







 本文探讨了CNN如何应用于中文文本分类任务,详细介绍了CNN模型的四部分结构:输入层、卷积层、池化层和全连接+softmax层。在训练过程中采用了Dropout和L2正则化防止过拟合,并使用minibatch和shuffle_batch优化样本处理。实验使用搜狗语料库,调整word vector size和feature maps size得到不错的效果。
本文探讨了CNN如何应用于中文文本分类任务,详细介绍了CNN模型的四部分结构:输入层、卷积层、池化层和全连接+softmax层。在训练过程中采用了Dropout和L2正则化防止过拟合,并使用minibatch和shuffle_batch优化样本处理。实验使用搜狗语料库,调整word vector size和feature maps size得到不错的效果。
深度学习近一段时间以来在图像处理和NLP任务上都取得了不俗的成绩。通常,图像处理的任务是借助CNN来完成的,其特有的卷积、池化结构能够提取图像中各种不同程度的纹理、结构,并最终结合全连接网络实现信息的汇总和输出。RNN由于其记忆功能为处理NLP中的上下文提供了途径。
在短文本分析任务中,由于句子句长长度有限、结构紧凑、能够独立表达意思,使得CNN在处理这一类问题上成为可能。论文Convolutional Neural Networks for Sentence Classification(论文作者Yoon Kim)即在这一类问题上做了尝试。首先来看看论文中介绍的模型结构及原理:
CNN模型结构如下:
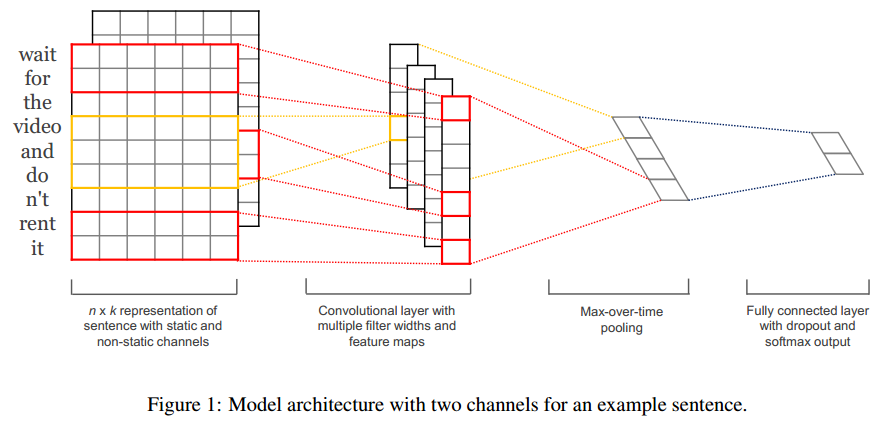
一共包括4部分:
1、 输入层:
如图所示,输入层是句子中的词语对应的wordvector依次(从上到下)排列的矩阵,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n × k 的(在CNN中可以看作一副高度为n、宽度为k的图像)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









