






本地部署大语言模型的成熟路径是硬件加速支持库(如需GPU加速)+本地大语言模型运行框架+本地AI应用用户界面,本文以安装有NVIDIA GPU的Windows系统为例,在本地部署DeepSeek-R1模型,选用的本地大语言模型运行框架是Ollama、本地AI应用用户界面是AnythingLLM。
NVIDIA GPU加速
注意:如果没有GPU或不需要GPU加速,可以直接跳过此部分。
1. GPU计算能力检查:Ollama 支持计算能力 5.0 及以上的 NVIDIA GPU。可在以下链接查看显卡的计算能力:Ollama文档提供常见NVIDIA GPU的计算能力供大家快速检索:
| Compute Capability | Family | Cards |
| ------------------ | ------------------- | ----------------------------------------------------------------------------------------------------------- |
| 9.0 | NVIDIA | `H100` |
| 8.9 | GeForce RTX 40xx | `RTX 4090` `RTX 4080` `RTX 4070 Ti` `RTX 4060 Ti` |
| | NVIDIA Professional | `L4` `L40` `RTX 6000` |
| 8.6 | GeForce RTX 30xx | `RTX 3090 Ti` `RTX 3090` `RTX 3080 Ti` `RTX 3080` `RTX 3070 Ti` `RTX 3070` `RTX 3060 Ti` `RTX 3060` |
| | NVIDIA Professional | `A40` `RTX A6000` `RTX A5000` `RTX A4000` `RTX A3000` `RTX A2000` `A10` `A16` `A2` |
| 8.0 | NVIDIA | `A100` `A30` |
| 7.5 | GeForce GTX/RTX | `GTX 1650 Ti` `TITAN RTX` `RTX 2080 Ti` `RTX 2080` `RTX 2070` `RTX 2060` |
| | NVIDIA Professional | `T4` `RTX 5000` `RTX 4000` `RTX 3000` `T2000` `T1200` `T1000` `T600` `T500` |
| | Quadro | `RTX 8000` `RTX 6000` `RTX 5000` `RTX 4000` |
| 7.0 | NVIDIA | `TITAN V` `V100` `Quadro GV100` |
| 6.1 | NVIDIA TITAN | `TITAN Xp` `TITAN X` |
| | GeForce GTX | `GTX 1080 Ti` `GTX 1080` `GTX 1070 Ti` `GTX 1070` `GTX 1060` `GTX 1050` |
| | Quadro | `P6000` `P5200` `P4200` `P3200` `P5000` `P4000` `P3000` `P2200` `P2000` `P1000` `P620` `P600` `P500` `P520` |
| | Tesla | `P40` `P4` |
| 6.0 | NVIDIA | `Tesla P100` `Quadro GP100` |
| 5.2 | GeForce GTX | `GTX TITAN X` `GTX 980 Ti` `GTX 980` `GTX 970` `GTX 960` `GTX 950` |
| | Quadro | `M6000 24GB` `M6000` `M5000` `M5500M` `M4000` `M2200` `M2000` `M620` |
| | Tesla | `M60` `M40` |
| 5.0 | GeForce GTX | `GTX 750 Ti` `GTX 750` `NVS 810` |
| | Quadro | `K2200` `K1200` `K620` `M1200` `M520` `M5000M` `M4000M` `M3000M` `M2000M` `M1000M` `K620M` `M600M` `M500M` |
2. 安装CUDA toolkit:在此链接下载CUDA toolkit,注意选择Windows的版本(如Win10、Win11等),建议下载local安装类型。此下载需要NVIDIA账号,请注册。安装完成后需重启电脑使配置生效。
本地大语言模型运行框架Ollama及DeepSeek-R1模型安装
1. Ollama安装:在Ollama官网下载Ollama并安装,此步骤极为简单,不在此赘述了。安装启动后,Ollama是在后台运行的,检查右下角托盘里有没有Ollama的Logo就可以了。
2. 通过Ollama安装DeepSeek-R1模型:Ollama模型库中包含多种支持的大语言模型,如DeepSeek-R1,Lamma3.3等:
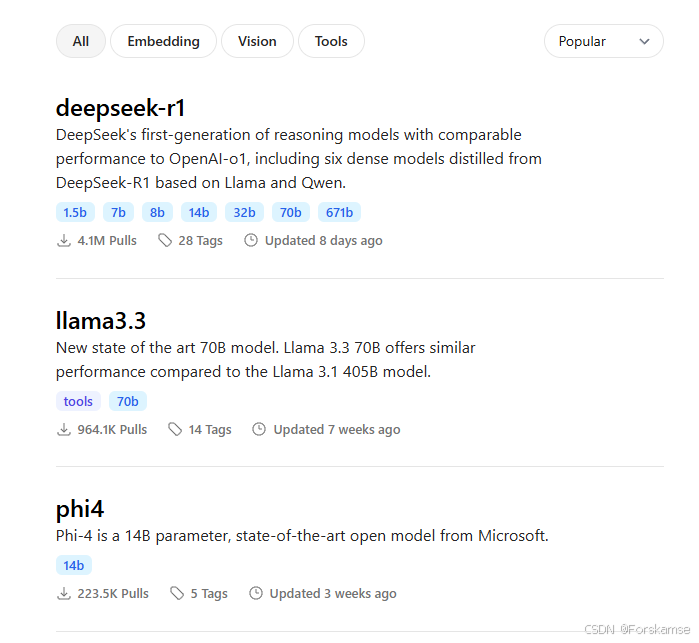
进入deepseek-r1集合,按下图顺序选择参数数量和复制安装命令。注意GPU显存(或本地主机的内存,如果仅使用CPU)限制了可以使用的模型的大小,16GB显存的GPU可以运行14b的模型,24GB显存的GPU可以运行32b的模型。这里本人选择14b的模型,复制命令后在Powershell里执行,ollama会自动安装相应版本的deepseek-r1模型,只需等待命令运行结束即可:
ollama run deepseek-r1:14b

本地AI应用用户界面安装
实际上,通过Ollama安装完DeepSeek-R1模型后,在Powershell中可以直接运行,只需要在Powershell里再次执行:
ollama run deepseek-r1:14b

但是,在Powershell此类terminal中直接运行的话,难以保存、搜索、管理对话记录、难以读取附件、无法集成本地知识库实现检索增强生成(Retrieval-Augmented Generation,RAG)等功能,对用户十分不友好。因此,十分推荐大家安装一个本地AI应用用户界面,常用的有AnythingLLM、Open WebUI等。本文选择AnythingLLM作为示范。
AnythingLLM安装与配置:在AnythingLLM官网下载AnythingLLM并安装,此步骤亦十分简单,不再赘述。安装启动后,选择Ollama(注意不是DeepSeek)为LLMProvider,会自动检查本地部署的大语言模型,选择deepseek-r1:14b即可。创建Workspace后,即可开始对话:

AnythingLLM的功能请自行探索。

















 3583
3583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









