







线性回归与逻辑回归
在本次学习中,以实践为主,简要阐述理论原理即可
1. 线性回归(LinearRegression)
1.1 理论
给定数据集D = { ( x 1 , y 1 ) , ( x 2 . y 2 ) , . . . , ( x m , y m ) (x_1, y_1), (x_2. y_2), ... , (x_m, y_m) (x1,y1),(x2.y2),...,(xm,ym)}, 其中 x i = ( x i 1 . x i 2 , . . . , x i d ) , y i ∈ R x_i = (x_{i1}. x_{i2}, ..., x_{id}), y_i \in R xi=(xi1.xi2,...,xid),yi∈R
- 目的:试图学得一个线性模型以尽可能准确的预测实值输出标记
- 模型的基本形式: f ( x ) = w x i + b f(x) = wx_i + b f(x)=wxi+b
- 常用指标:均方误差(基于均方误差最小化来进行模型求解的方法为"最小二乘法")
- 损失函数:通过使均方误差最小化得到的最小二乘损失函数
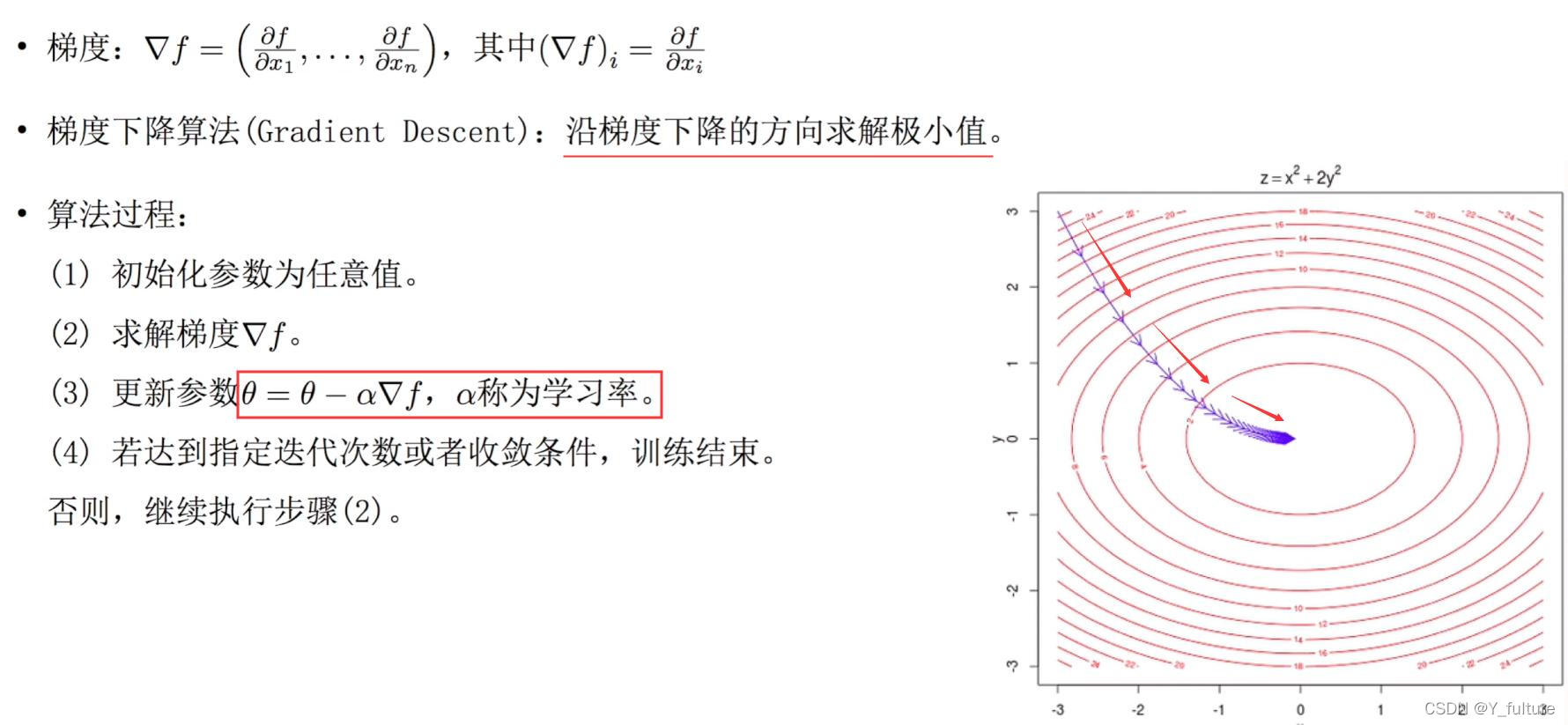
- 求解:通过梯度下降法求解出使损失函数最小时所对应的参数
- 梯度下降法的一般过程:
1.2 重要参数
| 参数 | 意义 |
|---|---|
| fit_intercept | 布尔值,可不填,默认为True 是否计算此模型的截距。如果设置为False,则不会计算截距 |
| normalize | 布尔值,可不填,默认为False。当fit_intercept设置为False时,将忽略此参数。如果为True,则特征矩阵X在进入回归之前将会被减去均值(中心化)并除以L2范式(缩放) |
| copy_X | 布尔值,可不填,默认为True。如果为真,将在X.copy()上进行操作,否则的话原本的特征矩阵X可能被线性回归影响并覆盖 |
| n_jobs | 用于计算的作业数 |
1.3 实践
以波士顿房价为例
- 导入相关的包
# 1. 导入相关的包
import numpy as np
import pandas as pd
- 导入数据集
# 2. 导入波士顿房价数据集
from sklearn.datasets import load_boston
# 3. 加载相关数据
data = load_boston()
X = data.data
y = data.target
- 划分训练集和测试集
# 3. 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size= 0.3, random_state = 0)
print(X_train.shape, X_test.shape,y_train.shape, y_test.shape)
- 导入模型并训练
# 4. 导入相关模型并训练
from sklearn.linear_model import LinearRegression
# 实例化
lr = LinearRegression()
# 训练
lr.fit(X_train, y_train)
# 输出对应线性回归的系数
print('线性回归的系数为:\n w = %s \n b = %s' % (lr.coef_, lr.intercept_))
- 利用学习好的模型进行预测
# 5. 利用学的模型进行预测
y_test_pred = lr.predict(X_test)
- 画出预测与真实值的图像
plt.figure()
plt.plot(y_test, c = 'r')
plt.plot(y_test_pred, c = 'b')
plt.show()

- 计算均方误差
from sklearn.metrics import mean_squared_error
mean_squared_error( y_test, y_test_pred)
结果为27.2
2. 对数几率回归(LogisticRegression,也被称为逻辑回归)
给定数据X = x 1 , x 2 , . . . , Y = y 1 , y 2 , . . . x_1, x_2, ... , Y = y_1, y_2, ... x1,x2,...,Y=y1,y2,...,考虑为二分类任务,即 y i ∈ 0 , 1 y_i \in 0, 1 yi∈0,1
2.1 理论
- 定义:是一种名为“回归”的线性分类器,其本质是由线性回
归变化而来的,一种广泛使用于分类问题中的广义回归算法。 - 目的:通过对线性模型进行Sigmoid变换完成分类任务
- 基本形式: h θ ( x ) = g ( θ T x ) h_{\theta}(x) = g(\theta^Tx) hθ(x)=g(θTx), 其中 θ T = w T x + b , g ( z ) = 1 1 + e − z \theta ^T = w^Tx + b, g(z) = \frac{1}{1 + e^{-z}} θT=wTx+b,g(z)=1+e−z1
- 损失函数:通过使用极大似然估计法定义损失函数
- 参数的求解:根据凸优化理论,可以使用梯度下降法得出最优解
2.2 LogisticRegression的优点:
- 对线性关系的拟合效果极好(特征与标签之前的线性关系极强的数据,比如金融领域中的信用卡欺诈、评分卡制作以及营销预测等)
- 计算速度快
- 返回的分类结果不是固定的0和1,而是以小数呈现出来的类概率数组
2.3 重要参数及其意义
| 参数 | 意义 |
|---|---|
| penalty | 可以通过输入’l1’或’l2’来指定使用哪一种正则化方式,默认为’l2’ |
| C | 正则化强度的倒数,必须是一个大于0的浮点数,不填写默认为1.0.越小,损失函数会越小。模型对损失函数的惩罚越重,正则化的效力越强 |
| max_iter | 整数,默认为100,求解器收敛的最大迭代次数 |
| multi_class | 输入"ovr"(二分类), “multinomial”(多分类), “auto”(根据数据的分类情况和其他参数来确定模型要处理的分类问题的类型)来告知模型处理的分类问题的类型,默认是"ovr" |
| solver | 求解参数的方法选择, |
| class_weight | 针对样本不均衡问题的参数,不过使用较难,一般采用上采样或下采样来解决样本不均衡问题 |
2.4 实践
以乳腺癌数据为例
- 导入相关的包
# 1. 导入相关的包
import numpy as np
import pandas as pd
- 导入数据集
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
X = data.data
y = data.target
- 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state = 0)
- 导入模型并训练
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression()
lgr.fit(X_train, y_train)
- 预测并查看得分
y_pred = lgr.predict(X_test)
score = lgr.score(X_test, y_test)
score
结果为0.947














 2347
2347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









