






 本文介绍Puppeteer,一个由谷歌官方开发的Node库,用于操纵Chrome或Chromium浏览器。通过示例演示如何使用Puppeteer捕捉网页快照、生成PDF、实现自动化测试及分析网站性能。
本文介绍Puppeteer,一个由谷歌官方开发的Node库,用于操纵Chrome或Chromium浏览器。通过示例演示如何使用Puppeteer捕捉网页快照、生成PDF、实现自动化测试及分析网站性能。
https://segmentfault.com/a/1190000014403160
随着网络的迅速发展,因特网已经成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine) —— 例如传统的通用搜索引擎 Baidu 和 Google等,作为一个辅助人们检索信息的工具成为用户访问因特网的入口和指南。但是,通用性搜索引擎也存在着一定的局限性,如:通用搜索引擎所返回的结果包含大量用户不关心的网页、大多提供基于关键字的检索,难以支持根据语义信息提出的查询等。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
Puppeteer 是什么
Puppeteer 是由谷歌官方团队所开发维护的一个 node 库,它提供了一组用来操纵 Chrome 或 Chromium(即无 UI 的 Chrome) 浏览器的 API。
Puppeteer 的直译意思为傀儡师,意在我们可以通过 Puppeteer 来像操纵傀儡一样操纵浏览器去获取我们特定想要的信息。

Puppeteer 的功能
我们在浏览器中手动完成的大部分事情都可以用 Puppeteer 来完成。本文将采用下面几个例子来让你快速上手:
- 捕捉网页快照,生成PDF、图片等
- 爬取SPA应用,并生成预渲染内容(即“SSR” - 服务端渲染)
- 创建测试用例,实现自动化测试,如表单提交、UI测试、键盘输入等
- 捕获站点的时间线,以便追踪你的网站,帮助分析网站性能
Puppeteer 安装与使用
1. 安装
理论上 Puppeteer 的安装非常简单,就像我们去安装任意的一个 npm 包。
你只需要在你的项目目录的控制台里运行如下代码:
npm i --save puppeteer
//或
yarn add --save puppeteer
由于国内大环境(你懂的 |-_-| ),我们使用以上代码安装的时候,经常会出错:
ERROR: Failed to download Chromium r515411! Set "PUPPETEER_SKIP_CHROMIUM_DOWNLOA
D" env variable to skip download.这通常是由于 Chromium 浏览器未正常下载到而引起的。这个时候,我们可以先设定环境变量,跳过安装 Chromium 的步骤,然后手动翻墙去下载:
set PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1下载完毕后,运行 Chromium 安装包(切记:Mac 系统需要将该应用拷贝到应用程序中!),然后在代码里做如下配置即可:
(async () => {
const browser = await puppeteer.launch({
executablePath: '/Applications/Chromium.app/Contents/MacOS/Chromium', // 以 Mac 版本为例,注意:路径并不是截止到 .app !
// ... (其他一些配置)
});
})();也许会有人疑问,为啥不用 cnpm 来安装呢?一看就是聪明的宝宝,配置好淘宝源路径之后,使用
cnpm i --save puppeteer安装,更适合无法出柜的宝宝,期间要下载 74M 左右的 Chromium ,请您耐心等待。
2. 常用语法
本文只对一些特别特别常用的方法进行介绍,有其他需求请戳 Puppeteer 官方KPI。
您也可以直接跳过此模块,直接阅读下方示例,有个更直观的了解。
Puppeteer 的每一步操作都是一个异步请求,因此要用到 generator 的语法糖 async 和 await。
1)puppeteer.launch()
【作用】:启动浏览器。
【返回值】:promise。
【常用参数】:
headless是否开启浏览器的无头模式。默认值为
true。设为false后,抓包的时候,浏览器将打开可见,否则不可见。executablePath设置执行抓包的浏览器的路径。默认会查找
node_modules/puppeteer/.local-chromium路径。可手动自行配置。数据类型为字符串。timeout等待浏览器实例启动的最大毫秒数,超过这个时间则报超时错误。默认为 30000。设为 0 则禁用此项参数。数据类型为 Number。
2)browser.newPage()
【作用】:开启浏览器新窗口。
【返回值】:promise。
3)page.setViewport()
【作用】:配置窗口信息。
【返回值】:promise。
width窗口的宽度。单位为 px 。
height窗口的高度。单位为 px 。
deviceScaleFactor设备实际缩放比。默认值为 1 。
isMobile是否开启手机模式。默认为 false 。
hasTouch是否支持 touch 事件。默认为 false 。
isLandscape是否开启横屏模式。默认为 false 。
4)page.goto(url, options)
【作用】:当前窗口加载固定 url 地址页。url 需要以 https 开头。
【返回值】:promise。
5)page.waitFor()
【作用】:当前代码等待某某条件成功后继续执行后面代码。
【返回值】:promise。
该方法的参数有很多种,通常我们只需要传入毫秒数即可,程序会暂停我们指定的时间,然后再继续执行后面的代码。
6)page.waitForSelector()
【作用】:当前代码等待页面渲染出某个 DOM 元素后继续执行后面代码。
【返回值】:promise。
7)page.$()
【作用】:获取当前页面的某个元素,类似于 document.querySelector() ,如果找不到,则返回 null 。
【返回值】:promise <ELement>。
8)page.$$()
【作用】:获取当前页面的某类元素,类似于 document.querySelectorAll() ,如果找不到,则返回一个空数组。
【返回值】:promise <Array>。
9)page.$eval(selector, pageFunction[, ...args])
【作用】:获取当前页面的某个元素,然后在 pageFunction 里面对获取的元素进行处理。
【返回值】:promise。
10)page.$$eval(selector, pageFunction[, ...args])
【作用】:获取当前页面的某类元素,然后在 pageFunction 里面对获取的元素数组进行处理。
【返回值】:promise。
11)browser.close()
【作用】:关闭所有浏览器窗口并退出 Chromium 浏览器。Browser 对象也将会被销毁。
【返回值】:promise。
以上就是我们经常用到的一些方法,接下来,我们将通过示例获取更直观的体验。
不上代码强撸问题都是耍流氓
药~药~切开脑~煎饼果子来一套!
1. 捕捉网页快照,生成PDF、图片等
我们以阮一峰老师的 ECMAScript 6 入门 网页为目标 URL ,并生成一组 pdf 文件。
const URL = 'http://es6.ruanyifeng.com';
const puppeteer = require('puppeteer');
const fs = require('fs');
fs.mkdirSync('es6-pdf');
(async () => {
let browser = await puppeteer.launch();
let page = await browser.newPage();
await page.goto(URL);
await page.waitFor(5000); // 等待五秒,确保页面加载完毕
// 获取左侧导航的所有链接地址及名字
let aTags = await page.evaluate(() => {
let eleArr = [...document.querySelectorAll('#sidebar ol li a')];
return eleArr.map((a) =>{
return {
href: a.href.trim(),
name: a.text
}
});
});
// 先将本页保存成pdf,并关闭本页
console.log('正在保存:0.' + aTags[0].name);
await page.pdf({path: `./es6-pdf/0.${aTags[0].name}.pdf`});
// 遍历节点数组,逐个打开并保存 (此处不再打印第一页)
for (let i = 1, len = aTags.length; i < len; i++) {
let a = aTags[i];
console.log('正在保存:' + i + '.' + a.name);
page = await browser.newPage();
await page.goto(a.href);
await page.waitFor(5000);
await page.pdf({path: `./es6-pdf/${i + '.' + a.name}.pdf`});
}
browser.close();
})();运行结果:
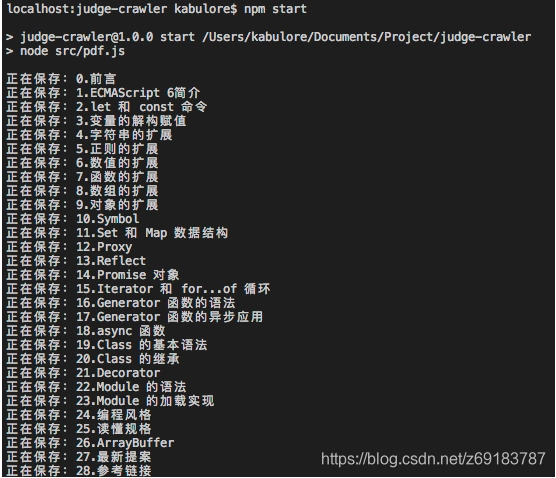
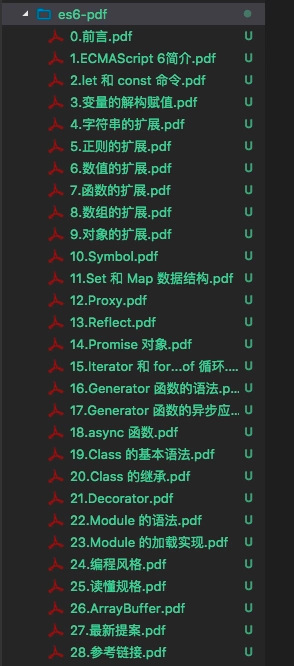
2. 实现自动化测试
我们以简单的测试汽车之家 iphone X 手机下随意选取一款车,然后询价为例:
const URL = 'https://m.autohome.com.cn/';
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone X'];
const fs = require('fs');
fs.mkdirSync('screenshot');
(async () => {
let browser = await puppeteer.launch({
headless: false // 无头模式
});
let page = await browser.newPage();
await page.emulate(iPhone);
await page.goto(URL);
await page.waitFor(3000);
await page.screenshot({
path: 'screenshot/1.png'
});
await page.tap('body > section.wrapper > section.recommend-auto.fn-mt > div:nth-child(2) > div.brand.activate > a:nth-child(1)');
await page.waitFor(3000);
await page.screenshot({
path: 'screenshot/2.png'
});
await page.tap('body > section > div.abc > section.findercar-brandcore > ul:nth-child(2) > li:nth-child(1) > a');
await page.waitFor(3000);
await page.screenshot({
path: 'screenshot/3.png'
});
await page.tap('body > section.summary-console > a');
await page.waitFor(3000);
await page.screenshot({
path: 'screenshot/4.png'
});
await page.type('body > section > section:nth-child(1) > section > dl.form-dl > dd:nth-child(2) > p.textcard.finish > input', '测试人员', {delay: 200});
await page.type('#userPhone', '13333333333', {delay: 200});
await page.screenshot({
path: 'screenshot/5.png'
});
await page.tap('body > section > section:nth-child(1) > section > div.linkcont.js-linkbtn > a');
await page.waitFor(3000);
await page.screenshot({
path: 'screenshot/6.png'
});
browser.close();
})();运行截图:
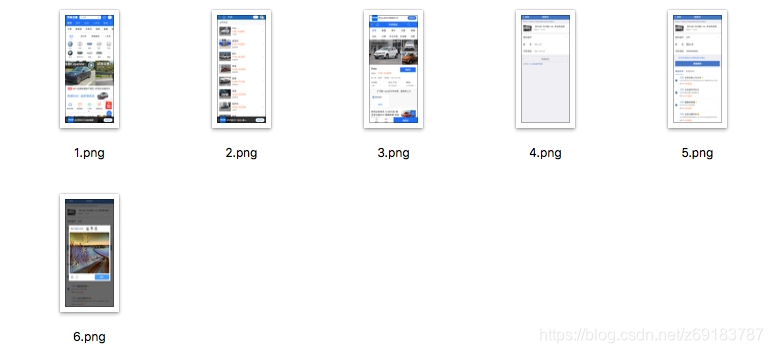
由于最终提交询价资料的时候,网站做了智能验证,所以无法自动提交成功,但整体流程我们都通过截图一步步保存了下来,让我们的测试更加方便、有理有据,便于撕逼。
3. 分析网站性能
我们以测试汽车之家 iphone X 手机下主页的性能为例:
const URL = 'https://m.autohome.com.cn/';
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone X'];
const fs = require('fs');
fs.mkdirSync('performance');
(async () => {
let browser = await puppeteer.launch();
let page = await browser.newPage();
await page.emulate(iPhone);
await page.tracing.start({path: 'performance/trace.json'});
await page.goto(URL);
await page.tracing.stop();
browser.close();
})();将 performance/trace.json 拖到 Chrome 浏览器的 performance 窗口下查看性能火山图:
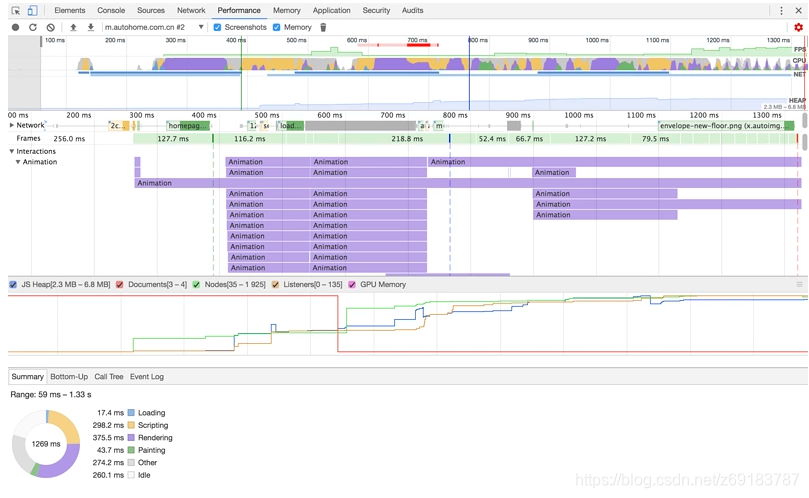
总结
Puppeteer 的功能远不止于此,笔者在本文中只是列举了几个最简单最常用的例子。大家有兴趣,欢迎深入研究并分享,独乐乐不如众乐乐。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









