







前言
看的教程是用VM虚拟机然后建了四个虚拟环境做集群,但我不喜欢往自己电脑里面放虚拟机,而且内存也不大,就直接买了一个腾讯云的服务器,整伪集群算了,不知道会不会差别太大…
因为是自己搞的伪集群,安装hadoop部分就不看视频了自己搞,但是版本都按照视频里的来。还好以前大数据课自己装过Hadoop。
SCP命令
上传文件:scp 文件位置 用户名@IP:位置
删除???文件
我的Xshell用rz命令老报错,甚至还上传了一些乱码文件在上面,有一个文件用rm怎么删都删不掉,于是查了一下解决办法。
ls -i查询文件节点号
find -inum 节点号 -delete删除

安装JDK
选用的是jdk-8u212-linux-x64.tar.gz,首先把JDK传到/opt/software里

解压到/opt/moudle里

新建/etc/profile.d/my_env.sh
写入环境变量,之后source一下使它生效
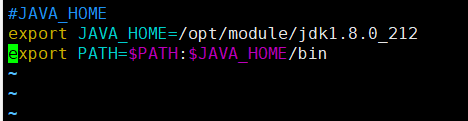
查看一下JAVA版本

安装Hadoop
主要参考视频里的方式,如果出bug了就回去看自己之前写的实验文档。
校园网真的好慢,我有一大半的时光都浪费在等下载等上传上…
继续解压hadoop压缩包

再次编辑/etc/profile.d/my_env.sh文件,写入如下内容,然后source使它生效
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
此时查询Hadoop版本















 1832
1832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









