







视学算法报道
编辑:好困
【导读】为了应对多模态假新闻,本文提出检测并定位多模态媒体篡改任务(DGM)。与现有的单模态DeepFake检测任务相比,DGM不仅判断输入图像-文本对的真假,也尝试定位篡改内容(例如图像篡改区域和文本篡改单词)。
由于如Stable Diffusion等视觉生成模型的快速发展,高保真度的人脸图片可以自动化地伪造,制造越来越严重的DeepFake问题。
随着如ChatGPT等大型语言模型的出现,大量假本文也可以容易地生成并恶意地传播虚假信息。
为此,一系列单模态检测模型被设计出来,去应对以上AIGC技术在图片和文本模态的伪造。但是这些方法无法较好应对新型伪造场景下的多模态假新闻篡改。
具体而言,在多模态媒体篡改中,各类新闻报道的图片中重要人物的人脸(如图 1 中法国总统人脸)被替换,文字中关键短语或者单词被篡改(如图 1 中正面短语「is welcome to」被篡改为负面短语「is forced to resign」)。
这将改变或掩盖新闻关键人物的身份,以及修改或误导新闻文字的含义,制造出互联网上大规模传播的多模态假新闻。
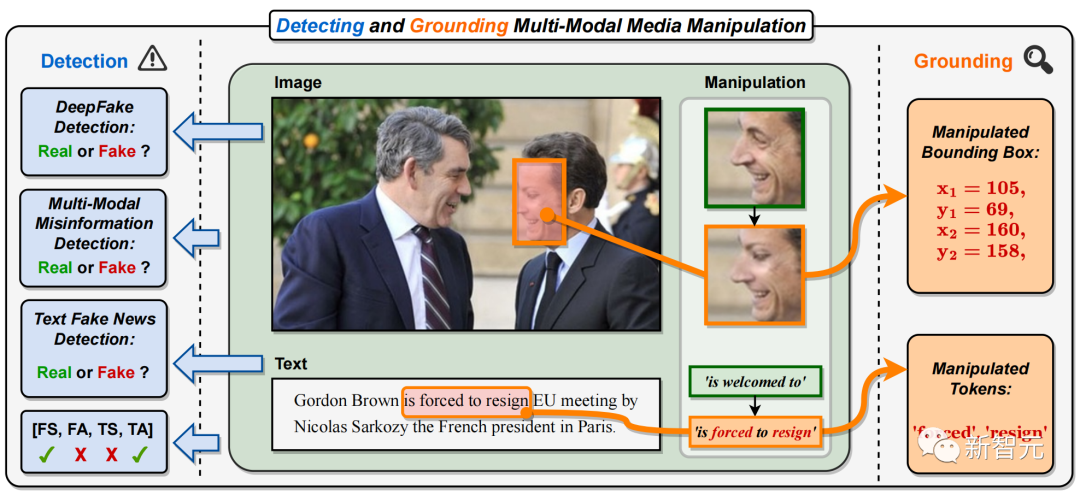
图1. 本文提出检测并定位多模态媒体篡改任务(DGM4)。与现有的单模态DeepFake检测任务不同,DGM4不仅对输入图像-文本对预测真假二分类,也试图检测更细粒度的篡改类型和定位图像篡改区域和文本篡改单词。除了真假二分类之外,此任务对篡改检测提供了更全面的解释和更深入的理解。

表1: 所提出的DGM4与现有的图像和文本伪造检测相关任务的比较
检测并定位多模态媒体篡改任务
为了解此新挑战,来自哈工大(深圳)和南洋理工的研究人员提出了检测并定位多模态媒体篡改任务(DGM4)、构建并开源了DGM4数据集,同时提出了多模态层次化篡改推理模型。目前,该工作已被CVPR 2023收录。

论文地址:https://arxiv.org/abs/2304.02556
GitHub:https://github.com/rshaojimmy/MultiModal-DeepFake
项目主页:https://rshaojimmy.github.io/Projects/MultiModal-DeepFake
如图1和表1所示,检测并定位多模态媒体篡改任务(Detecting and Grounding Multi-Modal Media Manipulation (DGM4))和现有的单模态篡改检测的区别在于:
1)不同于现有的DeepFake图像检测与伪造文本检测方法只能检测单模态伪造信息,DGM4要求同时检测在图像-文本对中的多模态篡改;
2)不同于现有DeepFake检测专注于二分类,DGM4进一步考虑了定位图像篡改区域和文本篡改单词。这要求检测模型对于图像-文本模态间的篡改进行更全面和深入的推理。
检测并定位多模态媒体篡改数据集
为了支持对DGM4研究,如图2所示,本工作贡献了全球首个检测并定位多模态媒体篡改(DGM4)数据集。

图2. DGM4数据集
DGM4数据集调查了4种篡改类型,人脸替换篡改(FS)、人脸属性篡改(FA)、文本替换篡改(TS)、文本属性篡改(TA)。
图2展示了 DGM4 整体统计信息,包括(a) 篡改类型的数量分布;(b) 大多数图像的篡改区域是小尺寸的,尤其是对于人脸属性篡改;(c) 文本属性篡改的篡改单词少于文本替换篡改;(d)文本情感分数的分布;(e)每种篡改类型的样本数。
此数据共生成23万张图像-文本对样本,包含了包括77426个原始图像-文本对和152574个篡改样本对。篡改样本对包含66722个人脸替换篡改,56411个人脸属性篡改,43546个文本替换篡改和18588个文本属性篡改。
多模态层次化篡改推理模型
本文认为多模态的篡改会造成模态间细微的语义不一致性。因此通过融合与推理模态间的语义特征,检测到篡改样本的跨模态语义不一致性,是本文应对DGM4的主要思路。
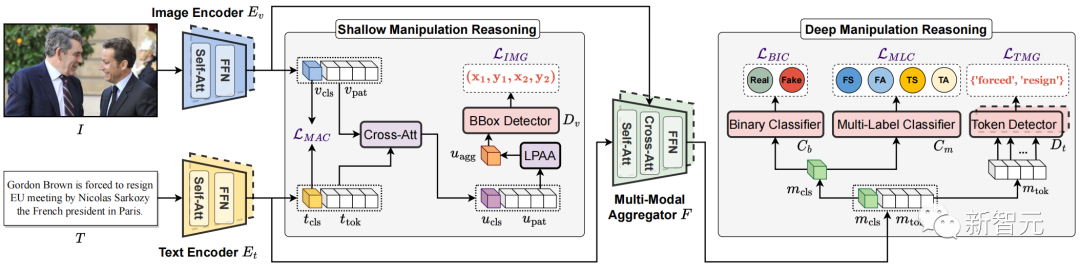
图3. 提出的多模态层次化篡改推理模型HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER)
基于此想法,如图3所示,本文提出了多模态层次化篡改推理模型HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER)。
此模型建立在基于双塔结构的多模态语义融合与推理的模型架构上,并将多模态篡改的检测与定位细粒度层次化地通过浅层与深层篡改推理来实现。
具体而言,如图3所示,HAMMER模型具有以下两个特点:
1)在浅层篡改推理中,通过篡改感知的对比学习(Manipulation-Aware Contrastive Learning)来对齐图像编码器和文本编码器提取出的图像和文本单模态的语义特征。同时将单模态嵌入特征利用交叉注意力机制进行信息交互,并设计局部块注意力聚合机制(Local Patch Attentional Aggregation)来定位图像篡改区域;
2)在深层篡改推理中,利用多模态聚合器中的模态感知交叉注意力机制进一步融合多模态语义特征。在此基础上,进行特殊的多模态序列标记(multi-modal sequence tagging)和多模态多标签分类(multi-modal multi-label classification)来定位文本篡改单词并检测更细粒度的篡改类型。
实验结果
如下图,实验结果表明研究团队提出的HAMMER与多模态和单模态检测方法相比,都能更准确地检测并定位多模态媒体篡改。

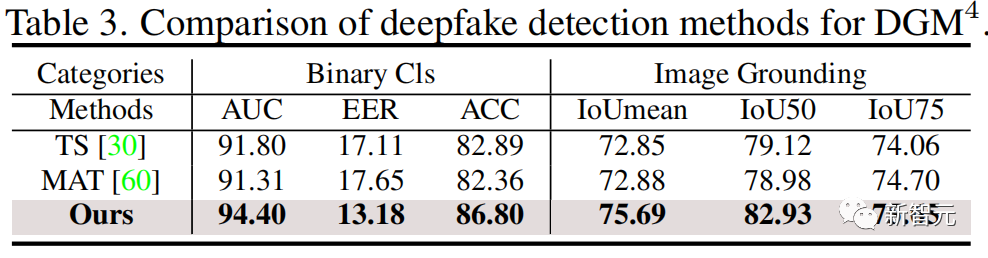
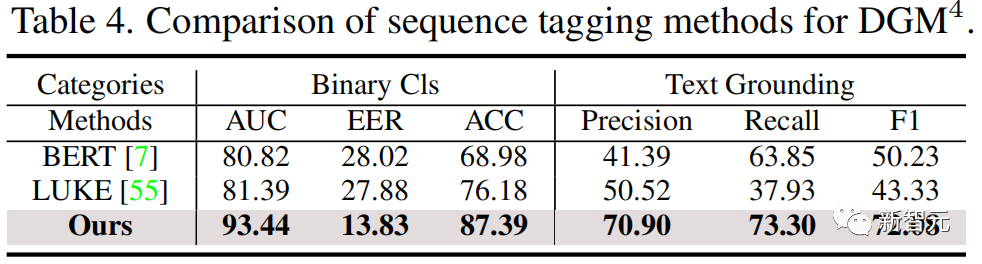

图4. 多模态篡改检测和定位结果可视化

图5. 关于篡改文本的模型篡改检测注意力可视化
图4提供了一些多模态篡改检测和定位的可视化结果,说明了HAMMER可以准确地同时进行篡改检测与定位任务。图5提供了关于篡改单词的模型注意力可视化结果,进一步展示了HAMMER是通过关注与篡改文本语义不一致性的图像区域来进行多模态篡改检测和定位。
总结
本工作提出了一个新的研究课题:检测并定位多模态媒体篡改任务,来应对多模态假新闻。
本工作贡献了首个大规模的检测并定位多模态媒体篡改数据集,并提供了详细丰富的篡改检测与定位的标注。团队相信它可以很好地帮助未来多模态假新闻检测的研究。
本工作提出了一个强大的多模态层次化篡改推理模型作为此新课题很好的起始方案。
本工作的代码和数据集链接都已分享在本项目的GitHub上,欢迎大家Star这个GitHub Repo, 使用DGM4数据集和HAMMER来研究DGM4问题。DeepFake领域不只有图像单模态检测,还有更广阔的多模态篡改检测问题亟待大家解决!
参考资料:
https://arxiv.org/abs/2304.02556


点个在看 paper不断!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









