







今天给大家分享的是一篇发表在Nature Communications上的论文“Contrastive-learning of language embedding and biological features for cross modality encoding and effector prediction”。识别和表征革兰氏阴性菌分泌的毒性蛋白对于解析微生物的致病性以及助力治疗策略的开发至关重要。使用预训练蛋白质语言模型(PLMs)的效应蛋白预测通过利用广泛的进化和序列特征展现出良好的性能。然而,效应蛋白预测的准确性和灵敏度仍具有挑战性。本文提出了一个名为CLEF(Contrastive-learning of Language Embedding and Biological Features)的模型,该模型利用对比学习整合PLM表示与补充的生物特征。通过对比学习,生物信息被捕捉到上下文的嵌入中,从而产生有意义的表示。凭借其跨模态生物特征整合能力,CLEF在预测肠道致病菌的III型、IV型和VI型分泌系统效应蛋白(T3SEs/T4SEs/T6SEs)方面优于现有的SOTA模型。在肠出血性大肠杆菌中,所有经过实验验证的效应蛋白均被成功识别,且在鼠伤寒沙门菌中43个已知的III型分泌系统效应蛋白(T3SEs)中有41个被准确识别。此外,通过在嗜水气单胞菌中进行广泛的实验验证,12个预测的T3SEs和11个预测的T6SEs得到了实验支持。CLEF框架通过整合组学数据,显著增强了蛋白质表示,有助于深入解析效应蛋白之间的复杂相互作用,还为确定体内定植必需基因提供了有力支持。总体而言,CLEF为弥合计算模拟的蛋白质语言模型能力与实验生物学信息之间的差距提供了一种创新性蓝图,为解决复杂生物医学问题开辟了新的路径。
1 背景
革兰氏阴性菌利用一系列复杂的蛋白质复合物(称为分泌系统),将多种效应蛋白(effectors)从细菌细胞内转运到细胞外环境中,例如竞争性细菌或宿主细胞内。这些分泌系统在细菌的致病机制中起着关键作用,因为它们能够将效应蛋白传递到宿主细胞中,从而操纵宿主的免疫反应或细胞功能。这些分泌的效应蛋白是许多临床重要革兰氏阴性菌的毒力因子,在感染策略中起着关键作用。例如:
-
III型分泌系统效应蛋白(T3SE): 在沙门氏菌和柠檬酸杆菌中,III型分泌效应蛋白(T3SE)能够形成复杂的细胞内毒力网络,从而操纵宿主的免疫反应。
-
IV型分泌系统效应蛋白(T4SE): 嗜肺军团菌通过向巨噬细胞分泌多种Dot/Icm效应蛋白(T4SE),来帮助细菌在宿主细胞内建立一个安全的复制环境。
-
VI型分泌系统效应蛋白(T6SE): 霍乱弧菌利用VI型分泌效应蛋白(T6SE)能杀死邻近的病原体以竞争生存资源,并通过调节宿主的免疫反应促进自身的定植。
因此,_识别和表征细菌效应蛋白_对于理解微生物的致病机制以及开发新的治疗策略至关重要。
目前,效应蛋白的发现主要依赖于_实验筛选方法_,如分泌组学分析。然而,这些方法通常耗时且受限于蛋白质表达和分泌水平的多样性和不确定性。近年来,_机器学习技术_被广泛应用于预测毒力效应蛋白。早期的模型基于已验证的效应蛋白,通过将蛋白质信息转化为机器友好的特征(如序列、进化、结构、生物物理特性和基因组位置)来区分效应蛋白。最近的一些效应蛋白模型尝试使用先进的编码技术作为蛋白质表示,以提高预测性能。例如,Bastion3使用位置特异性评分矩阵(PSSM)作为T3SE预测的统计表示;CNN-T4SE进一步利用卷积神经网络(CNN)从PSSM中提取特征,有效识别T4SE;T3SEpp和EP3通过集成多种表示和分类模型的输出来发现效应蛋白;Effectidor通过相应的基因和启动子特征来确定T3SE。
尽管现有的效应蛋白预测模型取得了一定的进展,但仍面临一些挑战。一方面,已知效应蛋白的数量有限,更重要的是,许多效应蛋白在序列或结构上没有相似性,导致模型难以从相对较小的数据集中学习到稳健的特征。另一方面,预训练的蛋白质语言模型中强大的表达能力为效应蛋白预测方法的发展带来了活力。虽然PLMs能够捕捉蛋白质的进化和序列特征,但其训练过程_忽略了来自广泛实验的特征_(如差异分泌蛋白质组学和转录组学数据)。此外,蛋白质结构和注释也可能提供关键的特征或先验知识,有助于效应蛋白的识别。因此,将实验生物信息整合到PLMs中是进一步提高预测性能的一种有前景的方法。
本文提出了一个语言嵌入和生物特征的对比学习(CLEF)模型,该模型通过对比学习框架将PLM表示与补充的生物特征(如蛋白质结构、功能注释和实验数据)相结合,生成更具信息量的跨模态表示。在T3SE、T4SE和T6SE效应蛋白预测任务中,CLEF与SOTA预测因子具有相当的性能,并且所识别的效应蛋白经过大量实验验证。此外,随着实验数据的整合,CLEF增强了蛋白表达,以破译效应蛋白之间的相互作用和体内定植必需基因。该模型为进一步完善和拓展PLMs在细菌毒力因子预测中的应用提供了思路,有助于探索细菌致病机制。
2 模型架构
CLEF是一个基于对比学习的深度学习框架
直接应用预训练的PLM预测细菌分泌系统的效应蛋白提供了有前景的结果,但现有模型的准确性和灵敏度仍有待提高。考虑到PLM只编码输入蛋白质的氨基酸序列,研究人员假设加入额外的生物蛋白信息,如蛋白质结构、功能注释和相关生物学实验数据,可以提高模型的预测性能。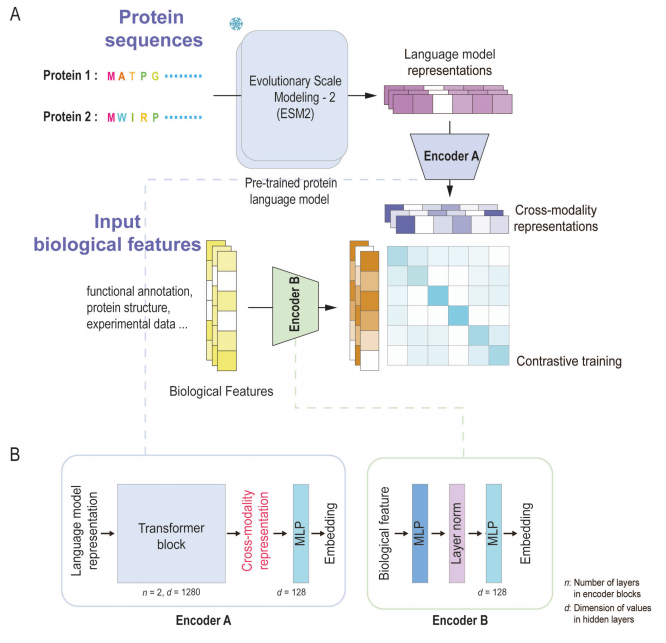
 因此,本文提出了一个名为基于对比学习的语言嵌入和生物特征的模型,通过对比学习框架将来自预训练的蛋白质语言模型的蛋白质表示与生物学特征相结合生成跨模态表示(图A)。定义的“生物学特征”包括结构、功能注释、其他预测模型输出的蛋白质表示和生物实验数据等。每种类型的模态特征与相应的PLM表示一起输入到CLEF中。CLEF采用了广泛使用的双编码器架构,将PLM表示和生物特征纳入潜在空间,生成协调的跨模态表示。InfoNCE损失保证了在训练过程中两种表示保持在隐空间内,从而使CLEF能够学习到生物特征和PLM表示之间的相关性。由CLEF生成的跨模态表征提高了基于PLM表征的识别多种生物学特征内在相关性的性能。
因此,本文提出了一个名为基于对比学习的语言嵌入和生物特征的模型,通过对比学习框架将来自预训练的蛋白质语言模型的蛋白质表示与生物学特征相结合生成跨模态表示(图A)。定义的“生物学特征”包括结构、功能注释、其他预测模型输出的蛋白质表示和生物实验数据等。每种类型的模态特征与相应的PLM表示一起输入到CLEF中。CLEF采用了广泛使用的双编码器架构,将PLM表示和生物特征纳入潜在空间,生成协调的跨模态表示。InfoNCE损失保证了在训练过程中两种表示保持在隐空间内,从而使CLEF能够学习到生物特征和PLM表示之间的相关性。由CLEF生成的跨模态表征提高了基于PLM表征的识别多种生物学特征内在相关性的性能。
在对比学习框架中,CLEF定义了两个专门的编码器模块(Encoder A和Encoder B)分别编码PLM表示和生物模态特征(图B)。Encoder A基于Transformer架构,将ESM2生成的蛋白质表示转换为与生物特征相关的跨模态表示;Encoder B通过多层感知器(MLP)将生物特征映射到潜在空间。
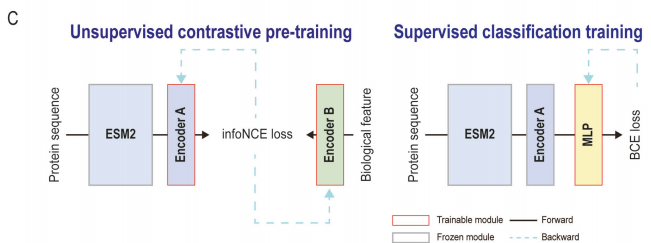
在细菌效应蛋白预测任务中,CLEF的训练分为两个阶段(图C):预训练阶段和分类训练阶段。在预训练阶段,CLEF通过对输入生物特征和ESM2表征的对比学习生成跨模态表示;随后在分类训练阶段,将这些表示送入分类器网络,在带有标签的数据集上进行训练,得到相应的效应蛋白预测模型。
3 实验结果
1、数据集
研究中使用了两部分数据集:对比学习预训练数据集和效应蛋白分类训练与测试数据集。
由于研究重点是效应蛋白分类,预训练数据集中的蛋白质主要来自其他现有效应蛋白预测模型的训练和评估数据集,以及相关蛋白质数据库。T3SS蛋白质从T3DB和T3Enc中收集,T6SS蛋白质从SecReT6中获取,实验验证的T1-T4和T6分泌底物从DeepSecEdb、BastionHub和BEAN中提取。此外,研究团队还从UniProt中随机抽取了4000个已审阅的蛋白质,并从VFDB中抽取了1000个与毒力相关的蛋白质,以增强数据集的多样性。为了去除冗余序列,使用MMseqs软件对序列相似性超过70%且匹配区域超过80%的蛋白质进行聚类,最终预训练数据集包含10,831个蛋白质。除了蛋白质序列,研究团队还收集了多种模态数据用于特征生成。结构PDB文件和注释文本文件从AFDB和UniProt中检索。对于未在UniProt中列出的蛋白质,通过MMseqs在UniRef50中进行相似性搜索,匹配序列相似性超过50%的同源标识符。多序列比对(MSA)和位置特异性评分矩阵(PSSM)数据通过在预训练数据集中使用ClustalOmega和PSI-BLAST生成。
用于开发效应蛋白分类器的非冗余标记训练和测试数据集来自最新的效应蛋白预测研究。训练集包括1577个非效应蛋白、128个T1SE、68个T2SE、406个T3SE、504个T4SE和232个T6SE。测试集包括150个非效应蛋白、20个T1SE、10个T2SE、30个T3SE、30个T4SE和20个T6SE。数据集中的蛋白质长度从少于100个氨基酸到超过1000个氨基酸不等,大多数蛋白质长度在100-600个氨基酸之间。在训练二元分类模型时,特定任务的效应蛋白类别标记为1,非效应蛋白和其他类型的效应蛋白标记为0。此外,还使用了其他效应蛋白预测模型的训练和测试数据集进行性能比较。
2、CLEF有效地整合了不同模态特征的信息
为了验证CLEF是否能够有效整合不同模态的特征,研究团队引入了3种不同类型的蛋白质模态特征进行对比训练,包括 代表蛋白质分泌效应蛋白分类特征的分泌嵌入(Secretion Embedding)、来自蛋白质数据库的注释文本特征(Annotation Text)和反映蛋白质三维结构信息的3Di特征。
首先对包含10,831个蛋白质样本的数据集进行对比学习预训练,分别将这些特征与ESM2表示相结合(图A)。随后,在标记数据集上评估CLEF输出表征的聚类性能,以确定CLEF学习的跨模态表征是否能准确反映蛋白质在特定模态下的异同(图B-D)。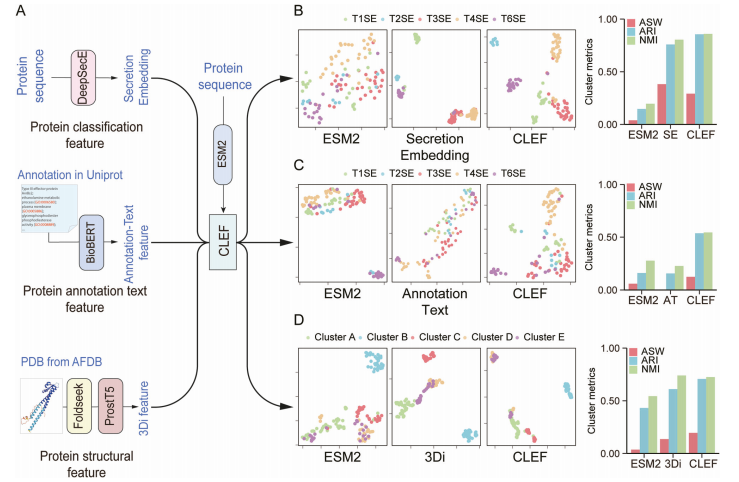
-
在包含110个效应蛋白的数据集中,原始ESM2表示在经过UMAP降维后,难以区分不同类型的效应蛋白(图B)。相比之下,CLEF框架通过对比学习整合分泌嵌入特征后,输出的表征能够形成与效应蛋白类别一致的明显聚类(图B)。聚类性能指标(调整Rand指数ARI、标准化互信息NMI和平均轮廓系数ASW)表明,对比学习显著增强了表征的聚类能力。
-
此外,CLEF利用BioBERT对UniProt的蛋白注释和基因本体论(GO)词条进行编码,作为注释文本特征。在使用ESM2表示进行对比训练后,CLEF成功地对模态进行了对齐,并从注释文本中捕获了关键效应蛋白信息,进一步提升了跨模态表征的聚类性能(图C)。
-
在蛋白质结构信息方面,CLEF通过Foldseek引入三维序列自动编码器,将空间信息转换为结构标记序列,并利用ProstT5模型将蛋白质序列编码为3Di特征。在包含148个结构簇标记的蛋白质测试集中,考虑到某些具有显著序列变异的蛋白质具有相似的结构,原始ESM2表征表现出最弱的聚类性能,而CLEF表征在ASW和ARI指标上优于ESM2和3Di特征,显示出更强的蛋白质结构相似性捕捉能力(图D)。
以上结果表明,CLEF的对比学习框架可以增强对不同蛋白质模态的表征能力,如分类特征、蛋白质注释和结构信息,生成更具信息量的跨模态表征。
3、CLEF表示提升了效应蛋白预测任务的模型性能
为了进一步验证CLEF在下游效应蛋白预测任务中的表现,研究团队使用4种不同的输入特征(DPC-PSSM、MSA、3Di和Annotation-Text)与ESM2表示进行对比训练,并将生成的表示输入到下游分类器中进行训练。CLEF进一步利用ESM2的多个输入模态,包括15组这些模态的不同组合。所有的表示被输入到包含1341个分泌底物和1577个非效应蛋白的标记数据集上进行二元分类器网络训练。使用包含260个蛋白的数据集进行独立检验,所有表示的表现见表1。 结果表明:
结果表明:
-
CLEF表示在T3SE、T4SE和T6SE预测任务中表现优异:例如,在T3SE预测任务中,CLEF-DP/AT表示的准确率(ACC)从0.977提升到0.985,F1分数从0.990提升到0.936。
-
CLEF在多模态特征组合中表现最佳:例如,在T4SE预测任务中,使用所有四种模态特征的CLEF表示(CLEF-DP/MSA/3Di/AT)达到了最高的准确率(ACC: 0.989)和F1分数(F1: 0.950)。
-
CLEF在T6SE预测任务中表现尤为突出:在测试集中,7种CLEF表示达到了完美的准确率(1.000)。
4、基于CLEF的分泌效应蛋白预测实现SOTA性能
研究团队使用在T3SE、T4SE和T6SE预测任务中表现最好的CLEF表示(用于T3SE的CLEF-DP/AT,用于T4SE的CLEF-DP/MSA/3Di/AT和用于T6SE的CLEF-DP)对模型进行基准测试,并与现有的最先进的(SOTA)效应蛋白预测模型进行比较。使用预测ACC、召回(REC)、精确度(PR)、F1和MCC作为度量来评估性能(图B-D)。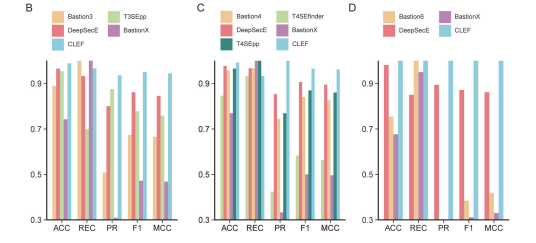 结果表明:
结果表明:
-
T3SE预测:CLEF在准确率(ACC: 0.989)、F1分数(F1: 0.951)和Matthews相关系数(MCC: 0.944)上均优于其他模型。
-
T4SE预测:CLEF在准确率(ACC: 0.992)、F1分数(F1: 0.966)和MCC(0.962)上表现最佳。
-
T6SE预测:CLEF在测试集中达到了完美的准确率(1.000),显著优于其他模型。
-
此外,CLEF在假阳性率方面表现更好,尤其是在面对多种类型的效应蛋白时,CLEF能够保持较低的假阳性率。
为了更全面地评估CLEF表示在训练效应器分类器中的能力,在更广泛的数据集上进行了更多的训练和测试,并将CLEF与SOTA模型进行了比较。最终,与SOTA模型相比,CLEF在8个测试数据集上获得了更好的整体性能(表2)。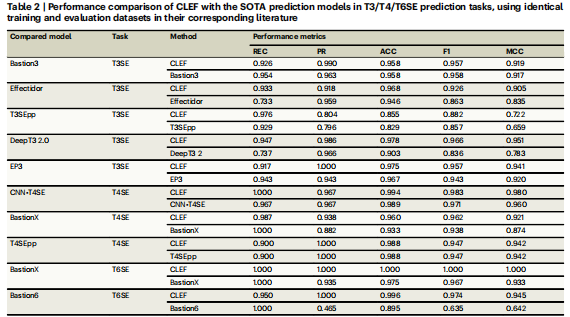
5、CLEF有助于发现肠道病原体piscicida中的T3SE和T6SE
CLEF模型能够仅基于氨基酸序列预测分泌的效应蛋白,从而快速识别病原体基因组中的潜在毒力因子。研究团队利用CLEF对嗜水气单胞菌(Edwardsiella piscicida)基因组中的效应蛋白进行了预测,并通过实验验证了预测结果。
作为一种重要的肠道病原体,E. piscicida通过通过III型分泌系统(T3SS)和VI型分泌系统(T6SS)将效应蛋白注入宿主细胞,操纵宿主的免疫反应并促进细菌的定植和感染。 研究团队使用CLEF模型对E. piscicida基因组中的蛋白质进行了预测,生成了潜在的T3SE和T6SE候选列表。为了进一步提高预测的准确性,研究团队集成了六个使用不同跨模态表示的CLEF模型(包括CLEF-DP、CLEF-MSA、CLEF-3Di、CLEF-AT、CLEF-DP/AT和基线模型ESM2)进行T3SE预测。对于T6SE预测,CLEF-DP/AT被替换为在T6SE基准测试中表现更好的CLEF-DP/MSA/3Di/AT(图A)。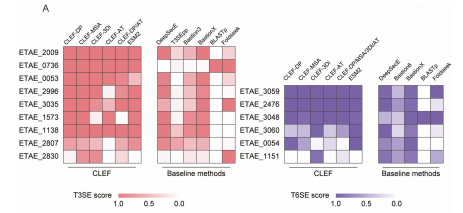 通过排名每个候选蛋白质在分类器中的平均预测得分,研究团队筛选出了15个潜在的效应蛋白,包括9个T3SE和6个T6SE。为了验证CLEF预测的效应蛋白,研究团队进行了Western blot和腺苷酸环化酶(CyaA)实验进行了验证。实验结果如下:1)T3SE验证:在9个预测的T3SE中,8个蛋白质(包括ETAE_2009、ETAE_0053、ETAE_2996、ETAE_3035、ETAE_0736、ETAE_1573、ETAE_2807和ETAE_2830)表现出T3SS依赖的分泌特性(图4B和图S4A)。CyaA实验进一步证实了这些蛋白质能够有效转位到宿主细胞中。2)T6SE验证:在6个预测的T6SE中,5个蛋白质(包括ETAE_3059、ETAE_3060、ETAE_2476、ETAE_3048和ETAE_0054)表现出T6SS依赖的分泌特性,并且能够转位到宿主细胞中。
通过排名每个候选蛋白质在分类器中的平均预测得分,研究团队筛选出了15个潜在的效应蛋白,包括9个T3SE和6个T6SE。为了验证CLEF预测的效应蛋白,研究团队进行了Western blot和腺苷酸环化酶(CyaA)实验进行了验证。实验结果如下:1)T3SE验证:在9个预测的T3SE中,8个蛋白质(包括ETAE_2009、ETAE_0053、ETAE_2996、ETAE_3035、ETAE_0736、ETAE_1573、ETAE_2807和ETAE_2830)表现出T3SS依赖的分泌特性(图4B和图S4A)。CyaA实验进一步证实了这些蛋白质能够有效转位到宿主细胞中。2)T6SE验证:在6个预测的T6SE中,5个蛋白质(包括ETAE_3059、ETAE_3060、ETAE_2476、ETAE_3048和ETAE_0054)表现出T6SS依赖的分泌特性,并且能够转位到宿主细胞中。
【 与其他预测方法的对比:CLEF在识别效应蛋白方面的表现优于其他方法(如BLASTp和Foldseek),尤其是在识别结构相似的效应蛋白时表现出更高的敏感性。】
研究团队将CLEF的预测结果(15个鉴定出的效应蛋白)与其他预测方法(如BLASTp、Foldseek、DeepSecE和BastionX)进行了对比(图4A)。 结果表明,CLEF在识别效应蛋白方面表现优于其他方法,尤其是在识别结构相似的效应蛋白时表现出更高的敏感性。例如,ETAE_2830(YfiH)和ETAE_1151虽然在其他方法中得分较低,但通过CLEF-3Di表示被成功识别。蛋白质结构比较显示,这些蛋白质与已知的T3SE和T6SE具有相似的结构,表明CLEF-3Di表示能够捕捉到蛋白质结构中的关键特征。
6、结合实验数据的对比训练增强了效应蛋白预测
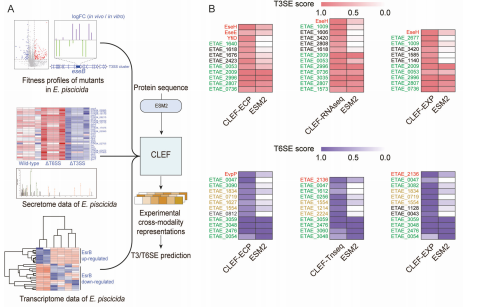 为了进一步提升CLEF模型在效应蛋白预测中的性能,研究团队将实验数据(如转录组学、分泌组学和Tn-seq数据)作为模态特征输入CLEF模型,生成了三种跨模态表示(CLEF-Tnseq、CLEF-RNAseq和CLEF-ECP)(图A)。此外还整合了所有实验数据特征,生成了CLEF-EXP的多模态表示。
为了进一步提升CLEF模型在效应蛋白预测中的性能,研究团队将实验数据(如转录组学、分泌组学和Tn-seq数据)作为模态特征输入CLEF模型,生成了三种跨模态表示(CLEF-Tnseq、CLEF-RNAseq和CLEF-ECP)(图A)。此外还整合了所有实验数据特征,生成了CLEF-EXP的多模态表示。
为了验证实验数据对效应蛋白预测的增强作用,研究团队将生成的跨模态表示输入到分类器中进行训练,并与基线模型(仅使用ESM2表示)进行对比(图B)。结果表明:
-
实验数据增强了CLEF的预测能力: 通过结合实验数据,CLEF能够识别一些难以通过初始表示预测的效应蛋白。例如,YfiD是一个已验证的T3SE,但在之前的模型中难以识别。通过CLEF-ECP表示,YfiD被正确识别为阳性。此外,一些在基线模型预测中得分较低的效应蛋白(如EseJ、EseH和EvpP)在CLEF-ECP和CLEF-RNAseq表示中得到了更准确的预测。
-
新效应蛋白的发现: 通过结合实验数据,CLEF成功识别了8个新的效应蛋白,包括3个T3SE和5个T6SE。这些效应蛋白通过Western blot和CyaA实验验证了其分泌和转位能力。例如,ETAE_1009(TonB)、ETAE_0256、ETAE_2677和ETAE_1612在Western blot实验中显示出明显的分泌特性,并在CyaA实验中证实了其能够有效转位到宿主细胞中。
综上所述,结果表明,利用实验数据特征的跨模态表示,CLEF可以有效地发现更多的效应蛋白。
7、CLEF揭示了潜在的效应蛋白-效应蛋白相互作用
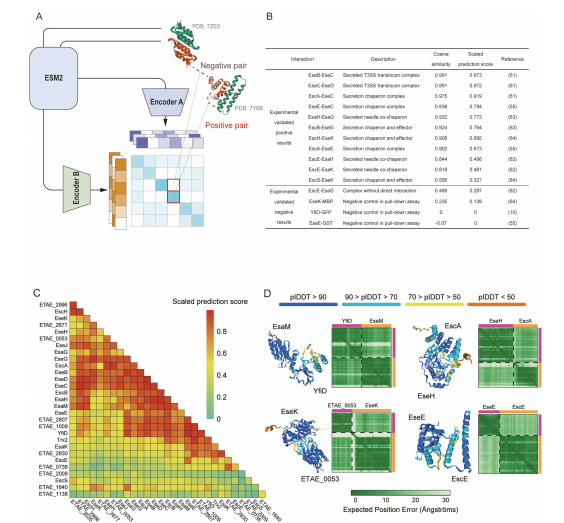 除了预测基因组中的潜在效应蛋白,识别蛋白质-蛋白质和分子功能水平上的效应蛋白相互作用对于破译它们的详细工作机制也至关重要,例如T3SE形成强大的网络有助于宿主的定植。 鉴于蛋白质和其他分子之间的相互作用可以抽象为它们的表征之间的关系,因此使用CLEF来学习相互作用蛋白质的ESM2表征之间的关联,从而有助于探索T3SE之间的相互作用。在训练过程中使用Dockground数据库中的34,985个蛋白质将相互作用的蛋白质对作为阳性样本(图A)。研究团队利用该模型生成的蛋白质表示,来学习相互作用蛋白质的表征之间的关联,将此模型命名为CLEF-EEI。研究发现,在之前验证过的9对配对中,有8对的相似度评分较高10,55,61 - 64,而大多数无互动的配对的相似度评分较低(图B)。然后,使用CLEF-EEI来预测E. piscicida中T3SE之间的相互作用,并进一步调整相似性评分,以提高蛋白对之间的区分度(图C)。并通过AlphaFold3验证了预测的蛋白质复合物结构(图D)。结果表明,CLEF能够准确预测效应蛋白之间的相互作用,为进一步研究效应蛋白的功能机制提供了线索。
除了预测基因组中的潜在效应蛋白,识别蛋白质-蛋白质和分子功能水平上的效应蛋白相互作用对于破译它们的详细工作机制也至关重要,例如T3SE形成强大的网络有助于宿主的定植。 鉴于蛋白质和其他分子之间的相互作用可以抽象为它们的表征之间的关系,因此使用CLEF来学习相互作用蛋白质的ESM2表征之间的关联,从而有助于探索T3SE之间的相互作用。在训练过程中使用Dockground数据库中的34,985个蛋白质将相互作用的蛋白质对作为阳性样本(图A)。研究团队利用该模型生成的蛋白质表示,来学习相互作用蛋白质的表征之间的关联,将此模型命名为CLEF-EEI。研究发现,在之前验证过的9对配对中,有8对的相似度评分较高10,55,61 - 64,而大多数无互动的配对的相似度评分较低(图B)。然后,使用CLEF-EEI来预测E. piscicida中T3SE之间的相互作用,并进一步调整相似性评分,以提高蛋白对之间的区分度(图C)。并通过AlphaFold3验证了预测的蛋白质复合物结构(图D)。结果表明,CLEF能够准确预测效应蛋白之间的相互作用,为进一步研究效应蛋白的功能机制提供了线索。
8、CLEF结合PACE分析揭示了E. piscicida的体内定植关键基因
为了在宿主体内成功定植,E. piscicida需要依赖一系列基因来操纵宿主的免疫反应并适应宿主体内的环境。识别这些体内定植关键基因对于理解E. piscicida的致病机制和开发新的防控策略具有重要意义。
PACE(Pattern Analysis of Conditional Essentiality)是一种分析基因在宿主体内定植过程中贡献的技术。它通过分析感染后不同时间点每个基因的测序频率变化,反映每个基因对体内定植的贡献。PACE数据提供了基因在宿主体内定植过程中的时间分辨模式特征,这些特征被提取并输入CLEF模型,生成与定植表型相关的跨模态表示。基于此,研究团队开发了一个基于CLEF的few-shot学习框架,结合PACE数据,用于识别E. piscicida的体内定植关键基因(图A)。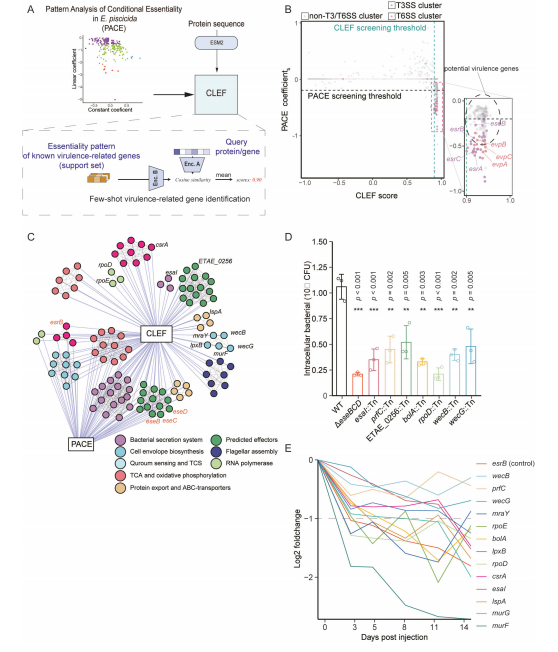 利用20个已知的E. piscicida定植关键基因构建支持集。对于每个查询基因,计算查询基因与支持集中每个基因的余弦相似度,并认为得分较高的查询与这些已知的毒力决定簇具有相似的定植能力。所有预测评分均以散点的形式显示,其中x轴代表基于CLEF的射击数预测评分,y轴代表PACE的系数(图B)。散点图右下角形成一个基因簇,其中CLEF评分较高的基因也具有较低的系数值。关键的毒力调节因子esrB和esrC以及其他T3SS/T6SS基因均位于该基因簇中,验证了CLEF评分可用于确定E. piscicida的体内毒力因子。 结果,获得了387个潜在的鱼毒棘球蚴毒力因子,其中有87个因子的阈值系数< -0.2(图C)。同时,KEGG分析显示,其他300个潜在基因富集在细菌分泌系统、细胞包膜生物合成、鞭毛组装、转录调控等毒力相关通路(图C)。 实验验证表明,这些基因在E. piscicida的定植和感染过程中起着关键作用。
利用20个已知的E. piscicida定植关键基因构建支持集。对于每个查询基因,计算查询基因与支持集中每个基因的余弦相似度,并认为得分较高的查询与这些已知的毒力决定簇具有相似的定植能力。所有预测评分均以散点的形式显示,其中x轴代表基于CLEF的射击数预测评分,y轴代表PACE的系数(图B)。散点图右下角形成一个基因簇,其中CLEF评分较高的基因也具有较低的系数值。关键的毒力调节因子esrB和esrC以及其他T3SS/T6SS基因均位于该基因簇中,验证了CLEF评分可用于确定E. piscicida的体内毒力因子。 结果,获得了387个潜在的鱼毒棘球蚴毒力因子,其中有87个因子的阈值系数< -0.2(图C)。同时,KEGG分析显示,其他300个潜在基因富集在细菌分泌系统、细胞包膜生物合成、鞭毛组装、转录调控等毒力相关通路(图C)。 实验验证表明,这些基因在E. piscicida的定植和感染过程中起着关键作用。
4 总结与讨论
本文通过对比学习获得的CLEF表示在效应蛋白预测中表现更好且更稳健,优于直接特征拼接的方法。CLEF框架通过将强大的PLM表示与各种生物特征相结合,为蛋白质相关的机器学习任务提供了更广泛的应用灵感。作者认为,CLEF代表了深度学习在生物数据应用中的重大进展,弥合了实验数据与深度学习之间的差距。未来的工作将集中在进一步优化模型,并探索其在更深层次任务中的应用,如效应蛋白靶标预测和效应蛋白相互作用网络建模等任务。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









