







排序算法分析(都以从小到大为例):
1、Insertsort:(原地排序)
最坏情况:从大到小排列(逆序),6,5,4,3,2,1, 比较(移动次数要乘以3)次数=n*(n - 1) / 2;
最好情况:从小到大排列(正序),1,2,3,4,5,6,比较次数 = n;
平均情况:与最坏情况一样,为Θ(n^2).
算法稳定。
void insertsort(unsigned long *a,int num,unsigned long *res)
{
unsigned long temp[num];
temp[0] = a[0];
//每次取一个数 插入temp数组中
for(int i = 1; i < num; i++)
for(int j = i - 1; j >= 0; j--)
{
if(a[i] < temp[j])
{
temp[j + 1] = temp[j];
if(j == 0)
temp[j] = a[i];
}
else
{
temp[j + 1] = a[i];
break;
}
}
for(int i = 0; i < num; i++)
res[i] = temp[i];
}
//原地排序版本
void insertsort1(unsigned long *a,int num)
{
unsigned long key;
//每次取一个数 插入temp数组中
for(int i = 1; i < num; i++)
{
key = a[i];
for(int j = i - 1; j >= 0; j--)
{
if(key < a[j])
{
a[j + 1] = a[j];
if(j == 0)
a[j] = key;
}
else
{
a[j + 1] = key;
break;
}
}
}
}2、Shellsort:(分组的插入排序)
开始无序的时候每组元素较少,最后差不多有序的时候元素才多起来,所以效果比插入排序要好。
算法不稳定 14336,步长开始取2,则33会换。
void shellsort(unsigned long *a,int num)
{
int step = num / 3;
unsigned long temp;
//每次插入排序的间隔步长
for(int i = step; i >= 1; i /= 2)
//插入排序
for(int j = 0; j < i; j++)
//将每隔i的数分为一组,并进行每组的插入排序
for(int k = j + i; k <= num - 1; k += i)
{
temp = a[k];
for(int m = k - i; m >= j; m -= i)
{
if(temp < a[m])
{
a[m + i] = a[m];
if(m == j)
a[m] = temp;
}
else
{
a[m + i] = temp;
break;
}
}
}
}3、Bubblesort:
每次将最小的元素移到(冒泡到)最前面(i)的位置。
最坏情况:逆序,6,5,4,3,2,1,比较次数:n*(n - 1) / 2; 移动次数:3 * n*(n - 1) / 2
最好情况:正序,123456,比较次数n
平均情况:
算法稳定
void bubblesort(unsigned long *a,int num)
{
for(int i = 0; i < num; i++)
for(int j = num - 1; j >= i + 1; j--)
{
unsigned long temp;
if(a[j] < a[j - 1])
{
temp = a[j - 1];
a[j - 1] = a[j];
a[j] = temp;
}
}
}4、selectsort:
和冒泡排序不同的是每次都只找到后面s[i+1,end]中最小的,仅进行下标的记录,而不进行相邻位置的交换。
最好最坏情况和冒泡一样,不过移动次数减少,比较次数一样。
void selectsort(unsigned long *a,int num)
{
int min_flag;
for(int i = 0; i < num; i++)
{
unsigned long min = a[i];
min_flag = i;
for(int j = i; j < num; j++)
{
if(a[j] < min)
{
min = a[j];
min_flag = j;
}
}
unsigned long temp = a[min_flag];
a[min_flag] = a[i];
a[i] = temp;
}
}5、Qsort(挖坑、填数)
最坏情况:每次partition都取的是当前组最大或最小,62345,每次分治的时候都是一个数组中有一个,另外一个有m-1个,故需进行n次划分,而每次进行的比较次数为m-1,故复杂度为n^2
最好情况:每次flag取中间大小的数,分治2边数组大小差不多,则会划分logn次,而进行比较次数就是每组的元素数,故为nlogn。
平均情况:假设规模为N的问题分为一个规模为9/10N的问题和规模为1/10N的问题,即T(n) = T(9n/10) + T(n/10) + Θ(n),用递归树分析可得T(n) = O(nlogn),而且比分区9:1要更平均(也就是情况更好)的概率为80%,所以在绝大部分情况下快速排序算法的运行时间为O(nlogn)。
//i从左往右,j从右往左,flag为第一个元素,将左边(i所指)比flag大的放到右边,把右边(j所指)的放到左边,i和j交替进行,挖坑、填数
int partition(unsigned long *a,int start,int end)
{
unsigned long flag = a[start];
int i = start;
int j = end;
//每次先跳过不需要动的,然后对需要动的进行移动
while(i < j)
{
//跳过右边比flag大的 ,这里有(i< j)是为了防止数组a后面值没有初始化会是乱值!
while((a[j] >= flag) && (i < j)) j--;
if(i < j)
a[i++] = a[j];
//跳过左边比flag小的
while((a[i] <= flag) && (i < j))i++;
if(i < j)
a[j--] = a[i];
}
a[i] = flag;
return i;
}
//不断进行左右分治的partition,直到每个左右数组"仅有一个元素 "
void qsort(unsigned long *a,int start,int end)
{
//start < end,保证仅有一个元素的时候停止
if(start < end)
{
int mid = partition(a,start,end);
qsort(a,start,mid - 1);
qsort(a,mid + 1,end);
}
}6、mergesort
算法里面有一种分治策略:Divide(分解子问题的步骤) 、 Conquer(递归解决子问题的步骤)、 Combine(子问题解求出来后合并成原问题解的步骤)
使得复杂度为nlogn,就是将问题分成2个同样的子问题,然后再找一个O(n)复杂度的方法将2个子问题的结果合并成原问题的结果,复杂度计算式为:
T(n)=2T(n/2)+O(n);
这样的T(n) = nlogn,mergesort就是这种思路。
Merge的最坏情况,需要进行n次比较与n次移动。
最好情况,进行n次移动+比较。
最好情况:已排好序,不用移动,仅比较 nlogn
最坏情况:一直都是merge的最坏情况,分组每次都是平均分的,故分logn次,所以也是nlogn
//将2个已排好序的数组合并成一个有序数组
//[start:mid]是array1,[mid+1:end]是array2
void merge(unsigned long *a,int start,int mid,int end,unsigned long *res)
{
int frsize = mid - start;
unsigned long temp[1000];
int j = mid + 1;
int i = start;
int k = 0;
while((i <= mid) && (j <= end))
{
if(a[i] > a[j])
temp[k++] = a[j++];
else
temp[k++] = a[i++];
}
if(i == mid + 1)//first array finishes first
for(int m = j; m <= end; m++)
temp[k++] = a[m];
else//second finishes first
for(int m = i; m <= mid; m++)
temp[k++] = a[m];
for(int i = 0; i <= end; i++)
res[i] = temp[i];
}
void mergesort(unsigned long *a ,int start,int end)
{
if(start < end)
{
int i = (start + end) / 2;
mergesort(a,start,i);
mergesort(a,i + 1,end);
merge(a,start,i,end,a);
}
}归并排序与快速排序比较:归并的merge要开额外的空间,而快排的partition可以原地进行!
7.堆排序
堆排序主要需要建立堆,通过heapify(int *a,int start,int num)操作将堆建立,然后每次取出根节点并将其移除后再将余下num-1个数用heapify操作建立堆。heapify操作一次复杂度为logn,一共n次heapify操作,复杂度O(nlogn)。其为不稳定排序算法。是就地排序,只需要O(1)的空间。
#include "heap.h"
using namespace std;
//a数组有效元素为a[1]-a[num].
void heap::min_heapify(int *a, int p,int num)
{
int lchild = 2 * p, rchild = 2 * p + 1;
int temp;
if (lchild > num)//已经到叶子节点
return;
else if (rchild > num)
{
if (a[lchild] < a[p])
{
temp = a[p];
a[p] = a[lchild];
a[lchild] = temp;
}
return;
}
min_heapify(a, 2 * p, num);
min_heapify(a, 2 * p + 1, num);
int min;
if (a[lchild] < a[rchild])
min = lchild;
else
min = rchild;
if (a[min] < a[p])
{
temp = a[p];
a[p] = a[min];
a[min] = temp;
}
}
void heap::min_heapsort(int *a, int num)
{
for (int i = num; i >= 1; i--)
{
min_heapify(a, 1, i);
int temp = a[i];
a[i] = a[1];
a[1] = temp;
}
}8、桶排序
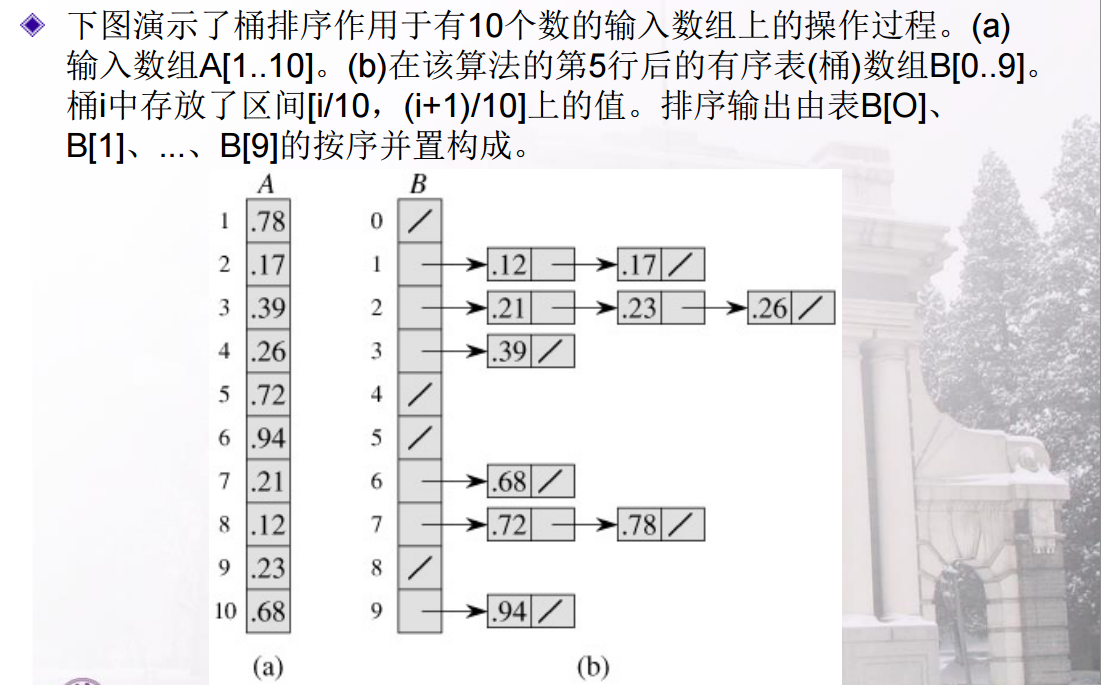
此排序是为了优化计数排序的空间太大问题,即要排序的数很多(如500万个数),但是数的范围不大(如0-900),通过将数组的数据全部归一化到[0,1)之间,然后建立m个区间分别为[0,1/m)、[1/m,2/m)、……[m-1/m,1)的bucket,每个桶都是一个链表,将归一化的数据放入到对应的桶中,然后对每个桶进行排序(用qsort、insertsort.etc都行),然后按顺序输出即可。
void bucketsort(unsigned long *a,int num,int m)
{
double data[1000];
unsigned long max = 0;
vector<double> bucket[20];
float seg = 1.0 / m;
for(int i = 0; i < num; i++)
{
if(max < a[i])
max = a[i];
}
max = max + 100;
for(int i = 0; i < num; i++)
{
data[i] = (double)a[i] / max;
for(int j = 0; j < m; j++)//放桶里
{
if(data[i] >= seg * j && data[i] <= seg * (j + 1))
{
bucket[j].push_back(data[i]);
break;
}
}
}
for(int i = 0; i < m; i++)
sort(bucket[i].begin(),bucket[i].end());
int base = 0;
for(int i = 0; i < m; i++)
{
for(int j = 0; j < bucket[i].size(); j++)
a[base++] = (bucket[i])[j] * max;
}
}复杂度分析:
在做出数据落入每个bucket都是等可能的情况下,我们可以看到T() = O(n) + 每个桶排序时间总和,两边同时取期望,然后可以证明,排序时间的期望(用insertsort)为:n * (2 - 1/n).最终桶排序复杂度为O(n + c),其中C=N*(logN-logm),空间复杂度为O(N+M)。
eg:
在一个文件中有10G个整数,乱序排列,要求找出中位数。内存限制为2G。只写出思路即可(内存限制为2G意思是可以使用2G空间来运行程序,而不考虑本机上其他软件内存占用情况。)
分析:既然要找中位数,很简单就是排序的想法。那么基于字节的桶排序是一个可行的方法。
思想:将整型的每1byte作为一个关键字,也就是说一个整形可以拆成4个keys,而且最高位的keys越大,整数越大。如果高位keys相同,则比较次高位的keys。整个比较过程类似于字符串的字典序。
第一步: 把10G整数每2G读入一次内存,然后一次遍历这536,870,912即(1024*1024*1024)*2 /4个数据。每个数据用位运算">>"取出最高8位(31-24)。这8bits(0-255)最多表示256个桶,那么可以根据8bit的值来确定丢入第几个桶。最后把每个桶写入一个磁盘文件中,同时在内存中统计每个桶内数据的数量NUM[256]。
代价:(1) 10G数据依次读入内存的IO代价(这个是无法避免的,CPU不能直接在磁盘上运算)。(2)在内存中遍历536,870,912个数据,这是一个O(n)的线性时间复杂度。(3)把256个桶写回到256个磁盘文件空间中,这个代价是额外的,也就是多付出一倍的10G数据转移的时间。
第二步:根据内存中256个桶内的数量NUM[256],计算中位数在第几个桶中。很显然,2,684,354,560个数中位数是第1,342,177,280个。假设前127个桶的数据量相加,发现少于1,342,177,280,把第128个桶数据量加上,大于1,342,177,280。说明,中位数必在磁盘的第128个桶中。而且在这个桶的第1,342,177,280-N(0-127)个数位上。N(0-127)表示前127个桶的数据量之和。然后把第128个文件中的整数读入内存。(若数据大致是均匀分布的,每个文件的大小估计在10G/256=40M左右,当然也不一定,但是超过2G的可能性很小)。注意,变态的情况下,这个需要读入的第128号文件仍然大于2G,那么整个读入仍然可以按照第一步分批来进行读取。
代价:(1)循环计算255个桶中的数据量累加,需要O(M)的代价,其中m<255。(2)读入一个大概80M左右文件大小的IO代价。
第三步:继续以内存中的某个桶内整数的次高8bit(他们的最高8bit是一样的)进行桶排序(23-16)。过程和第一步相同,也是256个桶。
第四步:一直下去,直到最低字节(7-0bit)的桶排序结束。我相信这个时候完全可以在内存中使用一次快排就可以了。
整个过程的时间复杂度在O(n)的线性级别上(没有任何循环嵌套)。但主要时间消耗在第一步的第二次内存-磁盘数据交换上,即10G数据分255个文件写回磁盘上。一般而言,如果第二步过后,内存可以容纳下存在中位数的某一个文件的话,直接快排就可以了(修改者注:我想,继续桶排序但不写回磁盘,效率会更高?).
9、基数排序
void radixsort(unsigned long *a,int num)
{
vector<int> radix[10];//装每次排序后的序列
int allzero = 0;
unsigned long temp[1000];
int step = 1;
while(!allzero)
{
allzero = 1;
for(int i = 0; i < num; i++)
{
int digit = a[i] % (int)pow(10,step);
digit /= (int)pow(10,step - 1);
radix[digit].push_back(i);
if(digit > 0)
allzero = 0;
}
int k = 0;
for(int i = 0; i < 10; i++)//按照序列顺序输出即可
{
for(int j = 0; j < radix[i].size(); j++)
temp[k++] = a[(radix[i])[j]];
radix[i].clear();
}
for(int i = 0; i < num; i++)
a[i] = temp[i];
step++;
}
}















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









