







Elasticsearch 入门(一)
简介
Elasticsearch是一个全文检索引擎,底层的使用的就是Lucene这个jar包,本身是基于java实现,通过暴露api接口,来实现多语言使用。
场景
- 搜索商品,词条等
- ES配合logstash,kibana,日志分析
常规使用方式
- 已有系统接入ES搜索
- ES作为主要后端系统
- ES作为独立应用使用
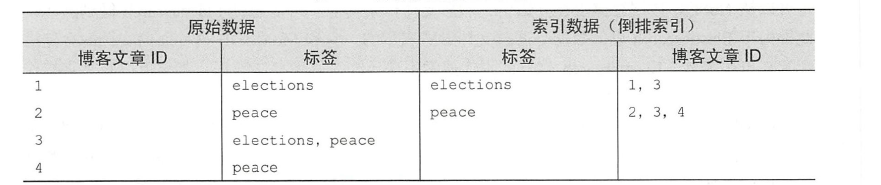
倒排索引
对文档索引的时候,通过分词插件把全文关键词建立相关的索引,然后通过关键词关联文档,这就是倒排索引
搜索结果相关性
通过检索的关键词在文本中出现的频次越高(词频),文档的相关性也越高。如果关键词有多个,会根据出现较少的关键词作为主要主要相关性得分(逆文档词频)。计算文档相关得分的算法主要为TF-IDF(后期文章再来讨论),ES本身还有内置很多功能计算相关性得分,例如点赞数比内容更重要,或者像百度的竞价排名(给得多自然排得靠前)。
ES支持其他功能
- 处理错误拼写
- 支持变体
- 给予统计信息
- 给予自动提示
ES组织数据
ES跟数据库相似,一个拥有表、行、字段等,ES也有键值文档等,
但是ES是用文档存储数据,更加灵活,是因为文档是可以具有层次型的,{“book”:“测试”,“number”:“No1”}。这样的层次是非常有作用的,你可以把逻辑实体的数据保存在同一个文档中,而不是让他散落在不同表的不同行中,如果把一篇博文的所有信息保存在一个文档中,那么这可能是搜索最快也是最容易保存的方式,因为不需要像关系型数据库那样需要关联查询。
实时性
jdk
7.x默认使用jdk11,但是如果没有安装jdk11也可以,因为ES包中带有运行环境的jdk版本
安装使用
- windows 解压直接运行 elasticsearch.bat
- linxu 解压运行 elasticsearch.sh
常规配置参数
| 参数 | 说明 |
|---|---|
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| path.data | 索引数据存放的位置 |
| path.logs | 日志文件存放的位置 |
| bootstrap.memory_lock | 需求锁住物理内存,是:true、否:false |
| bootstrap.system_call_filter | SecComp检测,是:true、否:false |
| network.host | 监听地址,用于访问该es |
| network.publish_host | 可设置成内网ip,用于集群内各机器间通信 |
| http.port | es对外提供的http端口,默认 9200 |
| transport.tcp.port | TCP的默认监听端口,默认 9300 |
| discovery.seed_hosts | es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin | “*” 表示支持所有域名 |
谷歌插件
elasticsearch head 可视化操作ES


















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









