







正则表达式:是一种高级字符串处理方式,通常用于字符串的匹配。
在所有Python字符匹配任务当中,分为两种匹配:
内容匹配: 根据对字符的内容类型,长度来描述字符;对内容进行匹配的方法是 正则
结构匹配: 根据对字符所处的位置进行描述的匹配,叫做结构匹配;对结构进行匹配的方法是 xpath
二者都有的匹配模块是beautifulsoup简称bs4
正则匹配:
python当中的正则模块叫做,re
re.findall 目的就是匹配字符串当中所有满足条件的字符
1、内容类型的描述
①原样匹配,匹配字符原样,通常结合其他匹配使用
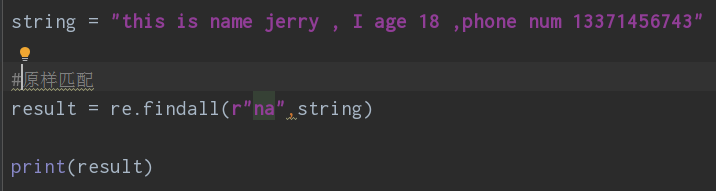
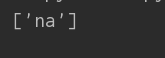
② . 匹配,匹配所有非换行的单个字符


③\d匹配:匹配字符串当中的数字


④\D匹配:匹配字符串当中所有非数字


⑤\w匹配字符串当中所有的字母、数字、下划线
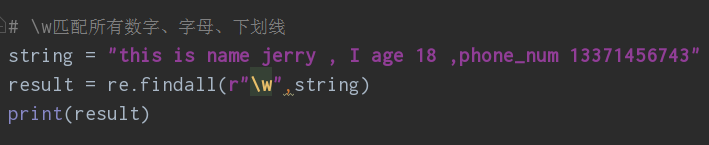

⑥\W匹配所有非字母、数字、下划线


⑦[abc]匹配中括号当中的a或b或c


⑧[a-zA-Z0-9]匹配中括号当中的范围字符

⑨[^ab]匹配除了中括号里面的元素之外的任意元素


⑩| 匹配|两边的任意一边(或)


11、()组匹配,会将非组内匹配,作为匹配的条件,进行匹配


12、命名组匹配,匹配一个和前面相同的数字
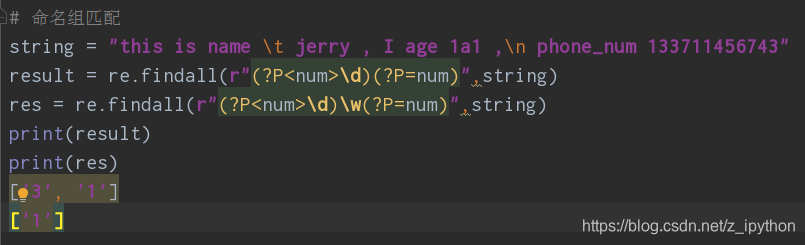
2、内容数量的匹配
①匹配0到多个


②+匹配1到多个

③?匹配0到1个


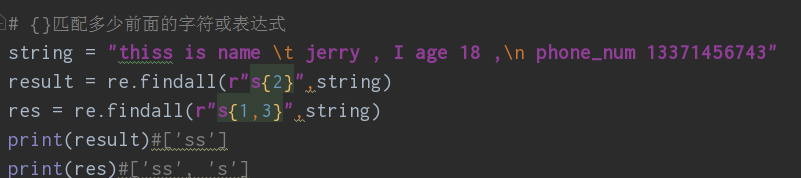
④{}匹配几个
{3}匹配3个
{3,5}匹配5到3次,以最多的为优先
⑤贪婪匹配.
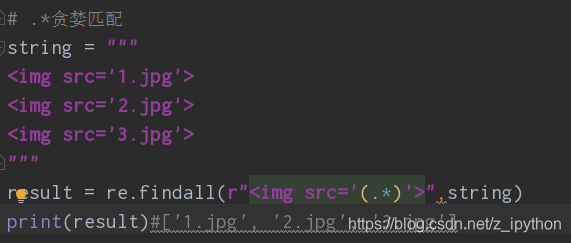
⑥反贪婪匹配.*?
3、匹配方法的描述
①^匹配开头的字符

②$匹配结尾的字符

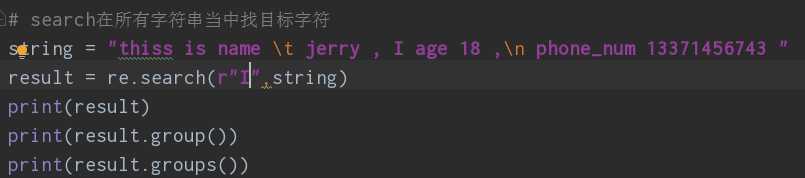
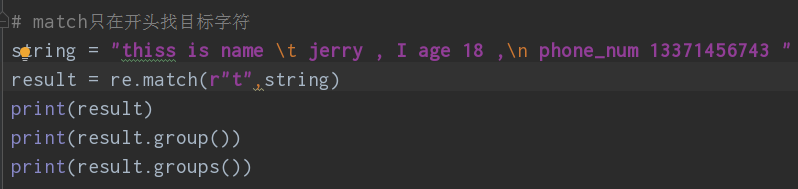
③re.search和re.match都是匹配一次指定的字符
re.search是从字符内部开始匹配,而match是从开头匹配,如果开头没有,search会向后接着匹配,match会返回None,当然,如果都找不到都会返回none


④re.I忽略大小写


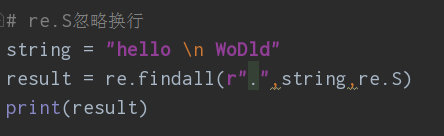
⑤re.S忽略换行,通常用于完整的HTML源码



















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











