






5.1 永恒的建模经验
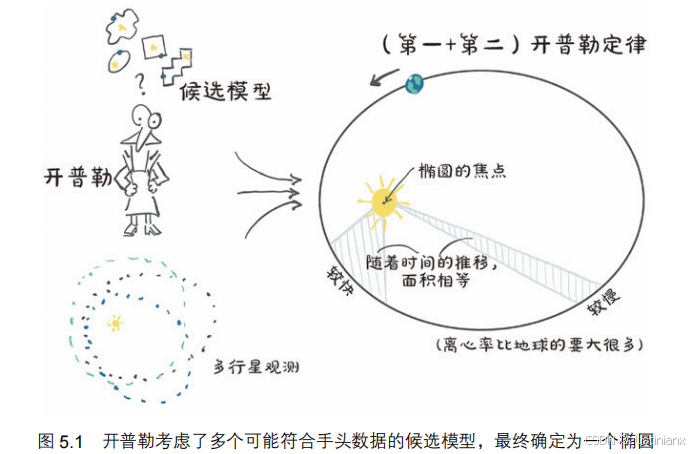
5.1.1 开普勒的行星运动定律
-
定律内容 :
-
第一定律 :每颗行星的轨道都是一个椭圆,太阳处在椭圆的一个焦点上。
-
第二定律 :太阳和运动中的行星的连线在相等的时间间隔内扫过相等
-
5.2 学习就是参数估计
5.2.1 校准仪器问题
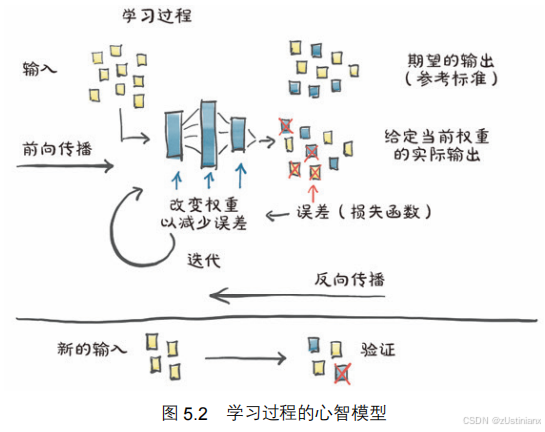
5.2.2 选择线性模型首试
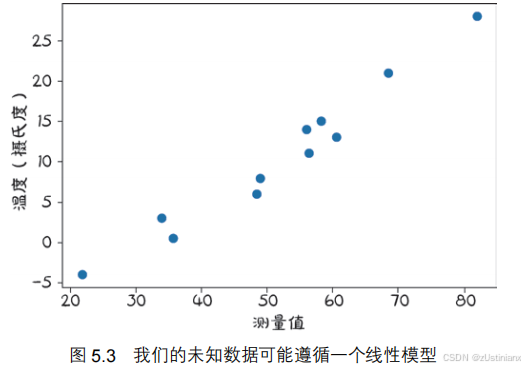
假设两组测量数据线性相关,即tc=w×tu+b, w 和 b 分别是权重和偏置,权重表示输入对输出的影响程度,偏置是所有输入为零时的输出。
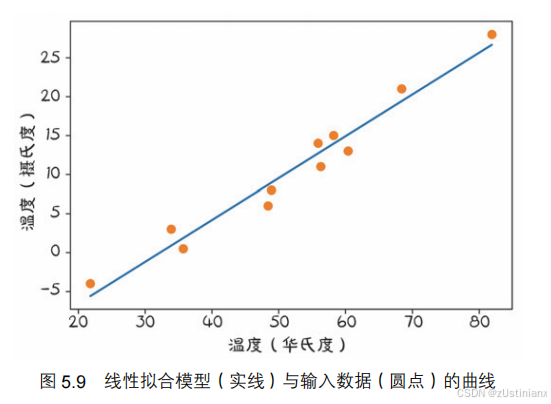
数据评估模型中的 w 和 b 参数,使通过模型得到的未知温度 t_u 接近实际测量的摄氏温度,这相当于通过一组测量值拟合一条直线。
5.3 减少损失是我们想要的
5.3.1 损失函数的定义与选择
损失函数(或代价函数)是一个计算单个数值的函数,学习过程试图使其值最小化。
损失的计算通常涉及获取训练样本的期望输出与模型实际产生的输出之间的差值。
损失函数是一种对训练样本中要修正的错误进行优先处理的方法,参数更新会导致对高权重样本的输出进行调整。
5.3.2 损失函数的特性
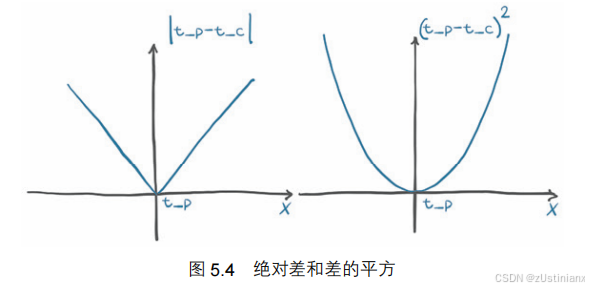
由于增长的陡度也从最小值开始逐渐增加,所以它们都是凸函数。
当损失是模型参数的凸函数时,可以通过专门的算法非常有效地找到最小值。
对于深度神经网络,损失不是输入的凸函数。
平方差比绝对差对错误结果的惩罚更大,通常有更多轻微错误的结果比有少量严重错误的结果要好,平方差有助于根据需要优先处理相关问题。
5.4 沿着梯度下降
5.4.1 减小损失
梯度下降法是一种优化损失函数的方法,计算各参数的损失变化率,并在减小损失变化率的方向上修改各参数。
通过在参数上加上一个小数字来估计变化率,然后根据变化率和学习率更新参数。
学习率是一个比例因子,用于衡量变化率,通常应该用一个小的学习率来缓慢地改变参数,因为在距离当前 w 值的邻域很远的地方,改变的速率可能会有显著的不同。
5.4.2 进行分析
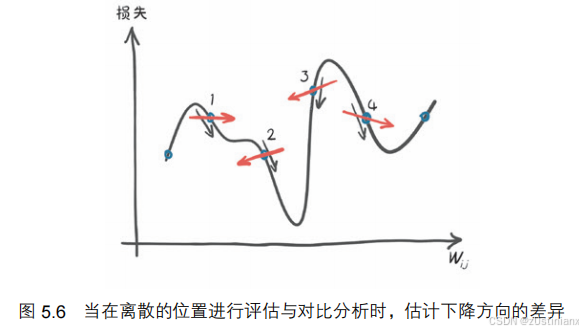
对模型和损失的重复评估来探测损失函数在 w 和 b 邻域的行为,计算变化率,在参数较多的模型中不太适合。
如果邻域无限小,就得到了损失对参数的导数。
在一个有两个或两个以上参数的模型中,计算每个参数的损失导数,并将它们放入一个导数向量中,即梯度。
为了计算损失对一个参数的导数,可以应用链式法则,先计算损失对于其输入(模型的输出)的导数,再乘模型对参数的导数。例如,dloss_fn/dw=(dloss_fn/dt_p)×(dt_p/dw)。
根据模型是线性函数,损失是平方和,可以算出导数的表达式。

5.4.3 迭代以适应模型
从某参数的假定值开始,可以对它应用更新,进行固定次数的迭代,或者直到 w 和 b 停止变化为止。
训练迭代称为一个迭代周期,在这个迭代周期,更新所有训练样本的参数。
完整的训练循环包括正向传播和反向传播,通过循环训练,可以优化参数。
通过学习率自适应来解决参数更新非常小,损失下降慢的问题。
5.4.4 归一化输入
在优化过程中,发现权重的梯度大约是偏置梯度的 50 倍,这意味着权重和偏置存在于不同的比例空间中。
如果学习率足够大,能有效更新其中一个参数,那么对于另一个参数来说,学习率就会变得不稳定。
为了解决这个问题,可以改变输入,使梯度不会有太大差异。
具体方法是确保输入的范围不会偏离 -1.0~1.0 太远。在本例中,通过将tu乘以 0.1 得到归一化版本tun,然后对归一化的输入运行训练循环。
采用的是简单的按 10 倍比例缩放的归一化方法,但对于更大、更复杂的问题,使用归一化可以简单而有效地改进模型的收敛性。
5.5 PyTorch 自动求导:反向传播的一切
5.5.1 自动计算梯度
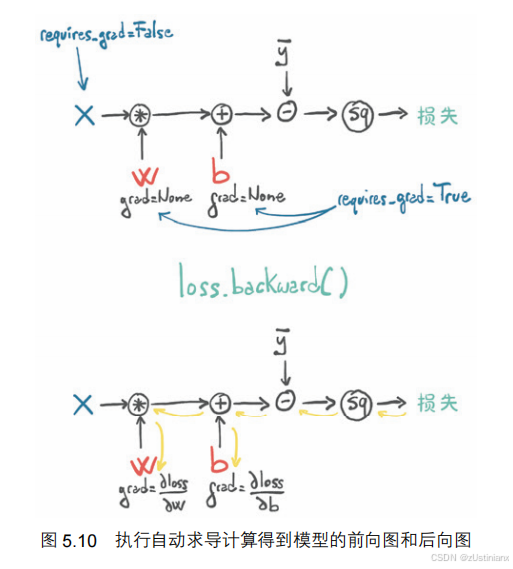
PyTorch 张量根据产生它们的操作和父张量,自动提供这些操作的导数链。
这意味着不需要手动推导模型,给定一个前向表达式,无论嵌套方式如何,PyTorch 都会自动提供表达式相对其输入参数的梯度。
计算损失后调用 loss.backward(),params 的 grad 属性会包含关于 params 的每个元素的损失的导数。
需要注意的是,调用 backward() 将导致导数在叶节点上累加,所以在每次迭代时要显式地将梯度归零,以防止梯度计算不正确。
5.5.2 优化器
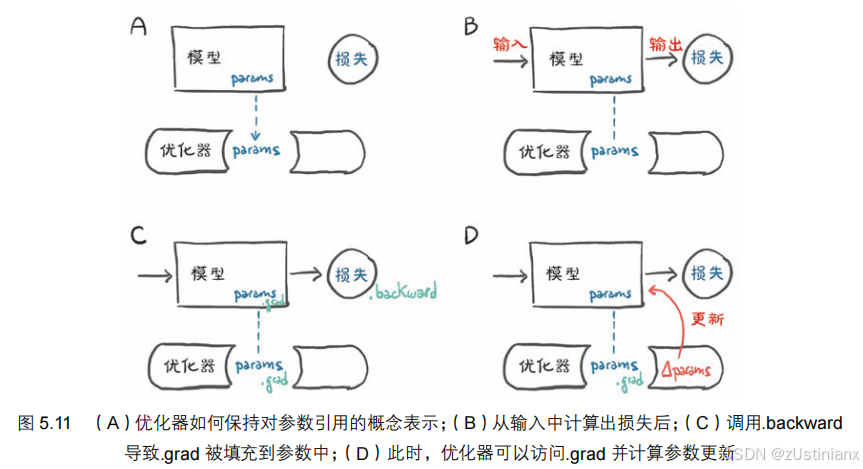
PyTorch 的 optim 模块提供了实现不同优化算法的类,避免了手动更新模型中的每个参数的繁琐工作。
优化器公开两个方法:zero_grad() 和 step()。
zero_grad() 在构造函数中将传递给优化器的所有参数的 grad 属性归零,step() 根据特定优化器实现的优化策略更新这些参数的值。
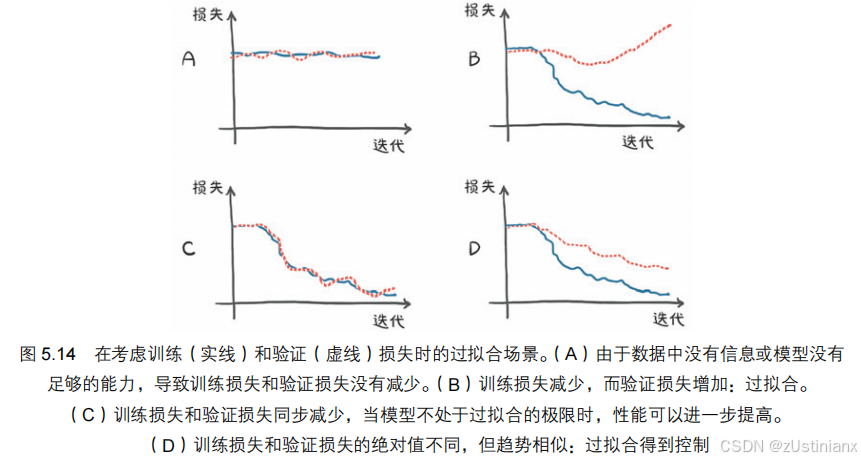
5.5.3 训练、验证和过拟合
从数据集中取出一些数据点作为验证集,只在剩下的数据点(训练集)上拟合模型,然后评估训练集和验证集上的损失。
训练损失会告诉模型是否能够完全拟合训练集,即模型是否有足够的能力处理数据中的相关信息。
如果训练损失没有减少,可能是因为模型对数据来说太简单,或者数据没有有意义的信息。
神经网络模型选择合适的参数的过程分为两步:增大参数直到拟合,然后缩小参数直到停止过拟合。
在实际操作中,可以通过打乱数据并分割成训练集和验证集来实现。
在训练循环中,额外评估每个迭代周期的验证损失,以便认识到是否过拟合。
验证集用于提供独立的模型评估,评估模型对未用于训练的数据的输出的准确性,所以不对验证损失调用 backward()。
5.5.4 自动求导更新及关闭
在训练循环中,对训练集上的模型进行评估以生成训练损失,这将创建一个计算图。
当模型再次在验证集上求值时,将生成验证损失,创建一个单独的计算图。
根据是否在训练模式还是推理模式下运行,使用 set_grad_enabled() 设定代码运行时启用或禁用自动求导的条件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









