



1.2.6 B树
B 树(Balanced Tree)这个就是我们的多路平衡查找树,叫做B-Tree(B代表平衡)。跟AVL树一样,B树在枝节点和叶子节点存储键值、数据地址、节点引用。 它有一个特点:分叉数(路数)永远比关键字数多1。比如我们画的这棵树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点。
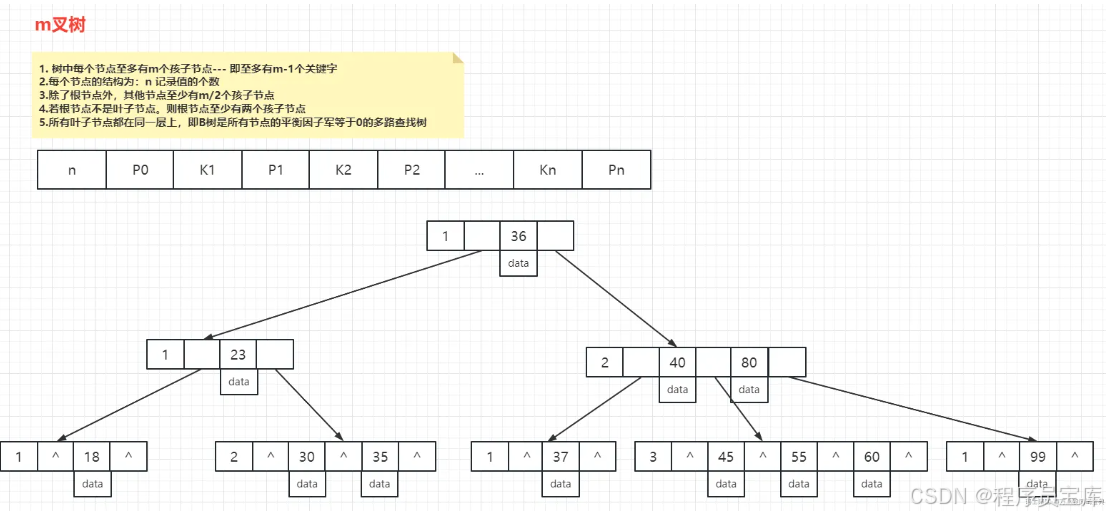
B Tree的查找规则是什么样的呢? 比如我们要在这张表里面查找30。 因为30小于36,走左边。 因为30大于23,走右边。 在磁盘块7里面就找到了30,只用了3次IO。
这个效率会比AVL树的效率更高
1.2.7 B+树
加强版多路平衡查找树 因为B Tree的这种特性非常适合用于做索引的数据结构,所以很多文件系统和数据库的索引都是基于B Tree的。 但是实际上,MySQL里面使用的是B Tree的改良版本,叫做B+Tree(加强版多路平衡查找树)。
B+树的存储结构: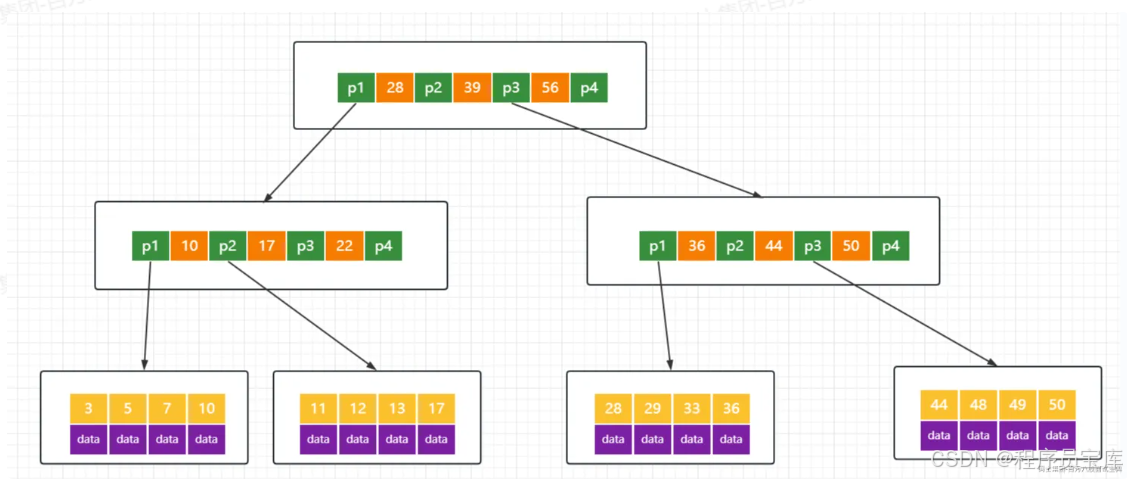
MySQL中的B+Tree有几个特点:
1 它的关键字的数量是跟路数相等的;
2 B+Tree的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据。InnoDB 中 B+ 树深度一般为 1-3 层,它就能满足千万级的数据存储。搜索到关键字不会直接返回,会到最后一层的叶子节点。比如我们搜索id=28,虽然在第一层直接命中了,但是全部的数据在叶子节点上面,所以我还要继续往下搜索,一直到叶子节点。
3 B+Tree的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构。 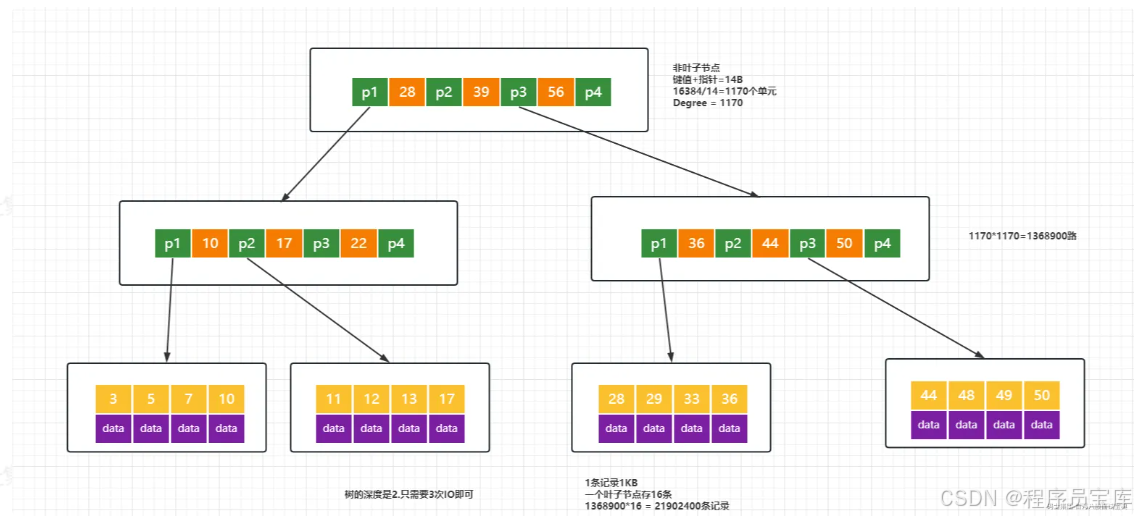
总结一下, B+Tree的特点带来的优势:
1 它是B Tree的变种,B Tree能解决的问题,它都能解决。B Tree解决的两大问题是什么?(每个节点存储更多关键字;路数更多)
2 扫库、扫表能力更强(如果我们要对表进行全表扫描,只需要遍历叶子节点就可以了,不需要遍历整棵B+Tree拿到所有的数据)
3 B+Tree的磁盘读写能力相对于B Tree来说更强(根节点和枝节点不保存数据区,所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多)
4 排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表)
5 效率更加稳定(B+Tree永远是在叶子节点拿到数据,所以IO次数是稳定的)
当然不会就此结束,还有更多的Java场景题,因为篇幅原因,无法给大家全部展示出来,有需要的看板老爷们,
查看下方小名片即可直接白嫖拿走哦!



















 619
619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









