







 本文介绍了如何使用Python的requests和BeautifulSoup库从中国工商银行新一代网上银行抓取贵金属的实时价格信息,包括名称、价格、涨跌幅等数据。
本文介绍了如何使用Python的requests和BeautifulSoup库从中国工商银行新一代网上银行抓取贵金属的实时价格信息,包括名称、价格、涨跌幅等数据。
原网址:中国工商银行新一代网上银行 (icbc.com.cn)
通过元素获取到表格对应的链接
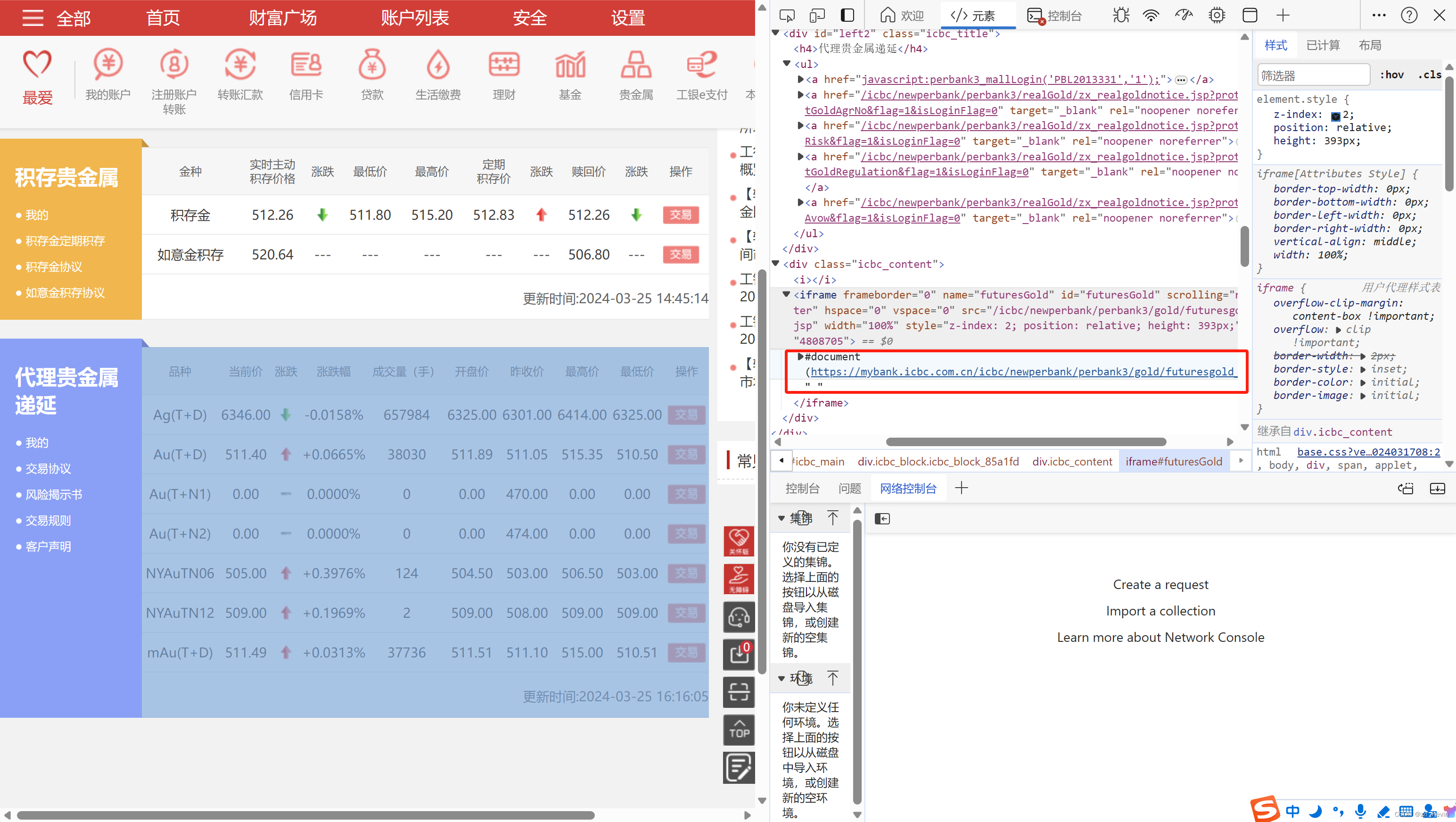
开始,写了个字典存对应的中文名称,Python不是我的主力语言,而且很久没写了,所以写的很烂,此代码仅供学习研究,不要用于非法用途,否则后果自负
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime
# 用于发送请求的URL
url = 'https://mybank.icbc.com.cn/icbc/newperbank/perbank3/gold/futuresgold_query_out.jsp'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Cookie': 'isP3bank=1; isEn_US=0; isPri=; firstZoneNo=%E5%B9%BF%E4%B8%9C_2000; arialoadData=true; ariawapChangeViewPort=true; CK_ISW_EBANKP_EBANKP-WEB-IPV6-NEW_80=bambfbmbegmbahnia-10|ZgEhV|ZgETe; sg___persistence__sugoio=%7B%22distinct_id%22%3A%20%2218e743d76de1b8-0c13ef4a74592f-4c657b58-186a00-18e743d76df2d63%22%7D'
}
gold_dict = {
"Au(T+D)": "黄金T+D",
"mAu(T+D)": "m黄金T+D",
"Ag(T+D)": "白银T+D",
"AuT+D": "黄金T+D",
"mAuT+D": "m黄金T+D",
"AgT+D": "白银T+D",
"Au9999": "黄金9999",
"Au9995": "黄金9995",
"Au100g": "金条100g",
"Au50g": "金条50g",
"Ag999": "白银999",
"AuT+N1": "黄金T+N1",
"AuT+N2": "黄金T+N2",
"SGiAu100g": "gi黄金100g",
"SGiAu9999i": "i黄金9999",
"SGiAu995i": "i黄金995",
"Ag9999": "白银9999",
"PT9995": "铂金9995",
"NYAuTN06": "纽约金TN06",
"NYAuTN12": "纽约金TN12",
}
# 发送请求并获取网页内容
response = requests.get(url)
web_content = response.text
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(web_content, 'html.parser')
# 根据网页结构提取贵金属价格信息
# 这里假设价格信息在id为'TABLE1'的表格中
table = soup.find('table', {'id': 'resultTable'})
rows = table.find_all('tr')
# print(rows)
# 解析每一行,提取贵金属名称和价格
for i,row in enumerate(rows[1:-1]): # 跳过表头
cols = row.find_all('td')
for x,col in enumerate(cols[:2]+cols[3:]):
if x==0 :
print("代码:" + col.text.strip())
if col.text.strip() in gold_dict:
print("名称:"+gold_dict[col.text.strip()])
elif x==1 :
print("当前价:" + col.text.strip())
elif x==2 :
print("涨跌幅:" + col.text.strip())
elif x==3 :
print("成交量(手):" + col.text.strip())
elif x==4 :
print("开盘价:" + col.text.strip())
elif x==5 :
print("昨收价:" + col.text.strip())
elif x==6 :
print("最高价:" + col.text.strip())
elif x==7 :
print("最低价:" + col.text.strip())
print("\n")
# print(col.text.strip())
time_element = soup.find('td', {'id': 'time'})
time_str = re.search(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', time_element.text).group()
# print(time_str)
update_time = datetime.strptime(time_str, '%Y-%m-%d %H:%M:%S')
formatted_time = update_time.strftime('%Y年%m月%d日 %H:%M:%S')
print("截止时间:"+formatted_time)运行结果:
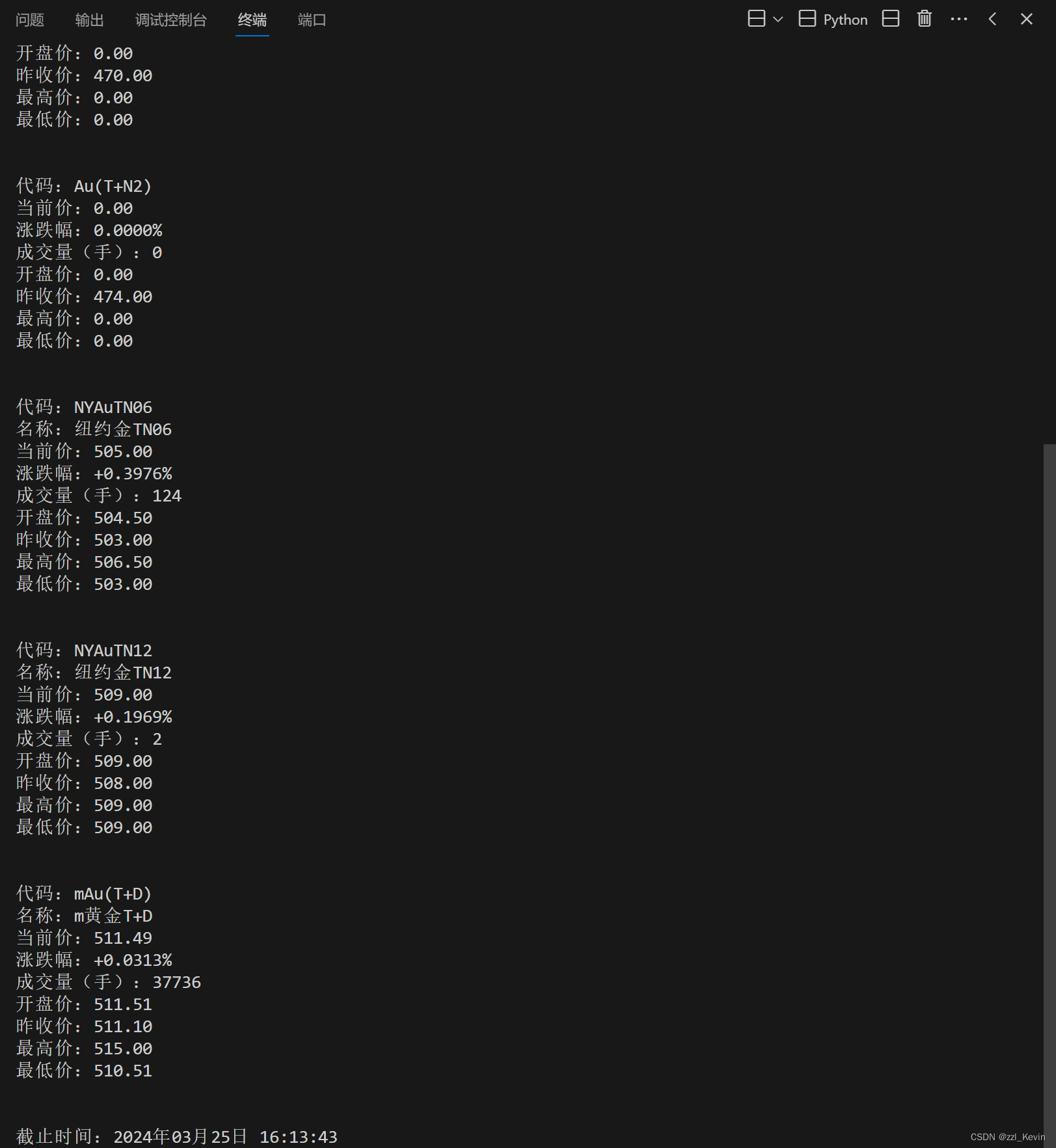


















 2544
2544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











