







一、Transformer架构解析
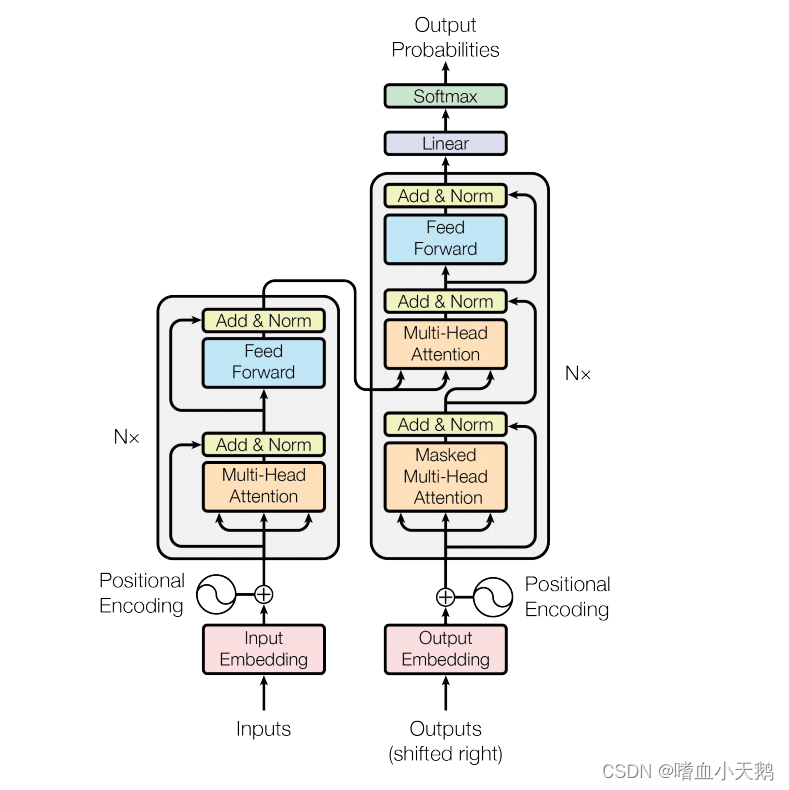
1.Transformer总体架构可分为四部分
输入部分、输出部分、编码器部分、解码器部分。
如图所示:左边为编码器部分,右边为解码器部分。
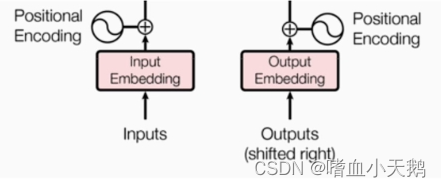
1.1输入部分:
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
源文本先进入一个Embedding(文本嵌入层)进行一个位置编码器的处理。
目标文本进入一个Embedding进行一个位置编码器的处理。
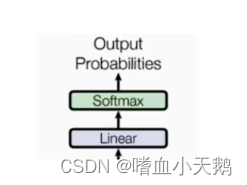
1.2输出部分:
- 线性层
- softmax层
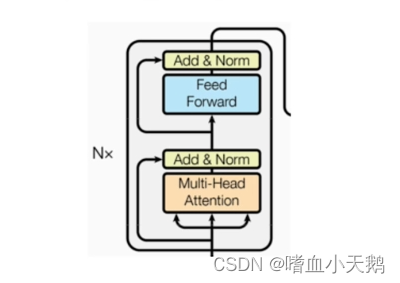
1.3编码器部分:
- 由N个编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
N为超参数,由程序员指定
残差链接:可以跨层向上传递信息
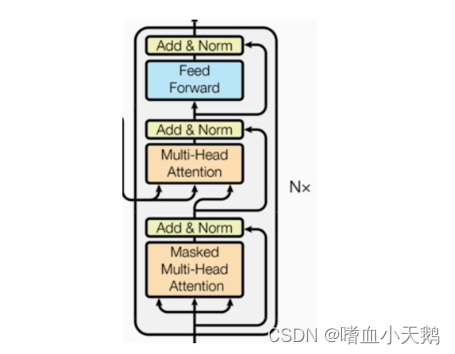
1.4解码器部分
- 由N个编码器层堆叠而成
- 每个编码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层(加了一个mask掩码)和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
小节总结:
- 学习Transformer模型的作用:
- 基于seq2seq架构的transformer模型可以完成NLP领域研究的典型任务如机器翻译文本生成等同时又可以构建预训练语言模型,用于不同任务的迁移学习















 5917
5917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









