






WordNet学习_1
一、WordNet基本使用
NLTK是python的一个自然语言处理工具,其中提供了访问wordnet各种功能的函数。
例如:
#词集是单词的一个含义(一个含义可能由很多单词表示),我们用synsets指令查看dog的所有同义词集(pos值可以为——NOUN,VERB,ADJ,ADV…)
wn.synsets("car",pos=wn.NOUN)
>>>[Synset( "car.n.01" ), Synset("car.n.02"), Synset("car.n.03"), Synset("car.n.04"), Synset ("cable_car.n.01")]
#其中,"car.n.01"表示car在名词中的第一个含义。每个意思的具体含义可以按如下方法查看
for synset in wn.synsets("car"):
... print(synset.definition())
#同时,一个含义可能对应了多个单词,因而可以找到含义对应的多个词条(lemma,某含义所对应的具体一个单词),可以用以下方法查询词集对应的多个词条(同义词)
wn.synset('dog.n.01').lemma_names( )
>>>['dog', 'domestic_dog', 'Canis_familiaris']
wn.synset('dog.n.01').lemmas( )
>>>[Lemma('dog.n.01.dog'),Lemma('dog.n.01.domestic_dog'),Lemma('dog.n.01.Canis_familiaris')]
#对于名词,WordNet认为词集(含义)之间呈树形结构,因而词集有上位词与下位词,查看方法为
dog = wn.synset('dog.n.01') # 创建词集对象
dog.hypernyms() # 上位词集(父类)
>>>[Synset('canine.n.02'), Synset('domestic_animal.n.01')]
dog.hyponyms() # 下位词集(子类)
>>>[Synset('basenji.n.01'), Synset('corgi.n.01'), ...]
#WordNet提供了两个词集之间的相似度(0~1,越大相似度越高)
dog = wn.synset('dog.n.01')
cat = wn.synset('cat.n.01')
dog.path_similarity(cat)
>>>0.2
#由于是树状结构可以查看他们的最低共同祖先
dog.lowest_common_hypernyms(cat)
>>>[Synset('carnivore.n.01')]
#对于动词,词之间的关系主要表现为蕴含关系,例如:
wn.synset('walk.v.01').entailments()#走路蕴含着抬脚
>>>[Synset('step.v.01')]
#对于形容词和副词,他们没有被组织成分类体系,也不能用path_distance查看相似度。形容词和副词最有用的关系是similar to。
beau.similar_tos()
>>>[Synset('beauteous.s.01'), Synset('bonny.s.01'), Synset('dishy.s.01'), Synset('exquisite.s.04'), Synset('fine-looking.s.01'), Synset('glorious.s.03'), Synset('
gorgeous.s.01'), Synset('lovely.s.01'), Synset('picturesque.s.01'), Synset('pretty-pretty.s.01'), Synset('pretty.s.01'), Synset('pulchritudinous.s.01'), Synset('ravishing.s.01'), Synset('scenic.s.01'), Synset('stunning.s.04')]
#其他词集之间的关系还有,部分、实质、集合等关系,示例如下。由于这些关系不是(NLP门外汉)最常用的,也不太好理解,不展开描述,具体关系的含义可以参考:https://blog.csdn.net/sinat_22581761/article/details/78577618
wn.synset('tree.n.01').part_meronyms() #tree的部件(条目-部件)
>>>[Synset('burl.n.02'), Synset('crown.n.07'), Synset('limb.n.02'),
Synset('stump.n.01'), Synset('trunk.n.01')]
wn.synset('tree.n.01').substance_meronyms() #tree的实质(条目-实质)
>>>[Synset('heartwood.n.01'), Synset('sapwood.n.01')]
wn.synset('tree.n.01').member_holonyms() #tree集合是森林
>>>[Synset('forest.n.01')]
wn.synset('burl.n.02').part_holonyms() #由上边第一行代码的输出结果可知'burl.n.02'是'tree.n.01'的一个部件,因此burl的整体是tree无疑
>>>[Synset('tree.n.01')]
wn.synset('heartwood.n.01').substance_holonyms()#同理,heartwood是tree的一个实质,其整体也是tree无疑
>>>[Synset('tree.n.01')]
#词条(lemma)之间的关系
#词条之间的关系即同义词/反义词,同义词查询上文已经介绍过,反义词查询方法为
wn.lemma('hot.a.01.hot').antonyms()
>>>[Lemma('cold.a.01.cold')]
二、WordNet基本结构
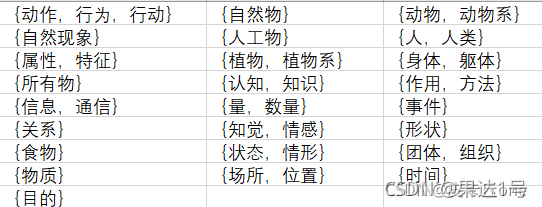
(1)独立起始概念(Unique Beginner)
如果有一同义词集合(即 概念)没有上位同义词集合(即 上位概念),则称之为独立起始概念(Unique
Beginner)。在WordNet名词体系中,共有25个独立起始概念。其他名词通过上位/下位关系与这25个独立起始概念构成25个独立的层次结构。也就是说,标识着某个起始概念特点的属性将它的所有下位概念所继承,而这个起始概念就可以看作为是该语义领域内的所有概念(同义词集合)的一个原始语义元素。
如下表所示:
(2) 词典编撰ID(Lexicographer ID)
每一个同义词集合(synonymy set)均有惟一的一个编号,这个编号就称为词典编撰ID(Lexicographer ID)。
(3) 概念链(Concept Chain)
在WordNet名词体系中,我们定义概念链(Concept Chain)如下:
:=((C,<)
概念链的首端对应的就是WordNet中的独立起始概念。比如:概念链ch1可以表示为:(3255461)<(2681909)<(3289024)<(3174243)<(3443493)<(19244)<(2645)<(16236)<(1740)。其中(3255461)作为概念链的末端代表的是词“football”的一个义项,而(1740)是WordNet中的独立起始概念,成为概念链的首端。概念“game equipment”(3289024)是概念“ball”(2681909)的上层概念,表达的语义更抽象。
三、WordNet代码解析
在整个wordnet库中,几乎都在实例化LazyCorpusLoader类
例如:
abc = LazyCorpusLoader(
"abc",
PlaintextCorpusReader,
r"(?!\.).*\.txt",
encoding=[("science", "latin_1"), ("rural", "utf8")],
)
alpino = LazyCorpusLoader("alpino", AlpinoCorpusReader, tagset="alpino")
brown = LazyCorpusLoader(
"brown",
CategorizedTaggedCorpusReader,
r"c[a-z]\d\d",
cat_file="cats.txt",
tagset="brown",
encoding="ascii",
)
cess_cat = LazyCorpusLoader(
"cess_cat",
BracketParseCorpusReader,
r"(?!\.).*\.tbf",
tagset="unknown",
encoding="ISO-8859-15",
)
cess_esp = LazyCorpusLoader(
"cess_esp",
BracketParseCorpusReader,
r"(?!\.).*\.tbf",
tagset="unknown",
encoding="ISO-8859-15",
)
cmudict = LazyCorpusLoader("cmudict", CMUDictCorpusReader, ["cmudict"])
comtrans = LazyCorpusLoader("comtrans", AlignedCorpusReader, r"(?!\.).*\.txt")
comparative_sentences = LazyCorpusLoader(
"comparative_sentences",
ComparativeSentencesCorpusReader,
r"labeledSentences\.txt",
encoding="latin-1",
)
conll2000 = LazyCorpusLoader(
"conll2000",
ConllChunkCorpusReader,
["train.txt", "test.txt"],
("NP", "VP", "PP"),
tagset="wsj",
encoding="ascii",
)
conll2002 = LazyCorpusLoader(
"conll2002",
ConllChunkCorpusReader,
".*\.(test|train).*",
("LOC", "PER", "ORG", "MISC"),
encoding="utf-8",
)
conll2007 = LazyCorpusLoader(
"conll2007",
DependencyCorpusReader,
".*\.(test|train).*",
encoding=[("eus", "ISO-8859-2"), ("esp", "utf8")],
)
关于LazyCorpusLoader类
"""
To see the API documentation for this lazily loaded corpus, first
run corpus.ensure_loaded(), and then run help(this_corpus).
LazyCorpusLoader is a proxy object which is used to stand in for a
corpus object before the corpus is loaded. This allows NLTK to
create an object for each corpus, but defer the costs associated
with loading those corpora until the first time that they're
actually accessed.
The first time this object is accessed in any way, it will load
the corresponding corpus, and transform itself into that corpus
(by modifying its own ``__class__`` and ``__dict__`` attributes).
If the corpus can not be found, then accessing this object will
raise an exception, displaying installation instructions for the
NLTK data package. Once they've properly installed the data
package (or modified ``nltk.data.path`` to point to its location),
they can then use the corpus object without restarting python.
"""
LazyCorpusLoader类相关函数
"""
参数列表详解
:param name: The name of the corpus
:type name: str
:param reader_cls: The specific CorpusReader class, e.g. PlaintextCorpusReader, WordListCorpusReader
:type reader: nltk.corpus.reader.api.CorpusReader
:param nltk_data_subdir: The subdirectory where the corpus is stored.
:type nltk_data_subdir: str
:param *args: Any other non-keywords arguments that `reader_cls` might need.
:param *kargs: Any other keywords arguments that `reader_cls` might need.
"""
def __init__(self, name, reader_cls, *args, **kwargs):
from nltk.corpus.reader.api import CorpusReader
#初始化函数
assert issubclass(reader_cls, CorpusReader)
self.__name = self.__name__ = name
self.__reader_cls = reader_cls
# 如果nltk_data_subdir被显式设置
if "nltk_data_subdir" in kwargs:
# 使用指定的子目录路径
self.subdir = kwargs["nltk_data_subdir"]
# 弹出'nltk_data_subdir'参数,我们不再需要它了。
kwargs.pop("nltk_data_subdir", None)
else: # 使用“nltk_数据/语料库”
self.subdir = "corpora"
self.__args = args
self.__kwargs = kwargs
def __load(self):
# 查找语料库根目录。
zip_name = re.sub(r"(([^/]+)(/.*)?)", r"\2.zip/\1/", self.__name)
if TRY_ZIPFILE_FIRST:
try:
root = nltk.data.find("{}/{}".format(self.subdir, zip_name))
except LookupError as e:
try:
root = nltk.data.find("{}/{}".format(self.subdir, self.__name))
except LookupError:
raise e
else:
try:
root = nltk.data.find("{}/{}".format(self.subdir, self.__name))
except LookupError as e:
try:
root = nltk.data.find("{}/{}".format(self.subdir, zip_name))
except LookupError:
raise e
# 加载语料库。
corpus = self.__reader_cls(root, *self.__args, **self.__kwargs)
# 通过修改我们自己的___dict___和___class___以匹配语料库,将我们自己转化为语料库。
args, kwargs = self.__args, self.__kwargs
name, reader_cls = self.__name, self.__reader_cls
self.__dict__ = corpus.__dict__
self.__class__ = corpus.__class__
#将___dict___和___class____分配回,然后执行GC。
#重新分配后,不应该有任何引用
#所以应该在gc.collect()之后释放内存
def _unload(self):
lazy_reader = LazyCorpusLoader(name, reader_cls, *args, **kwargs)
self.__dict__ = lazy_reader.__dict__
self.__class__ = lazy_reader.__class__
gc.collect()
self._unload = _make_bound_method(_unload, self)
def __getattr__(self, attr):
# Fix for inspect.isclass under Python 2.6
# (see http://bugs.python.org/issue1225107).
# Without this fix tests may take extra 1.5GB RAM
# because all corpora gets loaded during test collection.
if attr == "__bases__":
raise AttributeError("LazyCorpusLoader object has no attribute '__bases__'")
self.__load()
# 这看起来是循环的,但不是循环的,因为_load()将我们的__class__更改为新的:
return getattr(self, attr)
def __repr__(self):
return "<%s in %r (not loaded yet)>" % (
self.__reader_cls.__name__,
".../corpora/" + self.__name,
)
def _unload(self):
# 如果在语料库加载过程中发生异常,那么“__unload”方法可能是未附加的,因此在这种情况下可以调用__getattr___,我们不应该再次触发语料库加载
pass
def _make_bound_method(func, self):
"""
Magic for creating bound methods (used for _unload).
"""
class Foo(object):
def meth(self):
pass
f = Foo()
bound_method = type(f.meth)
try:
return bound_method(func, self, self.__class__)
except TypeError: # python3
return bound_method(func, self)

















 2562
2562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









