







 本文介绍了机器学习中的决策树模型,它是一种基于对象属性的映射关系预测模型。内容涉及决策树的节点类型(决策节点、机会节点、终结点)、熵的概念及其计算公式,并通过Python代码展示了数据集的创建过程。
本文介绍了机器学习中的决策树模型,它是一种基于对象属性的映射关系预测模型。内容涉及决策树的节点类型(决策节点、机会节点、终结点)、熵的概念及其计算公式,并通过Python代码展示了数据集的创建过程。
有不足之处,请大家指正,谢谢!
机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。 数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表式
- 机会节点:通常用圆圈来表式
- 终结点:通常用三角形来表示

以上资料参考http://zh.wikipedia.org/wiki/决策树
构造决策树,我们需要找到决定性的特征,以划分最好的结果,因此,需要对每个特征进行评估,如果某个特征的信息增益最大,那么该特征就是最好的分离点。
1、
如果检测数据集中子项是否属于一类,则返回该子类标签;
2、否则,寻找该子类中的最好特征,划分数据,创建支点;
3、返回步骤1,继续检测下一支点;
熵的定义如下:(参考http://zh.wikipedia.org/wiki/信息熵)
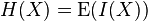 ,
,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2921
2921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









