idx in word2idx.items():
if word != '<UNK>' and word in word2vec_model.wv:
embedding_weights[idx] = torch.tensor(word2vec_model.wv[word])
model.embedding.weight.data.copy_(embedding_weights)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
model.train()
for epoch in range(epochs):
total_loss = 0
progress_bar = tqdm(enumerate(dataloader), total=len(dataloader))
for i, (inputs, targets) in progress_bar:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs, _ = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
progress_bar.set_description(f'Epoch {epoch+1}/{epochs}, Loss: {total_loss/(i+1):.4f}')
return model, word2idx
# 7. 生成古诗词
def generate_poetry(model, word2idx, idx2word, start_text='春', max_length=20, device='cpu'):
model.eval()
with torch.no_grad():
# 将起始文本转换为索引
if isinstance(start_text, str):
indices = [word2idx.get(char, word2idx['<UNK>']) for char in start_text]
else: # 假设是索引列表
indices = start_text
# 生成诗词
for i in range(max_length - len(start_text)):
input_tensor = torch.tensor([indices[-4:]]).to(device) # 取最后4个字符作为输入
output, _ = model(input_tensor)
# 采样下一个字符
probs = torch.softmax(output, dim=1)
next_idx = torch.multinomial(probs, 1).item()
indices.append(next_idx)
# 如果生成了句号,可能结束生成
if idx2word[next_idx] in ['。', '!']:
break
# 将索引转换回文本
return ''.join([idx2word.get(idx, '<UNK>') for idx in indices])
# 主函数
def main():
# 1. 加载和预处理数据
file_path = "./古诗词.txt"
sentences, five_lines, seven_lines = load_and_preprocess_data(file_path)
# 2. 分词处理
tokenized_sentences = char_level_tokenize(sentences)
# 3. 训练Word2Vec模型
word2vec_model = train_word2vec_model(tokenized_sentences, vector_size=100, window=3)
# 4. 可视化词向量
visualize_word_vectors(word2vec_model)
# 5. 训练诗词生成模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
poetry_model, word2idx = train_poetry_model(sentences, word2vec_model, device=device, epochs=50)
# 6. 生成古诗词示例
idx2word = {idx: word for word, idx in word2idx.items()}
for start_char in ['春', '夏', '秋', '冬', '月']:
poem = generate_poetry(poetry_model, word2idx, idx2word, start_char, device=device)
print(f"以 '{start_char}' 开头的诗词: {poem}")
# 7. 保存模型
word2vec_model.save("poetry_word2vec.model")
torch.save({
'model_state_dict': poetry_model.state_dict(),
'word2idx': word2idx
}, "poetry_generation_model.pth")
if __name__ == "__main__":
main()
代码功能说明
-
数据预处理:
- 保留中文和常见标点符号
- 按标点分割诗句
- 过滤过短或过长的句子
- 区分五言和七言诗句
-
字级别分词:
- 将每首诗拆分为单个字符列表
- 适合处理古诗词这种高度凝练的文本
-
Word2Vec 词向量训练:
- 使用 Skip-gram 模型学习每个汉字的向量表示
- 可配置向量维度、上下文窗口大小等参数
- 训练完成后可保存模型供后续使用
-
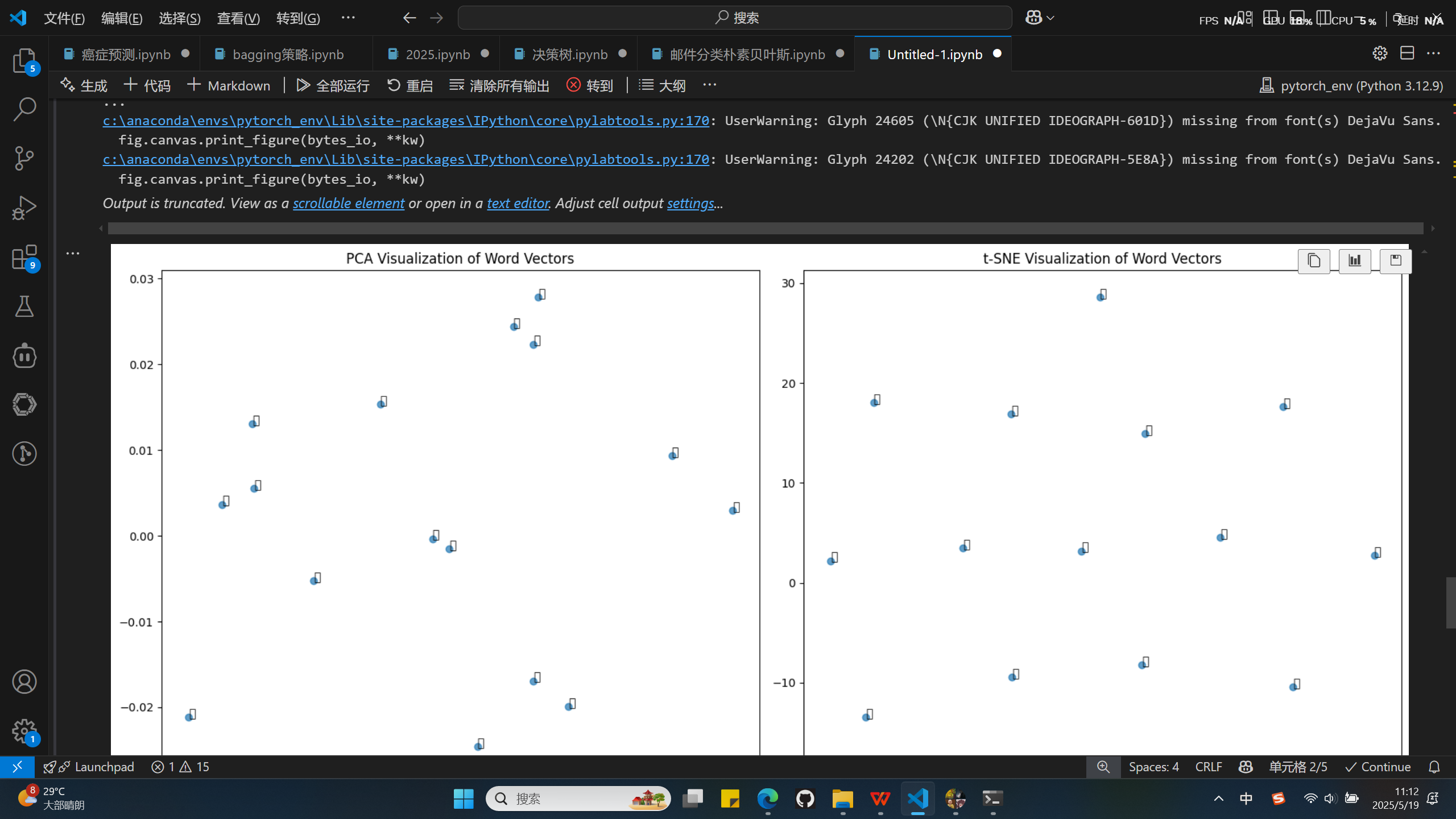
词向量可视化:
- 使用 PCA 和 t-SNE 两种降维方法可视化词向量
- 直观展示汉字之间的语义关系
-
古诗词生成模型:
- 使用 LSTM 网络构建序列生成模型
- 利用预训练的词向量初始化嵌入层
- 基于上下文预测下一个汉字
-
古诗词生成:
- 支持指定起始字符生成诗词
- 使用概率采样确保生成的多样性
- 可控制生成诗词的最大长度
使用说明
- 准备好古诗词文本文件(
古诗词.txt),每行一首诗 - 安装必要的依赖库:
plaintext
pip install jieba gensim matplotlib torch tqdm - 运行代码,程序将自动完成:
- 数据预处理
- 词向量训练与可视化
- 诗词生成模型训练
- 示例诗词生成




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











