







课程第一部分讲的是关于线性回归和梯度下降的基本知识,虽然这部分比较容易理解,但还是有不少需要注意的点。
模型创建
在课程开始的时候老师便提到模型创建的流程:
Model
这里模型选择比较简单,选择的是线性模型:
y
=
b
+
∑
w
i
x
i
y = b + \sum w_i x_i
y=b+∑wixi
其中
x
i
x_i
xi 代表某一input,而
w
i
w_i
wi 代表相应的参数。
Goodness of Function
要对模型的预测结果是否准确进行评判,自然而然要建立输出和标签之间的函数,这个函数叫做损失函数(Loss Function),其中均方误差(mean squared error)如下:
L
(
f
)
=
1
N
∑
n
=
1
N
(
y
^
n
−
f
(
x
n
)
)
2
L(f) =\frac{1}{N} \sum_{n=1}^N (\hat{y}^n - f(x^n))^2
L(f)=N1n=1∑N(y^n−f(xn))2
除此之外还有最大似然估计等等,适用于不同的模型。
Best Function
模型训练过程目的是找到可以使损失函数最小的参数。
在使用上面的均方误差时候常常通过利用损失函数偏导来进行参数更新。
这里为什么使用偏导呢?因为偏导向量指向的是Loss Function上升的方向,所以减去偏导便可以使得Loss Function向减小的方向移动(理论上)。
因此就有参数更新式:
w
1
←
w
0
−
η
d
L
d
w
∣
w
=
w
0
w^1 \leftarrow w^0 - \eta \frac{dL}{dw}|_{w=w^0}
w1←w0−ηdwdL∣w=w0
PPT中有生动示意图:
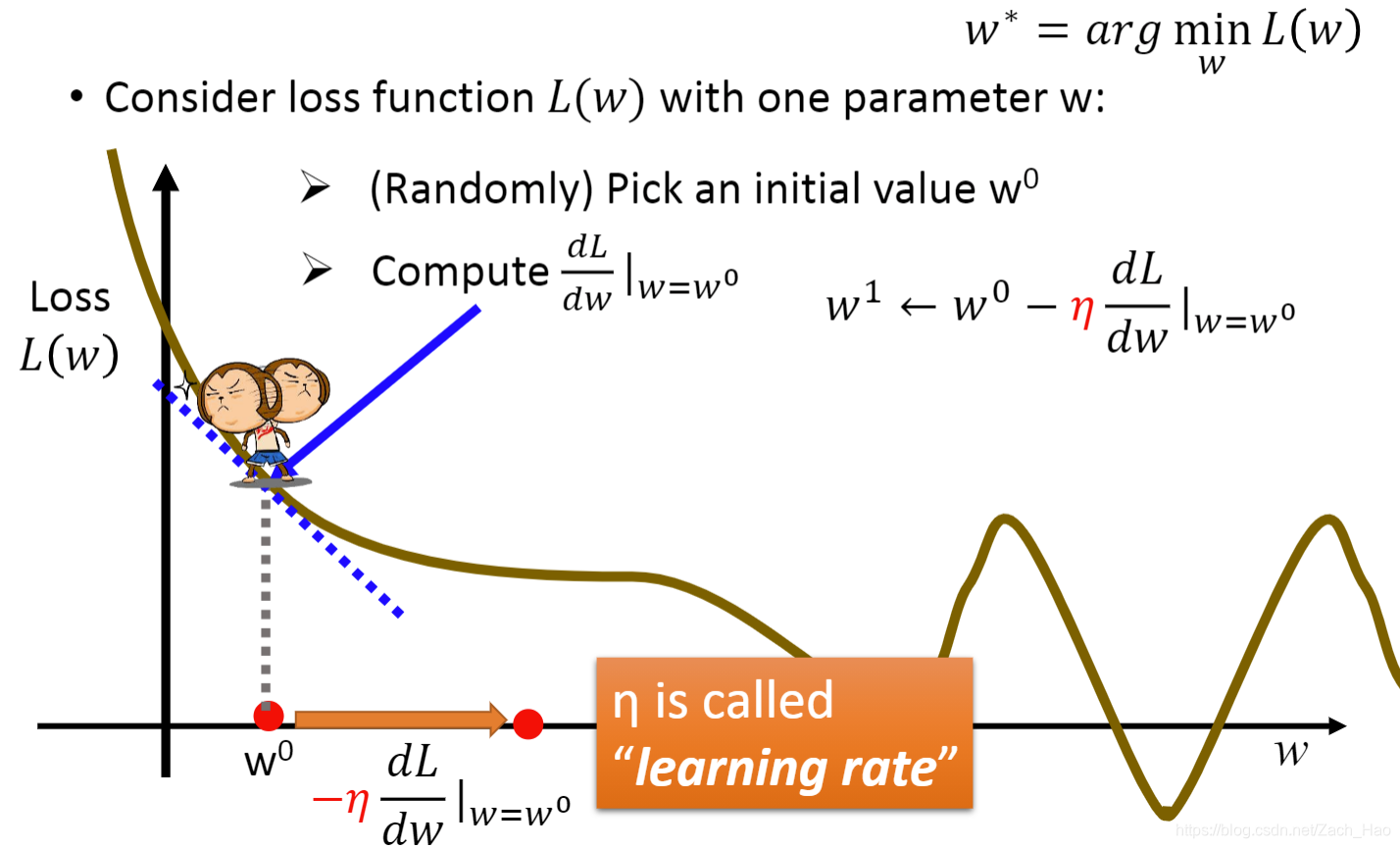
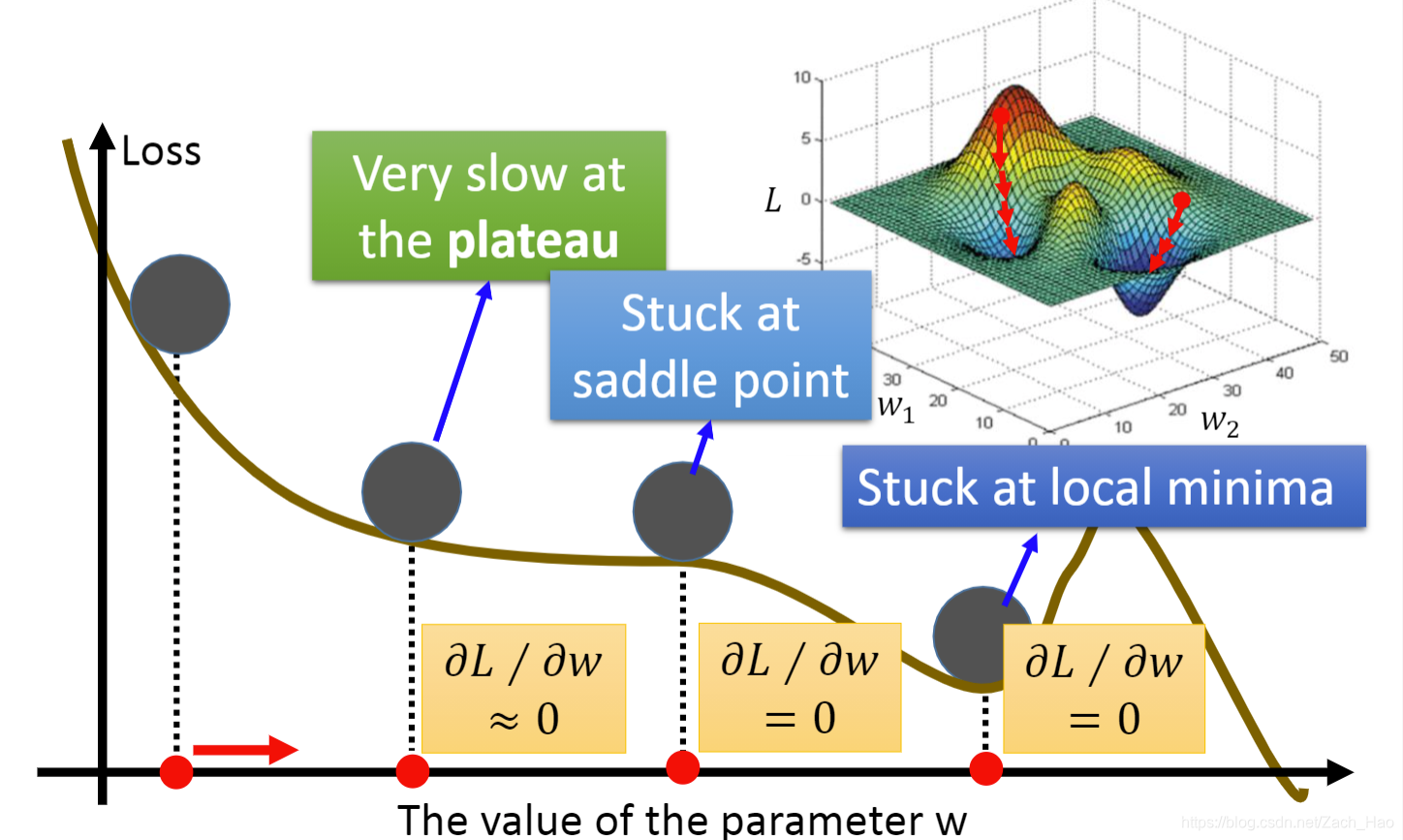
当然在使用梯度时候也会遇到一些问题,最主要的应该就是local minima问题,解决的算法现在用的比较多的是Adam算法。
下图为local minima示意图:
小结
关于模型创建时要考虑的三方面,不仅仅是自己创建模型时候需要注意而且在看论文的时候也要注意作者是在哪里做优化,这样有助于对于论文有更深刻的理解。
误差从哪里来
过拟合和欠拟合
从字面意思理解,欠拟合就是欠缺拟合,过拟合就是过度拟合。
欠拟合表现在训练集和验证集的正确率都不高,而过拟合表现在训练集正确率高但是验证集正确率低。
为什么出现这样的情况呢?欠拟合就相当于学习不够充分,不能很好的分辨结果,所以在两个集合中表现都不好;而过拟合则恰恰相反,它过度学习训练集,使得把 噪音 当作特征进行学习,而实际上噪音是没有规律的,这就导致了模型在验证集中的正确率低下。
Variance and bias
评价一个模型的好坏,输出的结果和标签之间的差以及多次结果的离散度都是需要考虑的,前者为bias,后者为variance。
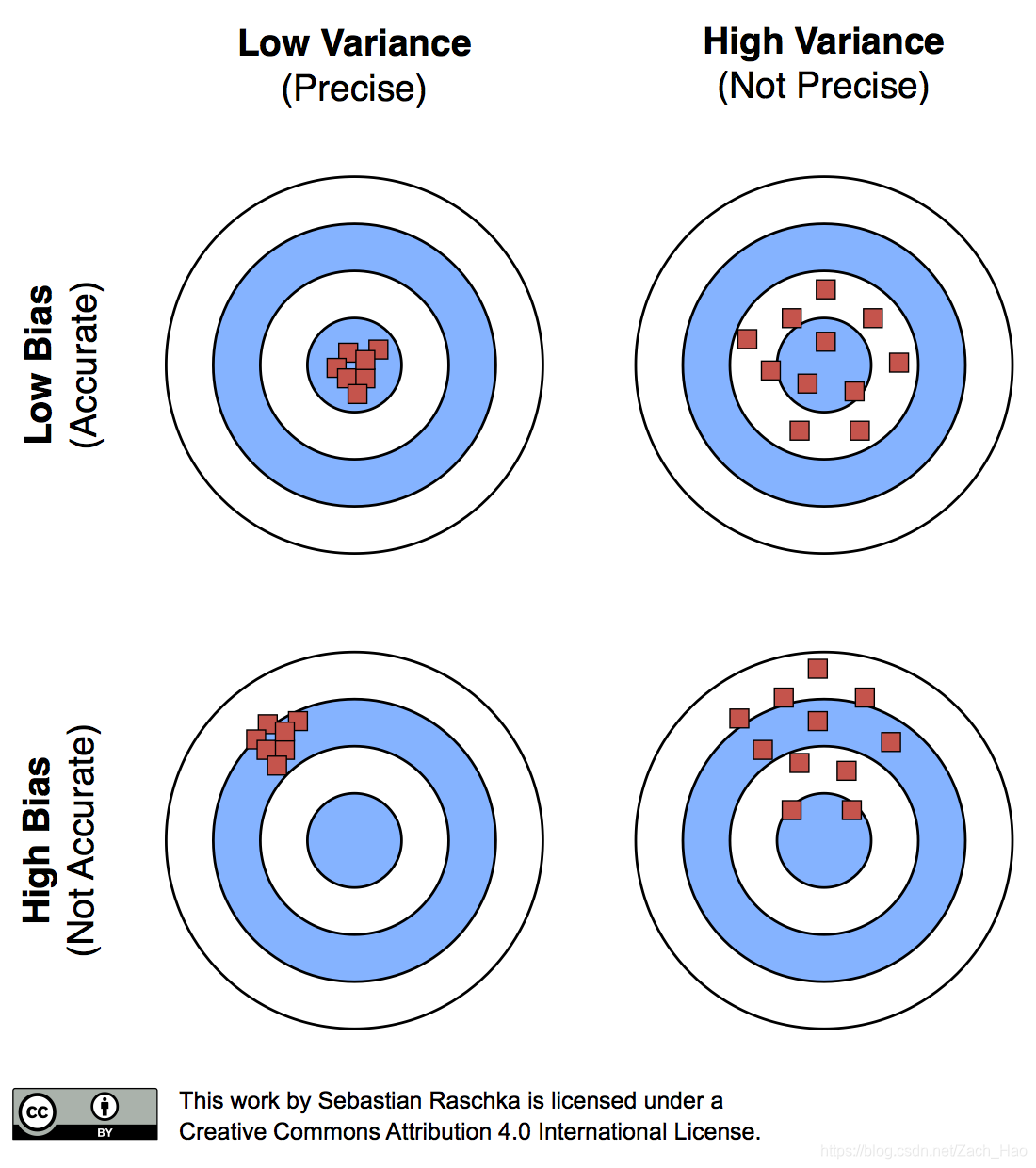
根据上图,bias就是多次结果均值和目标值之间的距离,variance是多次结果之间的方差。
解决误差的方法
bias/underfitting
产生bias绝大多数情况都是因为欠拟合,模型没有能够学到足够的知识用于完成任务。
这时候的解决思路有:
- 可能是提供的信息不够,可以尝试提供更多的特征作为输入;
- 可能是模型本身不够复杂,不足以完成相应任务,所以应该更换更复杂的模型。
variance/ overfitting
大的variance往往也是因为过拟合,因为当过拟合时候模型会学习到噪音,这会使得模型变得敏感,也就会导致大的variance。
解决思路的话,最直接的便是增加数据量,数据量足够大的时候模型就能够更好地判断哪些是噪音哪些是应该关注的点。
当然,这一方法虽然管用,但是在实际中却是很难实现,毕竟采过数据集的都知道建数据集多困难。
因此也就衍生了很多增加数据集的其他方法,像在图像中剪切图片、旋转图片甚至在图片中添加噪音等等。(之前看过用GAN生成样本的,我感觉这样不合适,,只是我感觉)
除此之外,还有什么办法呢?
使用正则化(Regularization)来修改Loss Function:
L
=
∑
n
(
y
^
n
−
(
b
+
∑
w
i
x
i
)
)
2
+
λ
∑
n
(
w
i
)
2
L = \sum_n ( \hat{y}^n - (b+\sum w_ix_i)) ^2+ \lambda \sum_n (w_i)^2
L=n∑(y^n−(b+∑wixi))2+λn∑(wi)2
上面使用的是L2正则化,相应的也有L1正则化。
使用正则化之后会使得模型参数倾向于变小,对于判断作用比较小的特征参数便趋于零,也就减小了模型复杂度,从而抑制了过拟合。
小结
我理解不同模型是用于在样本集的高维空间中进行分隔操作:
- 欠拟合就要想办法增加模型可表达的维度,要么增加输入,要么增加函数复杂度;
- 过拟合就要想办法降低模型可表达维度,要么增加数据量是函数某些维度变为定值,要么直接降低函数复杂度。














 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









