







机器学习作为人工智能领域的核心组成,是计算机程序学习数据经验以优化自身算法、并产生相应的“智能化的“建议与决策的过程。随着大数据和 AI 的发展,越来越多的场景需要 AI 手段解决现实世界中的真实问题,并产生我们所需要的价值。
机器学习的建模流程包括明确业务问题、收集及输入数据、模型训练、模型评估、模型决策一系列过程。对于机器学习工程师而言,他们更擅长的是算法、模型、数据探索的工作,而对于工程化的能力则并不是其擅长的工作。除此之外,机器学习过程中还普遍着存在的 IDE 本地维护成本高、工程部署复杂、无法线上协同等问题,导致建模成本高且效率低下。
Jupyter 读取文件
import subprocess
import pandas as pd
res_list = subprocess.Popen(['ls', '/datasource/testErfenlei'],
shell=False,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE).communicate()
for res in res_list:
print(res.decode())
filenames = res.decode().split() # 将输出结果按空格分割成文件名列表
for filename in filenames:
if filename == 'erfenl.csv': # 根据实际文件名来判断
csv_data = pd.read_csv('/datasource/testErfenlei/' + filename) # 读取CSV文件
print(csv_data)Jupyter Notebook建模-双曲线图
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个数组
x = np.linspace(0, 10, num=100)
# 计算正弦和余弦值
sin_values = np.sin(x)
cos_values = np.cos(x)
# 将数据存储在 Pandas 数据帧中
df = pd.DataFrame({'x': x, 'sin': sin_values, 'cos': cos_values})
# 绘制正弦和余弦曲线
plt.plot('x', 'sin', data=df, label='sin(x)')
plt.plot('x', 'cos', data=df, label='cos(x)')
# 添加图例和标题
plt.legend()
plt.title('Sine and Cosine Curves')
# 显示图形
plt.show()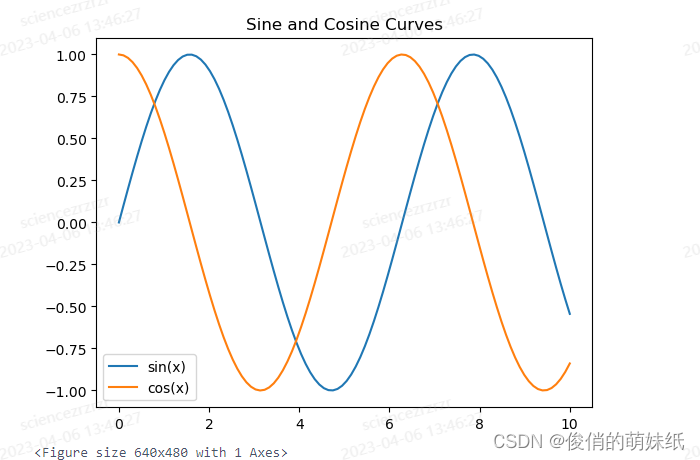
Jupyter Notebook
生成PMML文件1
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn2pmml import PMMLPipeline, sklearn2pmml
# 加载iris数据集
iris = load_iris()
# 训练决策树模型
dt = DecisionTreeClassifier()
dt.fit(iris.data, iris.target)
# 创建PMMLPipeline对象
pmml_pipeline = PMMLPipeline([
("classifier", dt)
])
# 导出模型为PMML文件
sklearn2pmml(pmml_pipeline, "iris_decision_tree.pmml")生成PMML文件2
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn2pmml import PMMLPipeline, sklearn2pmml
# 加载波士顿房价数据集
boston = load_boston()
# 构建线性回归模型
lr = LinearRegression()
# 使用 PMMLPipeline 包装模型
pipeline = PMMLPipeline([("lr", lr)])
# 使用数据拟合模型
pipeline.fit(boston.data, boston.target)
# 将模型保存为 PMML 文件
sklearn2pmml(pipeline, "linear_regression.pmml")
R Notebook建模 - 散点图
# 导入所需的库
library(ggplot2)
# 创建一个数据框
df <- data.frame(
x = 1:10,
y = c(3, 5, 6, 8, 9, 10, 11, 13, 14, 15)
)
# 绘制散点图
ggplot(df, aes(x, y)) +
geom_point() +
labs(title="Scatter Plot of X and Y", x="X", y="Y")R Notebook获取训练数据集
setwd(dir=”/datasource”)
dir()PySpark Notebook建模
# 导入所需库
from pyspark.sql import SparkSession
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









