







中文乱码问题研究结论 java python
这些问题一直困扰我很久,其实也不是什么大问题,每次遇到也都能解决,但总是觉得没搞清楚,下次出现又抓瞎,索性花点时间争取弄懂它。网上的资料都很零散,感觉看懂了,但心中的疑惑只增不减。最终我还是梳理了一下,有了自己的理解,这里整理出我认为比较重要的地方,跟大家分享一下。废话不多说,开始。(以下内容,均为个人理解,有不准确和不全面的地方)
字库表?编码字符集?字符编码?
1.字库表:就是给人看的可见字符集合。字库表有很多种。
2.编码字符集:就是字库表里的字符与一组01序列一一对应的关系集合。
编码字符集有很多种,GBK,Unicode,ASCII。,我理解他们分别对应了三种不同的字库表(简单理解:GBK对应的字库表主要是中文,ASCII字库表主要是英文字符,Unicode字库表最全包含所有字符)
gbk编码字符集一部分:(除去首行守列剩下所有可见字符集合就是字库表)
更多gbk编码字符集内容见:https://yq.aliyun.com/articles/27446


当然Unicode也有他的字库表,我这里没有找到,上图可以知道中文“你好”这两个字符在gbk中的编码是0xc4e3,0xbac3.
python中对你好进行gbk编码:

3.字符编码:是将可见字符转换成01序列的规则(可以理解成算法),可理解为编码字符集里面包含的01序列在计算机上的具体存储方案,比如中文 “你” 在Unicode字符集下对应的01序列是0000 0000 0000 0000 0100 1111 0110 0000(\u4F60),采用UTF-8字符编码对中文“你”进行编码实际是为此序列提供一个存储方案,即不直接存储四个字节,而是改存三个字节:11100110 10001000 10010001(具体规则网上资料很多)
4.ASCII:它是编码字符集,同时也是一种字符编码(将ASCII编码字符集中的01序列原封不动的存储策略)
5.GBK:是编码字符集,同时也是一种字符编码,作为字符编码提供的规则应该也是一一对应,上面的几张图我们可以看到“你好”的中文经过gbk编码之后跟编码字符集里的01序列可以对应上。
6.UTF-8:是一种字符编码(采取可变长策略对Unicode的01序列提供存储方案)
7.Unicode:很多资料说他只是编码字符集,有些工具里面提供Unicode编码本质是一种UTF-16编码。姑且这么理解吧,还有就是java和Python的字符串在内存中都是以Unicode形式表示的,这里没有编码的概念,不存在程序里某个字符串是什么编码,可理解为就是字符本身,只有输出的时候才会涉及编码。
8.理解1:一种字符编码只对应一个编码字符集:字符编码看上去是将可见字符转换成01序列的一种策略,其实并不是作用在可见字符上,而是作用在编码字符集的01序列上(毕竟字符集编码只是一种算法,作用对象肯定就是机器可以识别的01序列)这点很重要,下面讲编码解码的时候重点说。
9.最后:字库表,编码字符集,字符编码这一套就是为了让机器可以处理可见字符。每一种字符处理方案都有一套自己的字库表,编码字符集合字符编码。我们给程序输入一个可见字符,首先程序要支持一套这样的字词处理规则,然后在编码字符集中找到字符对应的01序列,在通过字符编码,转换成可输出的01序列。
为了方便后面简单的把编码字符集里的01序列称之为某某序列(如gbk序列,就表示了gbk编码字符集里的01序列),把字符编码称之为某某算法(如gbk算法,指的就是gbk字符编码)
编码,解码
编码是将可读字符转化为二进制序列的过程(字符编码是一种存储策略)
解码是将二进制序列转化为可读字符的过程
- 将字符串以UTF-8编码 :即将字符串对应的unicode序列通过utf-8算法,转换成新的01序列,用于存储,注意编码只能是对字符串。
- 将字符串以GBK编码:将字符串对于的gbk序列通过gbk算法,转换成新的01序列,用于存储。
- 将字节流用UTF-8解码:解码其实就是编码的逆过程,对于utr-8解码来说就是把一段二进制序列通过utf-8算法还原成Unicode序列。
- 将字节流用GBK解码:将一段二进制序列通过gbk算法转换成gbk序列
- 因为上面说过java和python中的字符串都是Unicode,但是程序中可以直接将一个字符串按照gbk编码,看起来是直接把字符串变成了gbk,但gbk只能作用于gbk序列上。所以实际上程序内部提供了gbk与Unicode互转的机制,当我们使用gbk对字符串编码的时候,程序自动的将中文对应的Unicode先转换成gbk序列,在经过gbk算法得到最终可以输出的二进制序列。而程序中用gbk解码一个二进制流为字符存到变量的时候,其实是先通过gbk算法吧二进制流转换成gbk序列,然后自动把这个gbk序列转换成Unicode序列保存在内存中。
- 编码解码时机:无非就是在数据被读写的时候,一般程序要读一个数据的时候就会有解码操作,因为程序读的数据其实都是二进制序列。一般程序写出一个数据的时候就会有编码操作。
数据读,写
如果说数据在读写的时候会经历编码和解码的操作,这些地方都要用到编码解码方案,那一般什么地方会出现读写操作,下面整理一些场景。
-
读:一个数据进入每一个不同的程序的时候都有可能会经历读操作, 很多程序的界面显示信息的时候,对应的程序会读数据,如文件编辑器,各种远程连接程序的终端,cmd窗口,tomcat控制台,xshell控制台等。
我们程序里面获取外部数据的地方,如文件,网络,数据库,用户输入等
编译程序对源码进行编译时,如javac将java文本文件转换成二进制文件 -
写:数据在从每个不同的程序输出的时候也都要经历写操作, 程序写文件的时候,插入数据库的时候,输出到控制台的时候。
中文乱码
上面我们知道了一个可读字符,要存到计算机,就需要一套字库表,编码字符集,字符编码的支持。然而实际有很多套这样东西都在我们的计算机中,计算机都支持,而且不同的程序可能使用不同的字符处理方案。一个可读字符,最初可能就存在磁盘的某个地方,以某种编码的二进制保存着,然后这段二进制序列一个程序读到,又要往另外的点写一遍,这样这段信息要在很多程序之间传递,就经历了很多次编码解码。如果某个环节使用的解码与数据本身的编码方式不同可能出现乱码,导致最终结果乱码。
大部分的时候编码本身不会导致乱码,因为编码的时候我们输入的东西一般都是有意义的字符,数据首次存入
下面以UTF-8 和 GBK字符编码为例看看乱码是怎么发生的:
1.UTF-8编码用GBK解码
首先我们在UTF-8的文件中输入中文“你好”,然后保存(此过程就是编辑器使用UTF-8将这段可见字符进行了编码,存储在磁盘上)

1.1.通过nodpad++的插件HEX-Editor打开,看你好这两个字符的UTF-8编码结果:
e4 bd a0 ,e5 a5 bd,(UTF-8编码会把一个汉字变成三个字节)可以看到跟python程序中的输出结果一致(注意utf-8是要作用于Unicode序列才能得到正确结果,至于编辑器如果去到Unicode,猜想是根据我们输入的字符在对照Unicode编码字符集获取的,这一过程自动完成的,可能与操作系统、编辑器甚至输入法有关)


1.2.这时将文件编码方式改成gbk(编辑器中的ANSI在windows中应该就是gbk)[1]
可以发现这里就出现了乱码

1.3.我们在看看十六进制,发现依然还是那几个编码,可见通过编辑器改变文件的编码方式并没有改变原来存储的实际二进制内容,只是改变了编辑器的编码解码方式,如果我们再次输入中文就会以gbk来保存,但以前用utf-8编码的内容,会用gbk来解码,然后把解码后对应的字库表里的字符显示出来。gbk是两个字节表示中文,所以e4 bd a0 e5 a5 db 这一串会先进行gbk规则的解码,我发现gbk解码其实并为改变序列的内容,只是重新分组,两个字节为一组。所以gbk解码之后就是e4db,a0e5,a5db这三个序列,然后查找gbk编码字符集找到这三个序列对应的字符正好是:浣犲ソ


2.GBK编码用UTF-8解码
之前我们已经知道“你好”的gbk编码是0xc4e3,0xbac3 ,gbk编码的你好用utf-8解码后发现编辑器里是下图这样的,直接显示了编码,还是gbk的编码。在python这样做会直接报错,java里会得到三个相同的特殊问号字符。原因也很好理解,UTF-8解码并不像gbk只对二进制重新分组,UTF-8需要根据二进制的内容去解析成一个Unicode序列,而这个二进制内容不再UTF-8可识别的范围内,所以就无法解码,就算碰巧UTF-8可以识别,那解析出来的Unicode序列对应的可读字符也早已不是原来的字符。


分析一个java代码输出乱码的实例
环境:win10 , jdk8
1.将中文写入文件一段简单的java代码,输出中文“你好”,源文件是UTF-8编码,在磁盘上实际存储为:e4 bd a0 e5 a5 db


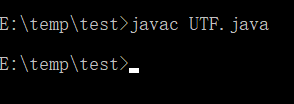
2.javac读取java源文件,写出class文件
直接使用javac编译成class.(采用系统默认字符编码GBK读取源文件)
推测1:javac程序使用GBK解码读取UTF-8的源文件,在通过GBK编码之后存储为class.“你好”的二进制序列不变.
但是,经过研究发现class文件里面“你好”被写成9个字节,正好是:“浣犲ソ”的UTF-8编码。后来发现class文件常量池对字符串一定是使用UTF-8存储的,编译class的时候会有验证,假如一个字符串以GBK编码,而这个编码正好不能用UTF-8解码,那javac会报错。

由此可以得出结论1:javac确实使用GBK读取了java文件,读取之后javac认为“你好”的UTF-8编码代表的是三个字符(浣犲ソ),javac写class文件的时候又把这三个字符用UTF-8编码写入了class文件的常量池中。由于UTF-8编码必须作用于“浣犲ソ”的Unicode(6d63 72b2 30bd)上才能得到e6 b5 a3 e7 8a b2 e3 82 bd
所以javac中会把“浣犲ソ”的GBK编码先转换成Unicode,在编码成UTF-8,输出到class文件。(如果javac启动时设置-encoding utf-8参数,class文件里的内容才是“你好”的utf-8编码)
(
*“你好”:
UTF-8编码e4 bd a0 e5 a5 db,
Unicode序列4f 60 59 7d
GBK编码c4e3,bac3
“浣犲ソ”:
Unicode序列6d63 72b2 30bd
GBK编码=“你好“的UTF-8编码
应该是class文件已经不是对java语法的简单映射
UTF-8编码:e6 b5 a3 e7 8a b2 e3 82 bd )
3.jvm加载class(读):
默认编码是GBK
如果jvm使用单纯GBK来读取class,那么上述class文件中的9个字节最终会解码成4个半字符,就像这样:
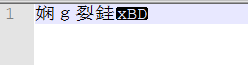
我们知道jvm中的字符串都是Unicode形式,一定是先把class文件中的编码按照某种方式解码成可读字符,在找到可读字符的Unicode存储起来。
我们把这个Unicode通过UTF-8解码出来看看他到底存的是什么:

循环中的打印结果是
这正好是浣犲ソ的UTF-8编码的十进制表示
如果s在内存中不是6d63 72b2 30bd(浣犲ソ的Unicode),那我们用UTF-8解码得到的bytes一定不是e6 b5 a3 e7 8a b2 e3 82 bd
而jvm能找到“浣犲ソ”这三个可读字符对应到Unicode,一定class中的e6 b5 a3 e7 8a b2 e3 82 bd使用了UTF-8进行解码。
不管使用哪种字符集设置jvm的启动参数,s变量都是一样的:
图 
由此可以推测:jvm在加载class的常量池时候都是使用UTF-8,可能与生成class里的常量字符都是以UTF-8编码有关。
4.jvm输出到cmd(写),cmd显示(读)
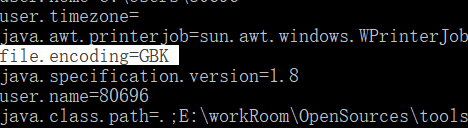
在代码中调用System.out.println()将变量输出到控制台,其实是将变量进行编码之后写入控制台程序。这个可以跟踪调试来验证,而默认编码方式可以使用jvm启动参数-Dfile.encoding来改变,不设置参数就是系统默认字符集(Windows是GBK)设置一个不存在的字符集就会使用utf-8.
windows下控制台默认编码方式是GBK
这个过程其实就是jvm先将一串编码发送给cmd,cmd在解码显示
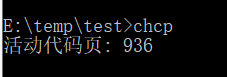
为了看的更清楚,我们吧程序修改一下

但是不管我们用gbk还是utf-8启动jvm在chcp 936下 cmd(GBK)打印的结果都是“浣犲ソ”。
不带参的启动方式好解释,就是jvm把“浣犲ソ”用gbk编码输出到cmd,cmd在用gbk解码出来。
通过utf-8启动的程序,输出结果就无法解释,明明jvm给cmd输出了“浣犲ソ”的UTF-8编码,cmd用gbk解码为何还是输出“浣犲ソ”。而且chcp936确实也不能支持utf-8的中文,可用utf-8的bat程序执行中文回显来验证。可能chcp 936里面还有什么其他机制,如果谁知道烦请告诉我一下,不胜感激!另外python3不管是gbk还是utf-8的脚本执行输出在gbk和utf-8的控制台都不会乱码。

而在chcp 65001活动页下运行的结果就很好解释:
gbk启动,jvm用gbk将“浣犲ソ”编码,发送给cmd(UTF-8),cmd用UTF-8解析之后正好是“你好”。
utf-8启动,jvm用utf-8将“浣犲ソ”编码,发送给cmd(UTF-8),cmd用UTF-8解析之后正好是“浣犲ソ”。

[1]: Windows 里说的「ANSI」其实是 Windows code pages,这个模式根据当前 locale 选定具体的编码,比如简中 locale 下是 GBK。把自己这些 code page 称作「ANSI」是 Windows 的臭毛病。在 ASCII 范围内它们应该是和 ASCII 一致的。















 4516
4516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









