






一、使用方法
1.闲谈
我一个莫得感情的小运维,小领导跟我说要弄链路追踪,其他系统的运维人员用开源的系统(主要是查es库,有个建单功能)进行二次开发了,然后我就被无情的毒打,就说下我被elasticsearch_dsl打的最惨的过程吧。百度了一下,文章很多,有用的很少。看了官方文档,直接一脸懵逼,讲的啥,什么意思,无奈用最简单的json字符串查询。当然了是简单了不少,缺点也很严重,阅读难受,查询复杂的话,就看这个语句瞅的眼疼,而且官方也说了,后期也可能不支持了,主要推的是操作对象的方式。这篇文章是我以官方文档进行的一些解释,希望可以帮助到新接触到elasticsearch-dsl的小伙伴们。
2.前期准备
GitHub地址:https://github.com/elastic/elasticsearch-dsl-py
安装Python模块:pip install elasticsearch-dsl
pip install elasticsearch-dsl
from elasticsearch_dsl import connections
es = connections.create_connection(hosts=['localhost'], timeout=20) #连接es主机
肯定有刚接触的小伙伴问了,我不太懂es的查询语句,压根都没接触过es查询的,首先这个elasticsearch_dsl也是基于Query DSL。有个简单的方法,是我小领导跟我说的,利用kibana界面可以找到你想要的es语句,在kibana界面上输入条件,根据下面的图操作即可。
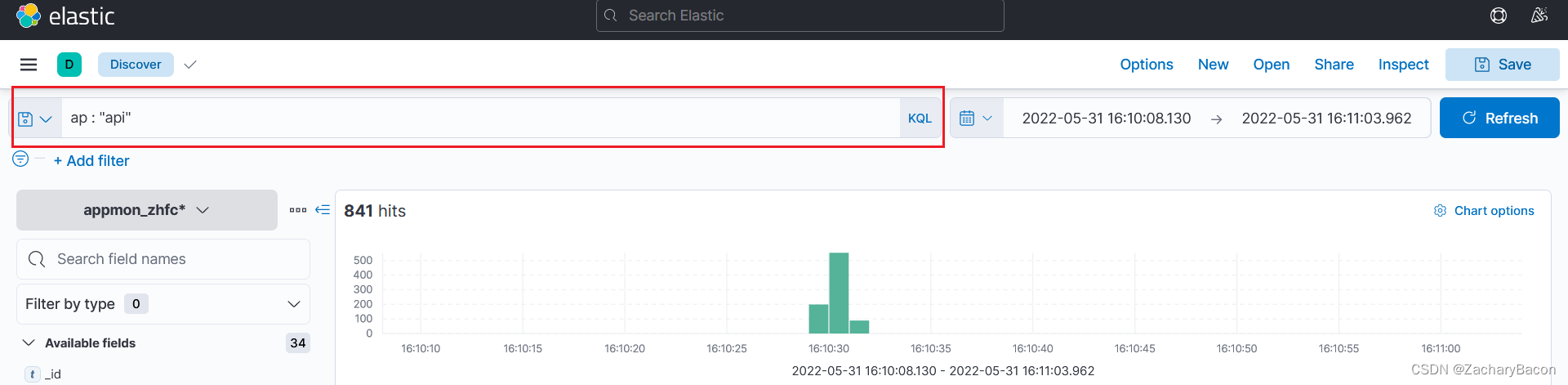
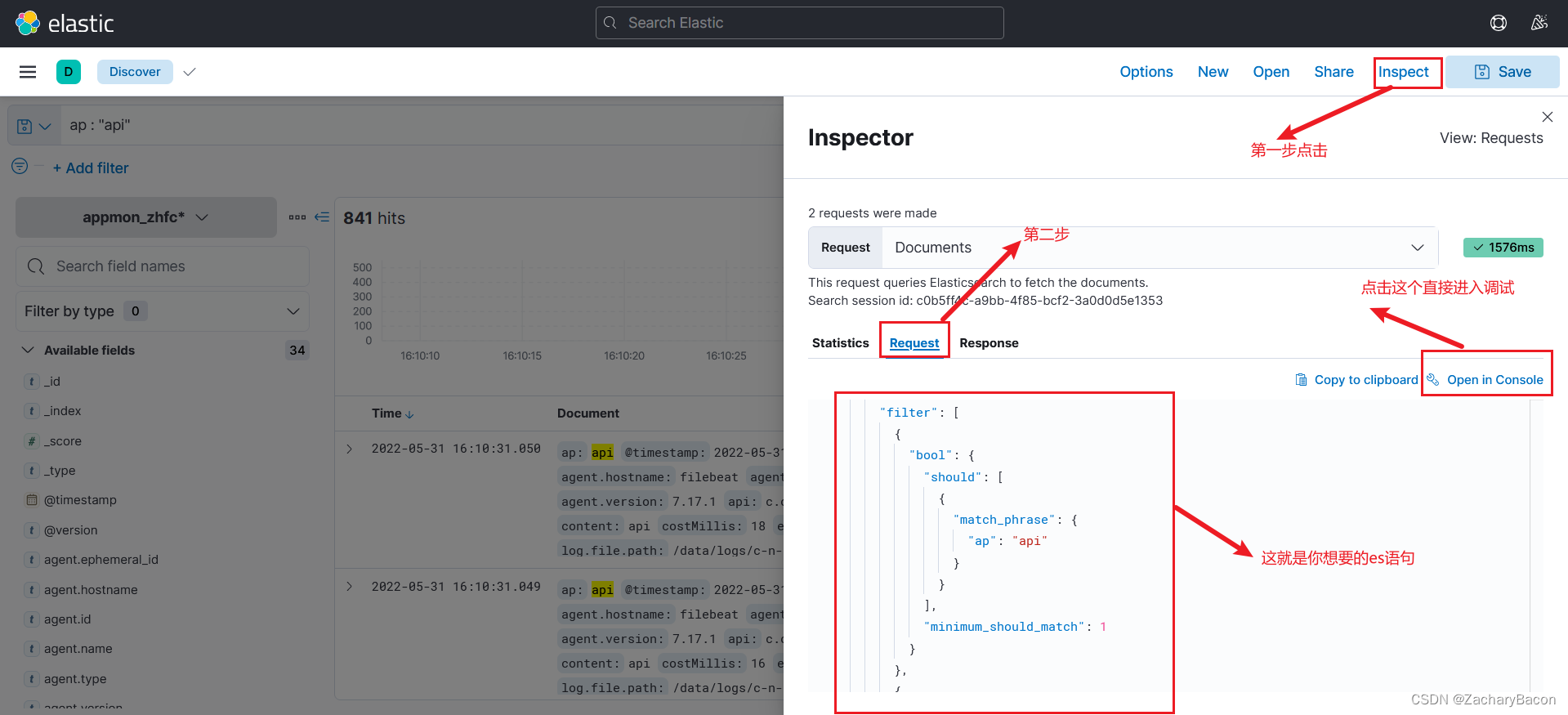
3.search查询
该Search对象代表整个搜索请求:
查询 、过滤器 、聚合、种类、分页、附加参数、关联客户
API 被设计为可链接的。除了聚合功能外,这意味着Search对象是不可变的——对对象的所有更改都将导致创建包含更改的浅表副本。这意味着您可以安全地将Search对象传递给外部代码,而不必担心它会修改您的对象,只要它坚持Search对象 API。
3.1 match快捷键Q查询
例子:
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search ,Q
es = connections.create_connection(hosts=['localhost'], timeout=20)
index="test"
s = s.query('bool', filter=[Q('terms', zhiduan=['内容'])]) # 格式是有要求的,必须是支持多个内容字段=['内容1','内容2']或者字段='内容'
e = s.to_dict() # 出于调试目的,您可以将对象显式序列化为dict,显示你的es
s = s.execute() # 上面的语句只保留在内存中,需要加了才进行es查询
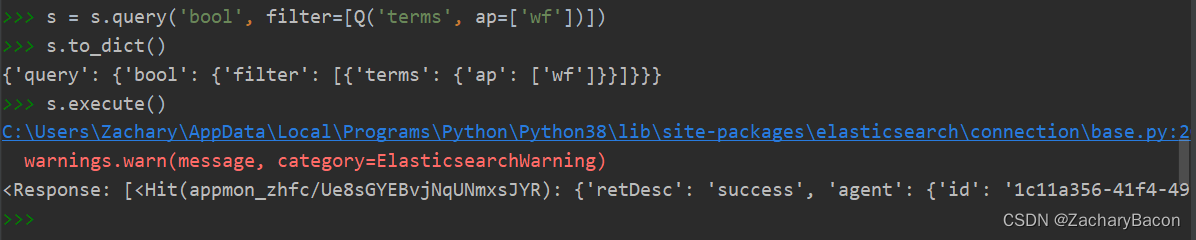
下面来自官方文档的解释:
您可以使用Q快捷方式使用带有参数的名称或 raw 来构造实例dict:
from elasticsearch_dsl import Q
Q("multi_match", query='python django', fields=['title', 'body'])
Q({"multi_match": {"query": "python django", "fields": ["title", "body"]}})
要将查询添加到Search对象,请使用以下.query()方法:
q = Q("multi_match", query='python django', fields=['title', 'body'])
s = s.query(q)
该方法还接受所有参数作为Q快捷方式:
s = s.query("multi_match", query='python django', fields=['title', 'body'])
如果您已经有一个查询对象或一个dict代表对象,您可以覆盖Search对象中使用的查询:
s.query = Q('bool', must=[Q('match', title='python'), Q('match', body='best')])
3.2 filter过滤器
如果要在过滤器上下文中添加查询, 可以使用该filter()方法使事情变得更容易:
s = Search()
s = s.filter('terms', tags=['search', 'python'])
在幕后,这将产生一个Bool查询并将指定的 terms查询放入其filter分支,使其等效于:
s = Search()
s = s.query('bool', filter=[Q('terms', tags=['search', 'python'])])
如果您想使用 post_filter 元素进行分面导航,请使用该 .post_filter()方法。
您还可以exclude()像这样从查询中获取项目:
s = Search()
s = s.exclude('terms', tags=['search', 'python'])
这是以下的简写:s = s.query('bool', filter=[~Q('terms', tags=['search', 'python'])])
上面是官方的介绍,还一个大坑就是下面这张图,官方的介绍是使用时间范围的方法,然后我直接套入了操作对象的语句中,结果是报错,搞到我怀疑人生,为什么写到match查询下面,又不能用match查询时间,最最最重要的是,语法也不对啊,这官方是想让我猜??坑啊!!!
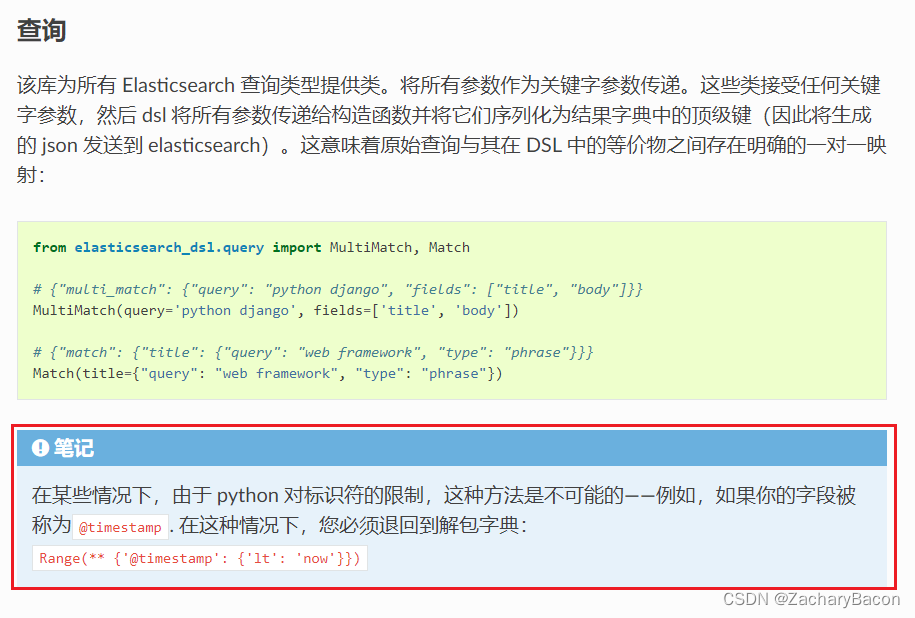
下面kibana的调试语法的时间范围也是在filter字段下,大家有不同的方法可以在下面留言交流。
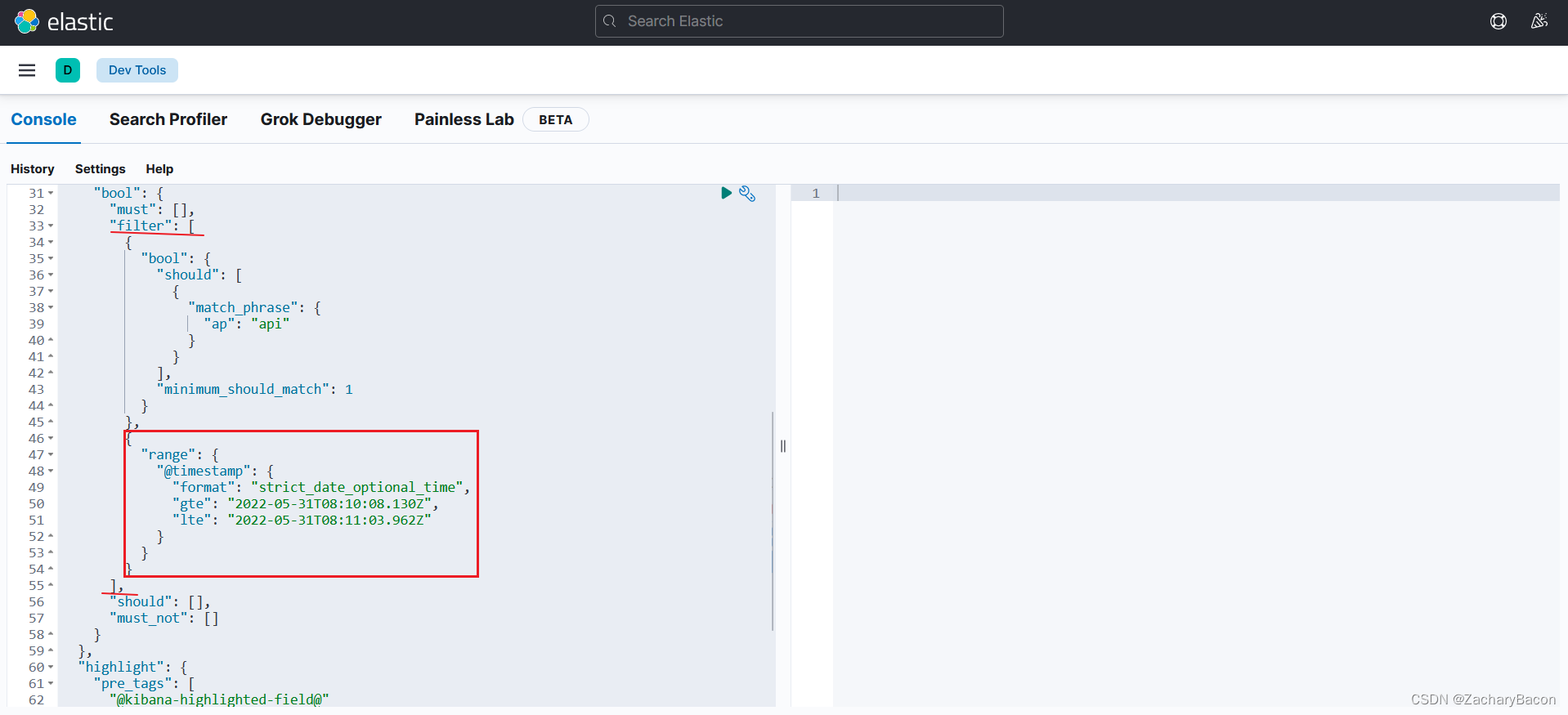
我把时间范围正确的用法给大家举个例子:
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search ,Q
es = connections.create_connection(hosts=['localhost'], timeout=20)
index="test"
s = Search(using=es, index=index)
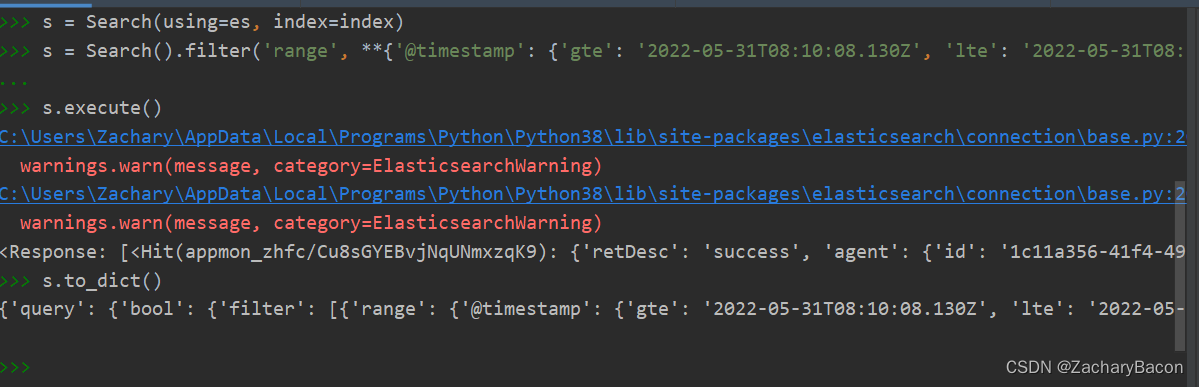
s = Search().filter('range', **{'@timestamp': {'gte': '2022-05-31T08:10:08.130Z', 'lte': '2022-05-31T08:11:03.962Z'}}).query('match', ap="test") #实际用法跟官方的还是有点不一样的,坑死人,搞了我好久
s = s.execute()
下面我们看下es语句:
{'query': {'bool': {'filter': [{'range': {'@timestamp': {'gte': '2022-05-31T08:10:08.130Z', 'lte': '2022-05-31T08:11:03.962Z'}}}], 'must': [{'match': {'ap': 'test'}}]}}}
4.聚合快捷键A
要定义聚合,您可以使用A快捷方式:
from elasticsearch_dsl import A
A('terms', field='tags')
# {"terms": {"field": "tags"}}
要嵌套聚合,您可以使用.bucket(),.metric()和 .pipeline()方法:
a = A('terms', field='category')
# {'terms': {'field': 'category'}}
a.metric('clicks_per_category', 'sum', field='clicks')\
.bucket('tags_per_category', 'terms', field='tags')
# {
# 'terms': {'field': 'category'},
# 'aggs': {
# 'clicks_per_category': {'sum': {'field': 'clicks'}},
# 'tags_per_category': {'terms': {'field': 'tags'}}
# }
# }
要将聚合添加到Search对象,请使用.aggs属性,它充当顶级聚合:
s = Search()
a = A('terms', field='category')
s.aggs.bucket('category_terms', a)
# {
# 'aggs': {
# 'category_terms': {
# 'terms': {
# 'field': 'category'
# }
# }
# }
# }
或者
s = Search()
s.aggs.bucket('articles_per_day', 'date_histogram', field='publish_date', interval='day')\
.metric('clicks_per_day', 'sum', field='clicks')\
.pipeline('moving_click_average', 'moving_avg', buckets_path='clicks_per_day')\
.bucket('tags_per_day', 'terms', field='tags')
s.to_dict()
# {
# "aggs": {
# "articles_per_day": {
# "date_histogram": { "interval": "day", "field": "publish_date" },
# "aggs": {
# "clicks_per_day": { "sum": { "field": "clicks" } },
# "moving_click_average": { "moving_avg": { "buckets_path": "clicks_per_day" } },
# "tags_per_day": { "terms": { "field": "tags" } }
# }
# }
# }
# }
上面官方的文档介绍的很详细,也很容易懂,我就不在解释了,给大家分享一个我写算平均时间的例子:
def avgRspTime(self, es_q ):
es_q = Q('bool',
should=[Q('match_phrase', timestamp="2022-04-01 11:45")], # 查询4月1号11点45分的数据,是根据一分钟计算一次
minimum_should_match=1
) & Q('bool',
should=[Q('match_phrase', ap='test')], #这里是搜索条件
minimum_should_match=1
)
t_avg = Search(using=es, index=index_search).query('bool', filter=es_q ) #根据搜索条件筛选的数据
a_avg = A('stats', field='costMillis') #根据costMillis这个字段进行聚合
t_avg.aggs.bucket('costMillis', a_avg) #加入查询语句中
# {'query': {'bool': {'filter': [{'bool': {'must': [{'match_phrase': {'timestamp': '2022-04-01 11:45'}}, {'match_phrase': {'ap': 'api'}}]}}]}}, 'aggs': {'costMillis': {'stats': {'field': 'costMillis'}}}} 这个是es查询语句,经过反序列化过的
res_avg = t_avg.execute()
t_avgtime = res_avg.aggregations.costMillis.avg
# print(res_avg.aggregations.costMillis)
# 保留2位小数点
return round(t_avgtime, 2)
再给大家分享一下经验,关于es库索引字段的问题:
默认是text,支持模糊查询,支持饼图(有些字段用饼图挺直观的),不支持聚合,但是某些时候text的.keyword是偶尔支持聚合的,万一不能用聚合还是老实的用keyword字段。
keyword字段是支持聚合,饼图的,不支持模糊查询。
数字和小数点,支持聚合,统计,计算的,不支持饼图。
5.Index索引
大家可以看官方的介绍,我就不一一介绍了,就是一个api的介绍。分享我写的给大家一个参考:
def init_index(self, index_n):
imp_code_mapping = {
"a": "float",
"b": "long",
"c": "float",
"d": "float",
"e": "float",
"f": "float",
"g": "long",
"h": "float",
"i": "keyword",
"j": "short"
} # 这个是索引字典,下面会用到这个字典的
i = Index(index_n, using=es)
index_info = i.exists()
if index_info is False:
print("未检测到es索引" + index_n + ", 开始创建索引......")
i.create() # 在 elasticsearch 中创建索引。
m = Mapping() # 将映射(的实例 Mapping)与此索引相关联。这意味着,当创建此索引时,它将包含由这些映射定义的文档类型的映射
# m.field('category', 'text', fields={'category': es_dsl.Keyword()})
for k, v in imp_code_mapping.items():
m.field(k, v)
print(m.to_dict())
m.save(index_n)
print(index_n + "索引创建成功!!!")
总结:
我暂时就使用了怎么多的功能,也就研究和踩坑了怎么多,第一次看一脸懵逼,我要是能看的懂官方的文档,也不会写这篇文章了,实在是太坑了,搞了好久才弄明白的。唉!太坑了,大家点赞,不过分吧。














 2739
2739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









