






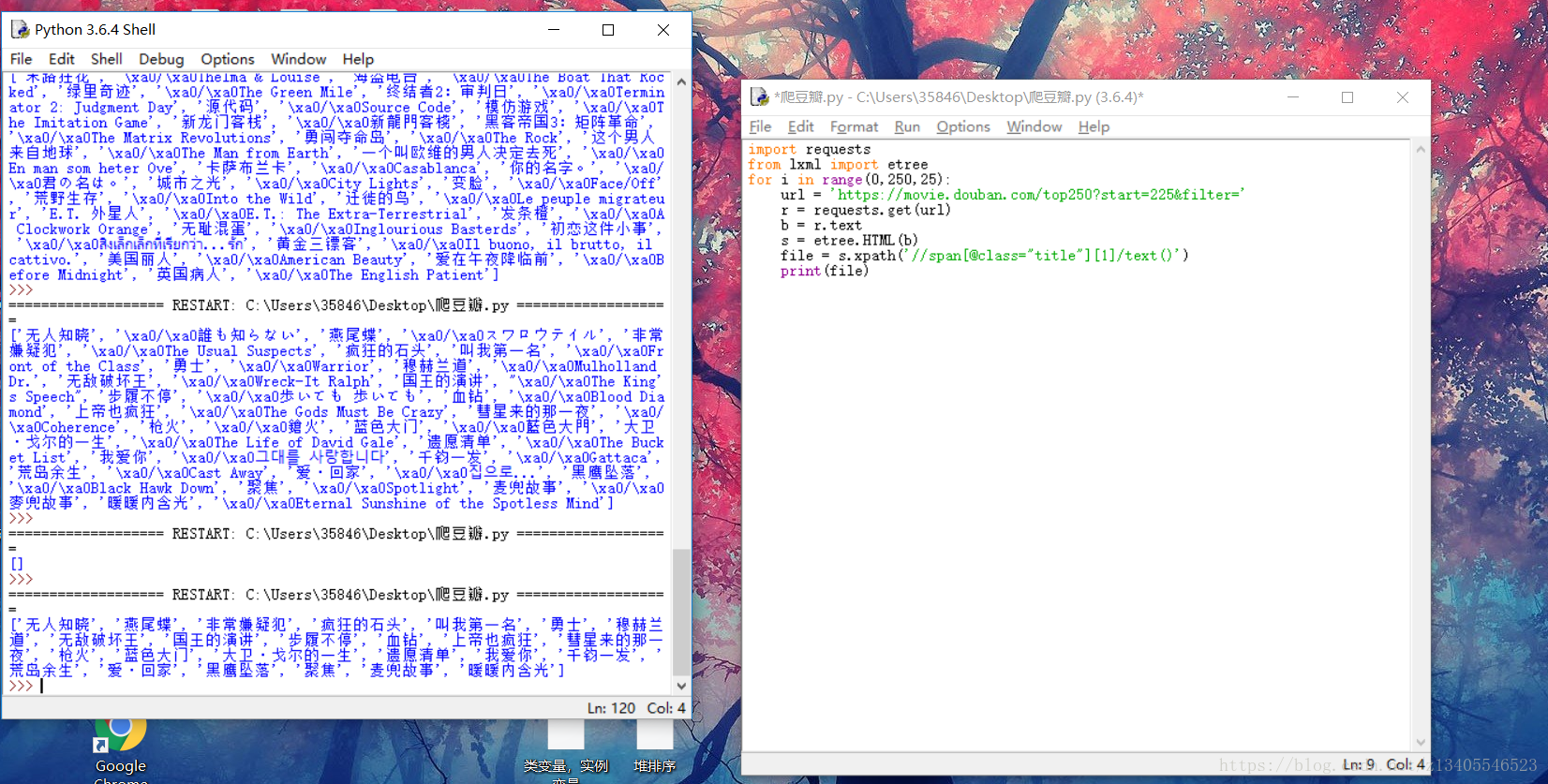
import requests
from lxml import etree
for i in range(0,250,25):
url = 'https://movie.douban.com/top250?start=%s&filter='%i
r = requests.get(url)
b = r.text
s = etree.HTML(b)
file = s.xpath('//span[@class="title"][1]/text()')
from lxml import etree
for i in range(0,250,25):
url = 'https://movie.douban.com/top250?start=%s&filter='%i
r = requests.get(url)
b = r.text
s = etree.HTML(b)
file = s.xpath('//span[@class="title"][1]/text()')
print(file)
在xpan处折腾了好久,各找查资料,然后试了两拨,先是没有【1】返回两种值,加上就是一种了,要是能在处理一下就完美了
















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









