







最近跟着LeetCode看算法相关知识,刚刚把队列&栈这一部分看完,稍微进行总结一下。
队列
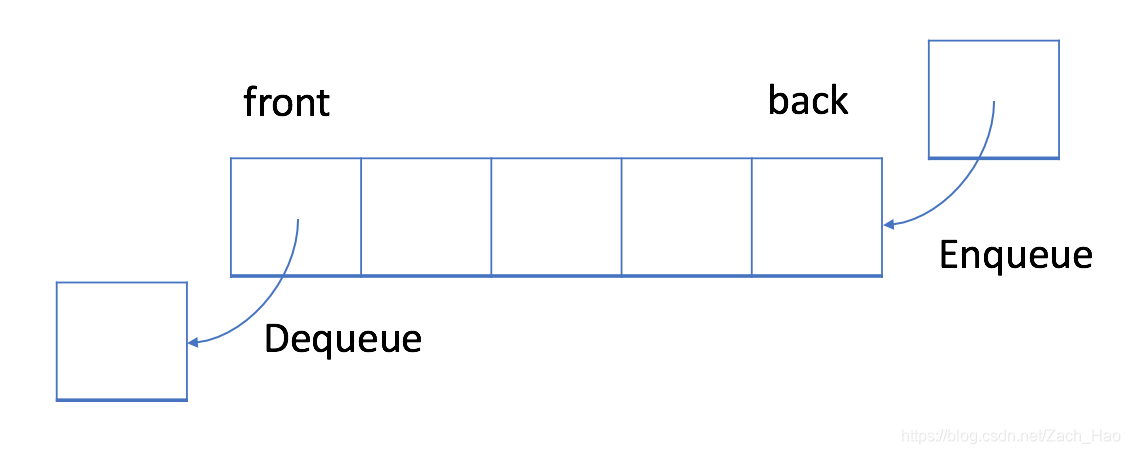
队列简单来说就是先进先出的数据结构,在Python中虽然List也可以实现,但是效率没有使用collections中的deque效率高,所以实现时多使用deque。
为了实现空间的有效利用,书中引入了循环队列:
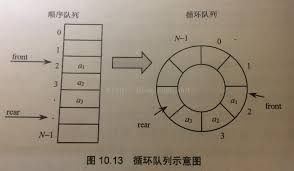
关于循环列表的构建,在【622. 设计循环队列】中给出了比较详细的过程。
大致思路肯定是利用两个指针,一个指向head另一个指向tail,然后根据命令执行pop和push。
官方在题解中说:
设计数据结构的关键是如何设计属性,好的设计属性数量更少。
- 属性数量少说明属性之间冗余更低。
- 属性冗余度越低,操作逻辑越简单,发生错误的可能性更低。
- 属性数量少,使用的空间也少,操作性能更高。
但是,也不建议使用最少的属性数量。一定的冗余可以降低操作的时间复杂度,达到时间复杂度和空间复杂度的相对平衡。
回顾我之前想用head指针、rear指针和length三个变量来实现,但是逻辑不清晰,导致中间出了不少问题,下面是官方提供的思路:
class MyCircularQueue {
private int[] data;
private int head;
private int tail;
private int size;
/** Initialize your data structure here. Set the size of the queue to be k. */
public MyCircularQueue(int k) {
data = new int[k];
head = -1;
tail = -1;
size = k;
}
/** Insert an element into the circular queue. Return true if the operation is successful. */
public boolean enQueue(int value) {
if (isFull() == true) {
return false;
}
if (isEmpty() == true) {
head = 0;
}
tail = (tail + 1) % size;
data[tail] = value;
return true;
}
/** Delete an element from the circular queue. Return true if the operation is successful. */
public boolean deQueue() {
if (isEmpty() == true) {
return false;
}
if (head == tail) {
head = -1;
tail = -1;
return true;
}
head = (head + 1) % size;
return true;
}
/** Get the front item from the queue. */
public int Front() {
if (isEmpty() == true) {
return -1;
}
return data[head];
}
/** Get the last item from the queue. */
public int Rear() {
if (isEmpty() == true) {
return -1;
}
return data[tail];
}
/** Checks whether the circular queue is empty or not. */
public boolean isEmpty() {
return head == -1;
}
/** Checks whether the circular queue is full or not. */
public boolean isFull() {
return ((tail + 1) % size) == head;
}
}
感觉官方思路比较清晰,和自己的思路对比后感觉有几个点特别好:
- 在入列和出列时是调用函数
isFull()和isEmpty()做的,和我开始时没有意识到使用相比,对于面向对象编程、分块分类分功能实现的步骤更加清晰; - 为了判断队列是否为空,
deQueue()中在pop后队列变为空队列时将指针设为 -1,这就避免了运行过程中满栈和空栈难分辨的问题。
当然这种思路想着比较具体,但是实现还是需要注意细节,官方还提供了一种思路,不使用tail,而是用count来记录现在队列的长度,这一方法在实现上更加简单:
class MyCircularQueue:
def __init__(self, k: int):
"""
Initialize your data structure here. Set the size of the queue to be k.
"""
self.queue = [0]*k
self.headIndex = 0
self.count = 0
self.capacity = k
def enQueue(self, value: int) -> bool:
"""
Insert an element into the circular queue. Return true if the operation is successful.
"""
if self.count == self.capacity:
return False
self.queue[(self.headIndex + self.count) % self.capacity] = value
self.count += 1
return True
def deQueue(self) -> bool:
"""
Delete an element from the circular queue. Return true if the operation is successful.
"""
if self.count == 0:
return False
self.headIndex = (self.headIndex + 1) % self.capacity
self.count -= 1
return True
def Front(self) -> int:
"""
Get the front item from the queue.
"""
if self.count == 0:
return -1
return self.queue[self.headIndex]
def Rear(self) -> int:
"""
Get the last item from the queue.
"""
# empty queue
if self.count == 0:
return -1
return self.queue[(self.headIndex + self.count - 1) % self.capacity]
def isEmpty(self) -> bool:
"""
Checks whether the circular queue is empty or not.
"""
return self.count == 0
def isFull(self) -> bool:
"""
Checks whether the circular queue is full or not.
"""
return self.count == self.capacity
队列和广度优先搜索(BFS)
广度优先搜索(BFS)是一种遍历或搜索数据结构(如树或图)的算法,BFS 在树中执行层序遍历。
因为在BFS中结点的处理顺序与它们添加到队列的顺序是完全相同的顺序,即先进先出(FIFO)故使用队列实现BFS。
在题目【286. 墙与门】中,要寻找到门最近的距离: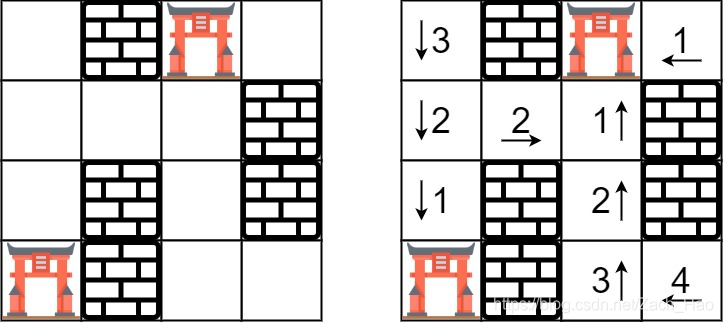
我的思路是利用队列对于每一个门进行循环,将其变为广度优先搜索,先遍历门附近点,在这过程中将遍历点附近点加入队列,然后依次循环。
对于同一点对于不同门之间距离的取舍,自己的解决方法是取最小值,如果当前distance值不是最小时不加入之后点。
这个思路的问题在于对于同时可以到达多个门的点存在多次遍历,官方题解的解决方法是:把所有门都找出来, 对所有门,使用队列,同时都走了1步,先到达的就是距离短的。
代码见下(自己写的):
class Solution:
def wallsAndGates(self, rooms: List[List[int]]) -> None:
m,n = len(rooms),len(rooms[0])
# 设定四个遍历方向
dist_group = [(1,0),(-1,0),(0,1),(0,-1)]
# 建立标志已访问的矩阵
marked = [[False] * n for _ in range(m)]
dq = collections.deque()
# 找到所有门,加入队列
for i in range(m):
for j in range(n):
if rooms[i][j] == 0:
dq.append((i,j))
marked[i][j] = True
elif rooms[i][j] == -1:
marked[i][j] = True
# length用作判断dist变化
length = len(dq)
dist = 0
# 遍历队列,不断更新值
while dq:
x,y = dq.popleft()
rooms[x][y] = dist
for a,b in dist_group:
# 只加入未被访问的点
if (-1 < x + a < m and -1 < y + b < n) and not marked[x+a][y+b]:
dq.append((x+a,y+b))
marked[x+a][y+b] = True
# 关于什么时候进行标记也需要注意,
# 假如在更改距离时才标记则队列中该点可能出现多次
# 又因为自己代码中门也会参与遍历,很难用判断排除第二次访问
length -= 1
if not length:
dist += 1
length = len(dq)
题目【752. 打开转盘锁】假设有一个带有四个圆形拨轮的转盘锁,每次转动一个转盘的一个数字,计算波动到解锁密码需要的最少次数,而且为增加难度题目来设置了一组“死亡数组”即不能出现的数字。
自己对于这道题目完全没有思路,官方题解见下:
class Solution(object):
def openLock(self, deadends, target):
def neighbors(node):
for i in xrange(4):
x = int(node[i])
for d in (-1, 1):
y = (x + d) % 10
yield node[:i] + str(y) + node[i+1:]
dead = set(deadends)
queue = collections.deque([('0000', 0)])
seen = {'0000'}
while queue:
node, depth = queue.popleft()
if node == target: return depth
if node in dead: continue
for nei in neighbors(node):
if nei not in seen:
seen.add(nei)
queue.append((nei, depth+1))
return -1
从上面代码可以看出官方的思路便是直观的模仿拨动转盘的过程,设立队列存储之前的结果,然后遍历队列,然后将其拨动的可能结果再添加至队列中。中间要注意的是使用集合防止重复访问、判断是否在“死亡数组”中。
栈
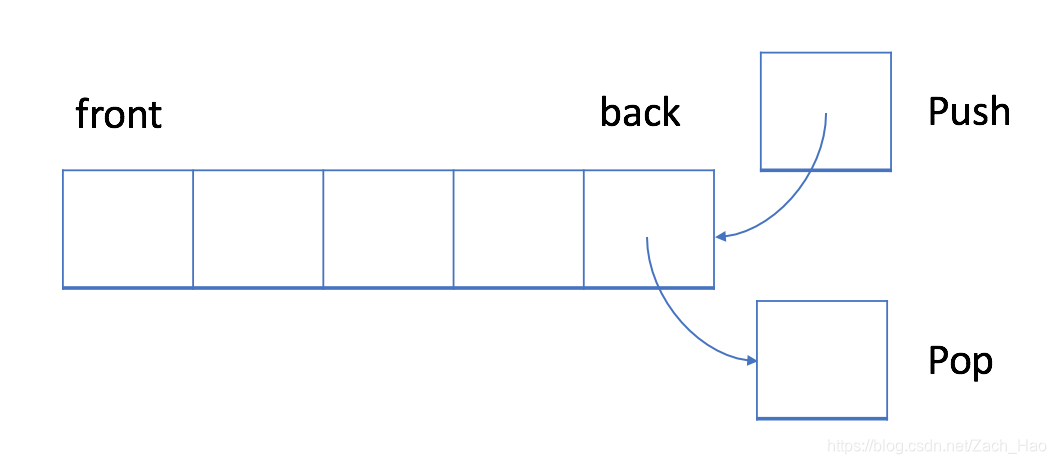
栈与队列类似,总是在堆栈的末尾添加一个新元素。但是,删除操作,将始终删除队列中相对于它的最后一个元素。
栈和深度优先搜索(DFS)
与 BFS 类似,深度优先搜索(DFS)是用于 在树/图中遍历/搜索 的另一种重要算法。也可以在更抽象的场景中使用。
通常,我们使用递归实现 DFS。栈在递归中起着重要的作用。
官方给了深度优先搜索的两个模板,一个是使用系统提供的隐性栈,另一个是防止递归深度太深产生堆栈溢出而使用显性栈。
/*
* Return true if there is a path from cur to target.
*/
boolean DFS(Node cur, Node target, Set<Node> visited) {
return true if cur is target;
for (next : each neighbor of cur) {
if (next is not in visited) {
add next to visted;
return true if DFS(next, target, visited) == true;
}
}
return false;
}
/*
* Return true if there is a path from cur to target.
*/
boolean DFS(int root, int target) {
Set<Node> visited;
Stack<Node> s;
add root to s;
while (s is not empty) {
Node cur = the top element in s;
return true if cur is target;
for (Node next : the neighbors of cur) {
if (next is not in visited) {
add next to s;
add next to visited;
}
}
remove cur from s;
}
return false;
}
这一部分官方的题目并不算难,主要是递归上要小心些,里面比较难的题目是【494. 目标和】,但是这道题目更多的是考察动态规划,先了解了解就好了。














 3292
3292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









