







一、背景
这是两年前在公司做的小项目,后来公司倒闭了,就把这部分内容分享出来。相关工作应该是在18年的9-11月份之间做的。
二、算法思路
最开始想的思路是利用深度学习来做,具体做法也可以参考深度学习(二)——从零自己制作数据集到利用deepNN实现夸张人脸表情的实时监测(tensorflow实现),但是最大问题有两个:(1)如果你想要一个效果比较好的网络,那很大程度上需要更深层的网络,这就导致训练好的checkpoint或者pb文件过大,很难直接应用到移动设备上。(2)训练数据的好坏直接影响表情识别的效果,而我也没有海量的训练数据,所有的数据都是自己从网上爬取的,所以最终的训练效果不太理想。
后来又有了更简单的想法,因为dlib库有一个可以检测人脸特征点的模型,因此可以考虑用dlib库识别出人脸的关键特征点,然后利用这些特征点来计算一些表情特征。同时,图像处理主要用skimage库,主要用于裁剪识别出的人脸。最后再通过一些阈值来筛选计算的特征值,来判断人脸的表情。
可以这么做的原因是因为人脸特征点的对应位置编号,在不同影像中都是一样的,因此这就为人脸特征点识别带来很大方便。人脸特征点的位置如下图:

将这张图用于不同的人脸,可以看到每个位置的特征点编号都是一致的:

三、实现过程
1.文件结构
文件比较少,所有的文件结构如下:
-- shape_predictor_68_face_landmarks.dat # 68点人脸特征检测模型
-- face_analysis.py # 识别人脸特征,计算关键参数
-- video_camera_image_test.py # 调用视频,摄像头,图像进行测试 2.数据准备
关于数据准备,其实只要自己准备一个68点人脸特征检测模型就可以了。shape_predictor_68_face_landmarks.dat文件网上也比较多,这里直接给出一个下载地址:https://github.com/AKSHAYUBHAT/TensorFace/blob/master/openface/models/dlib/shape_predictor_68_face_landmarks.dat
打开上面的链接,点击下面的download,下载好之后把该文件放到project的根目录下即可:
3. 识别计算人脸特征参数文件文件face_analysis.py
这一步的主要思路是设计类,类中传入人脸识别的关键特征点,然后在类中设计算法计算特征值,比如眼睛的高度,和两眼的高度差,可以来判别是否闭眼或眨眼等特征。可以计算的特征值很多,我这里主要考虑了鼻子(判断人脸偏向),眼睛(眨眼或闭眼),嘴巴(张嘴,吃惊,or闭嘴),鼻尖和鼻翼(抬头or低头),暂时想到的就这些,然后通过计算实验,设计合理阈值。一下是该部分的代码:
import cv2
import dlib
from skimage import io
import time
class EmotionPara:
# 类的初始化,即传入参数仅有切割好的人脸图像和特征提取器
def __init__(self, face_img, shape, d):
self.img = face_img # 存储了人脸的图像
self.shape = shape # 存储了人脸特征点的图像坐标
self.d = d # 表示第d个人脸的框位置
self.face_width = (self.shape.part(15).x - self.shape.part(1).x) # 人脸的宽度
self.face_height = (self.d.bottom() - self.d.top()) # 人脸的高度
self.proof_brow_width = self.proof_brow_width() # 人脸方位的校正系数
self.nose = self.nose_para() # 人脸的方位向左还是向右
self.mouth = self.mouth_para() # 判断嘴是否张着,是轻微张嘴还是大张
self.faceupdown = self.faceupdown_para() # 判断人脸是向上还是向下
self.eye = self.eye_para() # 判断眼睛是否睁开,是否眨眼
self.brow = self.brow_para() # 眉毛参数
print(self.nose,
self.mouth,
self.faceupdown,
self.eye,
self.brow)
# 计算和嘴有关的参数
def mouth_para(self):
# 嘴的高度
mouth_height = ((self.shape.part(63).y - self.shape.part(65).y) +
(self.shape.part(62).y - self.shape.part(66).y) +
(self.shape.part(61).y - self.shape.part(67).y)) / 3
# 嘴的宽度
mouth_width = ((self.shape.part(64).x - self.shape.part(48).x) +
(self.shape.part(54).x - self.shape.part(60).x)) / 2
# 计算嘴的曲率
mouth_curv = abs(mouth_height / mouth_width)
# 计算嘴和鼻尖之间的距离,用以判断是抬头还是低头
# mouth_to_nose = self.shape.part(33).y - self.shape.part(51).y
mouth_height_ratio = abs(mouth_height / self.face_height)
# mouth_width_ratio = abs(mouth_width / self.face_width)
# mouth_to_nose_ratio = abs(mouth_to_nose / self.face_height)
# 判断是否张嘴,并简单判断嘴的表情
if mouth_height_ratio > 0.045: # 张嘴
if mouth_curv > 0.35:
mouth = "张大嘴巴,非常吃惊"
elif mouth_curv > 0.18:
mouth = "张嘴,有点小激动"
else:
mouth = "轻微张嘴"
else: # 闭嘴
mouth = "闭嘴"
return mouth
# return mouth_height_ratio, mouth_width_ratio, mouth_curv, mouth_to_nose_ratio
# 计算和眼睛有关的参数,返回左眼和右眼的高度,以及左右眼的高度差
def eye_para(self):
# 左眼的张开高度
eye_left_height = ((self.shape.part(37).y + self.shape.part(38).y) - (
self.shape.part(40).y + self.shape.part(41).y)) / 2
# 右眼的张开高度
eye_right_height = ((self.shape.part(43).y + self.shape.part(44).y) - (
self.shape.part(46).y + self.shape.part(47).y)) / 2
eye_left_height_ratio = abs(eye_left_height / self.face_height)
eye_right_height_ratio = abs(eye_right_height / self.face_height)
# 左右眼的张开高度差
diff_left_right = abs(eye_left_height_ratio - eye_right_height_ratio) * 10
# 然后判断眼睛的情况
# eye_left, eye_right, diff = face_para.eye_para()
# print("eye: ", face_para.eye_para())
if eye_left_height_ratio > 0.034 and eye_right_height_ratio > 0.034: # 睁眼
if eye_left_height_ratio > 0.07 and eye_right_height_ratio > 0.07 and diff_left_right < 0.060:
eye = "睁大眼睛"
elif diff_left_right < 0.060:
eye = "睁眼"
else:
if (eye_left_height_ratio - eye_right_height_ratio) > 0:
eye = "眨右眼"
else:
eye = "眨左眼"
elif diff_left_right >= 0.060:
if (eye_left_height_ratio - eye_right_height_ratio) > 0:
eye = "眨右眼"
else:
eye = "眨左眼"
else:
eye = "闭眼"
return eye
# 计算和眉毛有关的参数
def brow_para(self):
brow_height_sum = 0 # 高度之和
brow_width_sum = 0 # 左边眉毛距离之和
line_brow_x = [] # 存储左眉毛的x坐标
line_brow_y = [] # 存储左眉毛的y坐标
brow_height_ratio = 0
brow_width_ratio = 0
for j in range(17, 21): # 左边眉毛的编号是17到21, 右眉毛的编号是22到26,即j+5
brow_height_sum += (self.shape.part(j).y - self.d.top()) + (self.shape.part(j + 5).y - self.d.top())
brow_width_sum += (self.shape.part(j + 5).x - self.shape.part(j).x)
line_brow_x.append(self.shape.part(j).x)
line_brow_y.append(self.shape.part(j).y)
# print(brow_height_sum, brow_width_sum)
brow_height_ratio += (brow_height_sum / 10) / self.face_height # 眉毛高度占比
brow_width_ratio += (brow_width_sum / 5) / self.face_width # 眉毛距离占比
# print(brow_height_ratio, brow_width_ratio)
# 最后判断是否皱眉
# brow_height, brow_width = face_para.brow_para()
# print(brow_width / proof_brow_width)
if brow_width_ratio / self.proof_brow_width < 0.9:
brow = "皱眉,眉头紧锁"
else:
brow = ""
return brow
# 计算鼻子的相关参数,主要判断鼻子在人脸的中间还是两侧
def nose_para(self):
nose_location = self.shape.part(29).x - self.shape.part(1).x
nose_location_ratio = nose_location / self.face_width
if nose_location_ratio < 0.4:
nose = "向左转"
elif nose_location_ratio > 0.65:
nose = "向右转"
else:
nose = "正脸"
return nose
# 人脸方位的校正系数
def proof_brow_width(self):
nose_location = self.shape.part(29).x - self.shape.part(1).x
nose_location_ratio = nose_location / self.face_width
proof_brow_width = 1 - abs(nose_location_ratio - 0.5)
return proof_brow_width
# 计算能够判断人脸向上还是向下的参数
def faceupdown_para(self):
nose_tip = self.shape.part(30).y
alar = (self.shape.part(31).y + self.shape.part(35).y) / 2
uporlower_head = (alar - nose_tip) / self.face_height
# 根据鼻尖到嘴唇的距离,判断人脸向上或向下看
# uporlower_head = face_para.faceupdown_para()
# print("lips: ", uporlower_head)
if uporlower_head > 0.10:
face_updown = "抬头"
elif uporlower_head < 0.034:
face_updown = "低头"
else:
face_updown = ""
return face_updown
# # 利用嘴角判断高兴还是悲伤
# def mouthemo_para(self):
# up_lip = (self.shape.part(48).y + self.shape.part(54).y) / 2
# down_lip = (self.shape.part(67).y + self.shape.part(65).y) / 2
# emo_ratio = (up_lip - down_lip) / self.face_height
# return emo_ratio
def emotion_analysis(img, detector, predictor, show_img=False):
dets = detector(img, 1)
for k, d in enumerate(dets):
width = d.right() - d.left()
height = d.bottom() - d.top()
face_img = img[d.left():d.left() + width, d.top():d.top() + height]
shape = predictor(img, d)
EmotionPara(face_img, shape, d)
if show_img:
# 利用预测器预测
shape = predictor(img, d)
# # 标出68个点的位置-------------------------------------------------
for i in range(68):
cv2.circle(img, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 4)
cv2.putText(img, str(i), (shape.part(i).x, shape.part(i).y),
cv2.FONT_HERSHEY_SIMPLEX, 0.3, (255, 255, 255))
# # # -----------------------------------------------------------------
# # # 显示一下处理的图片,然后销毁窗口
b, g, r = cv2.split(img)
img2 = cv2.merge([r, g, b])
cv2.imshow('face', img2)
cv2.waitKey(0)
if __name__ == '__main__':
time_start = time.time()
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
time_mid = time.time()
img = io.imread('./test/000001.png')
emotion_analysis(img, detector, predictor)
time_end = time.time()
print('totally cost', time_end - time_mid)
给出算法(2)的代码:
from one_face_recog import *
# import cv2
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def video_emotion(video_dir):
'''
功能介绍:传入视频,分析视频中的表情
'''
vc = cv2.VideoCapture(video_dir) # 读入视频文件
if vc.isOpened(): # 判断是否正常打开
rval, frame = vc.read()
else:
rval = False
timeF = 100 # 视频帧计数间隔频率
c = 1
while (vc.isOpened()): # 循环读取视频帧
rval, frame = vc.read()
if (c%timeF == 0): # 每隔timeF帧进行存储操作
cv2.imwrite('image/' + str(c) + '.jpg', frame) # 存储为图像
# emotion_analysis(frame)
emotion_analysis('image/' + str(c) + '.jpg', detector, predictor)
c = c + 1
# cv2.waitKey(1)
vc.release()
def camera_emotion():
'''
功能介绍:直接打开摄像头,进行实时的表情分析
'''
# 打开摄像头
video_captor = cv2.VideoCapture(0) # 创建一个 VideoCapture 对象
timef = 10 # 视频帧计数间隔频率
c = 1
while True:
# 打开摄像头并做准备
ret_flag, frame = video_captor.read()
cv2.imshow("Capture_Test", frame)
if c % timef == 0:
emotion_analysis(frame, detector, predictor)
c += 1
k = cv2.waitKey(1)
if k == ord('q'): # 若检测到按键 ‘s’,打印字符串
break
video_captor.release() # 释放摄像头
cv2.destroyAllWindows() # 删除建立的全部窗口
def txt_emotion(txt_dir):
"""
功能介绍:打开txt中的文件批量处理
"""
time_start = time.time()
fopen = open(txt_dir, 'r')
lines = fopen.read().splitlines() # 逐行读取txt
# lines = random_shuffle(lines)
count = len(open(txt_dir, 'rU').readlines()) # 计算txt有多少行
# print(count)
# time_start = time.time()
i = 1
# print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
for line in lines:
line = line.split(" ") # 利用空格进行分割
img = io.imread(line[0])
# emotion_analysis(img)
emotion_analysis(img, detector, predictor)
i += 1
time_end = time.time()
print('totally cost', time_end - time_start)
print("the %d image has been processed" % (i))
def main(using_cv=False, using_txt=True, txt_dir='', using_video=False, video_dir=""):
if using_cv:
camera_emotion()
elif using_txt:
txt_emotion(txt_dir)
elif using_video:
video_emotion(video_dir)
else:
img = io.imread('D:/python/item/26-facedance(finished)/pre-data/zhayan/230.jpg')
emotion_analysis(img, detector, predictor)
if __name__ == '__main__':
main(using_cv=True,
using_txt=False, txt_dir='./pre-data/test.txt',
using_video=False, video_dir="")
# test('D:/python/item/26-facedance(finished)/pre-data/test.txt')四、实验效果
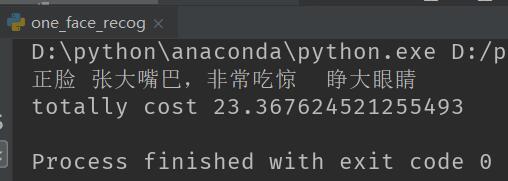
这里我随便找了一张图片来测试一下效果:

输出结果为(这里的时间是我查看程序的时间,不是程序处理的时间):
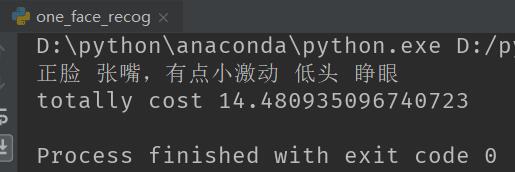
在来一张:

识别的表情结果:
五、分析
1. 我对大量图像进行了批量处理,平均下来大约一张图0.04s就可以识别出结果,也就是1秒25帧的样子,基本达到准实时识别的效果。
2. 对一些微表情,我觉得还有改进的空间。另外我还是觉得拿深度学习做的效果会比这种比参数的效果好很多,但是目前我没有比较好的数据集,后面有时间了再优化吧。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











