






- 环境
| Python版本 | 操作系统 | 浏览器 | 编程环境 |
|---|---|---|---|
| Python 3.8.9 | Macos | Chrome | vscode |
-
版权申明
本文将会通过爬虫的方式实现简单的百度翻译。本文中的代码只供学习,不允许作为于商务作用。商务作用请前往 api.fanyi.baidu.com 购买付费的 api。若有侵犯,立即删文!
-
实现思路
在网站文件中找到隐藏的免费 api。传入 api 所需要的参数并对其发出请求。在返回的 json 结果里找到相应的翻译结果。
百度翻译的反爬机制
-
由 js 算法生成的 sign
-
cookie 检测
-
token 暗号
在网站文件中找到隐藏的免费 api
进入百度翻译,随便输入一段需要翻译的文字。当翻译结果出来的时候,按下 F12,选择到 NETWORK,最后点进Fetch/XHR 文件。从左边Name列表中可以发现一个以 v2transapi? 开头的文件,这就是我们要找的 api 接口。让我们验证一下,点进去文件 - preview,我们就可以在 json 格式的数据里面找到翻译结果,验证成功。
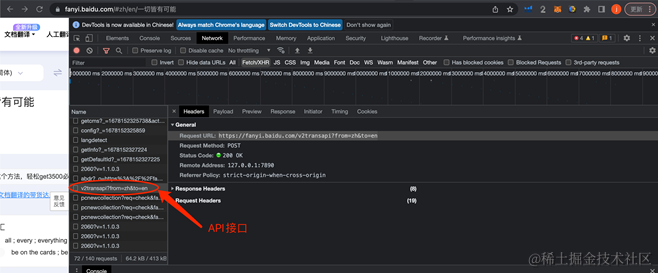
另外,我们还需要获取我们的 User-Agent、cookie 和 token,在之后的反爬机制中我们需要用到它们,位置如以下。
cookie 位置:
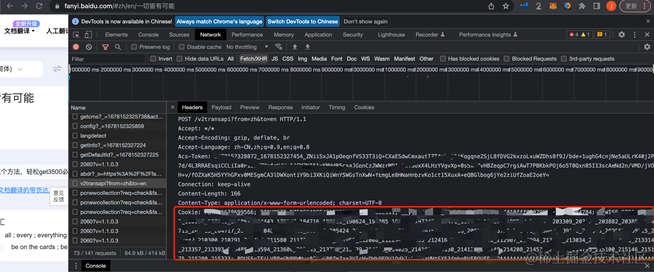
token 位置:

api 信息
接口:https://fanyi.baidu.com/v2transapi
请求方式:post
请求参数大全
| 参数 | 介绍 |
|---|---|
| from | 源语言 |
| to | 目标语言 |
| query | 翻译文本 |
| sign | 百度js算法通过输入的api key和query生成 |
- js算法是从网上找到的,可直接保存为baidufanyi.js文件来调用
var i = "320305.131321201"
function n(r, o) {
for (var t = 0; t < o.length - 2; t += 3) {
var a = o.charAt(t + 2);
a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a), a = "+" === o.charAt(t + 1) ? r >>> a : r << a, r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a
}
return r
}
function e(r) {
var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);
if (null === o) {
var t = r.length;
t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr(-10, 10))
} else {
for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++) "" !== e[C] && f.push.apply(f, a(e[C].split(""))), C !== h - 1 && f.push(o[C]);
var g = f.length;
g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice(-10).join(""))
}
var u = void 0, l = "" + String.fromCharCode(103) + String.fromCharCode(116) + String.fromCharCode(107);
u = null !== i ? i : (i = window[l] || "") || "";
for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {
var A = r.charCodeAt(v);
128 > A ? S[c++] = A : (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128)
}
for (var p = m, F = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(97) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(54)), D = "" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(51) + ("" + String.fromCharCode(94) + String.fromCharCode(43) + String.fromCharCode(98)) + ("" + String.fromCharCode(43) + String.fromCharCode(45) + String.fromCharCode(102)), b = 0; b < S.length; b++) p += S[b], p = n(p, F);
return p = n(p, D), p ^= s, 0 > p && (p = (2147483647 & p) + 2147483648), p %= 1e6, p.toString() + "." + (p ^ m)
}
- 编码
-
安装execjs
pip3 install PyExecJS
-
python调用代码
import requests
import json
import execjs
# UA伪装-让爬虫对应的请求载体身份伪装成浏览器
# User-Agent-请求整体的身份标识
if __name__ == "__main__":
headers = {
"User-Agent": "上文获取到的UA",
"cookie": "上文获取到的cookie",
}
url = "<https://fanyi.baidu.com/v2transapi>"
# 处理url携带post参数,封装到字典中
query_string = input("enter a word: ")
#读取js文件并调用函数生成sign
with open("./baidufanyi.js", "r", encoding="utf-8") as f:
ctx = execjs.compile(f.read())
sign = ctx.call("e", query_string)
# print("sign:" + sign)
data = {
"query": query_string,
"simple_means_flag": 3,
"sign": sign,
"token": "上文获取到的token",
"domain": "common",
"from": "zh",
"to": "en",
}
# 4. 请求发送
response = requests.post(url, data=data, headers=headers)
dic_obj = response.json()
text = dic_obj["trans_result"]["data"][0]["dst"]
print(text)
# 持久化存储
fileName = "fanyi" + query_string
fp = open(fileName, "w", encoding="utf-8")
json.dump(dic_obj, fp=fp, ensure_ascii=False)
问题汇总
-
execjs._exceptions.ProcessExitedWithNonZeroStatus: (1, ‘’, ‘The operation couldn’t be completed. Unable to locate a Java Runtime that supports jjs.\nPlease visit http://www.java.com for information on installing Java.\n\n’)
–从oracle官网下载jdk1.8.0安装,并确认/Library/Java/JavaVirtualMachines/jdk1.8.0_361.jdk/Contents/home/bin 目录下存在 jjs 文件
-
python 執行 execjs 出現錯誤 UnicodeEncodeError: ‘utf-8’ codec can’t encode character ‘\ufffd’
– 可通过将js脚本单独存放在js文件中,然后python引用来解决编码问题
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓
最新全套【Python入门到进阶资料 & 实战源码 &安装工具】(安全链接,放心点击)
















 2036
2036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









