






首先从kafka到flink,代码如下
package com.sungrow.kafka_redis_flinkx;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class kafka_to_flink {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置Kafka相关参数,连接对应的服务器和端口号
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.0.81.158:9092");
properties.setProperty("group.id", "flink_kafka_redis");//当前消费者组的group id
String inputTopic = "kafka_data"; //要读取的本地数据源
String outputTopic = "WordCount"; //输出wordcount
//读取名为Shakespeare的Topic中的数据源,将数据源命名为stream
FlinkKafkaConsumer<String> kafkaStream = new FlinkKafkaConsumer<String>(inputTopic, new SimpleStringSchema(), properties);
DataStream<String> stream = env. addSource(kafkaStream);
//使用Flink算子处理这个数据流:
// 使用Flink算子对输入流的文本进行操作
// 按空格切词、计数、分区、设置时间窗口、聚合
//3、转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = stream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(",");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//4、分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5、求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
//6、打印
sum.print();
stream.print();
env.execute();
}
}
在Xshell上开启kafka集群,集群开启的地址、命令、和发送生产这消息的命令如下

然后在Idea开发环境上运行代码如下图:
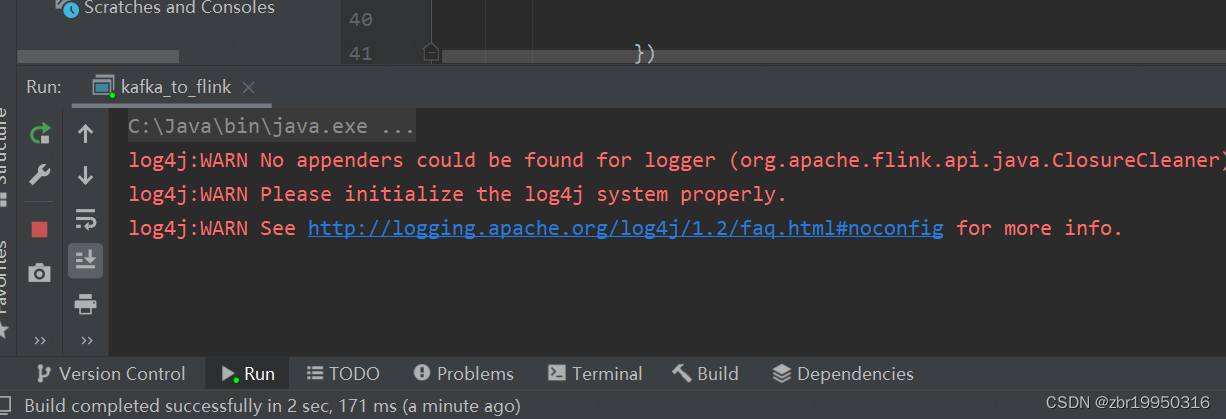
在kafka集群发送消息如下,随便输入几个String类型的单词

此时控制台上已经接受到来自kafka发送的消息并处理,如下图
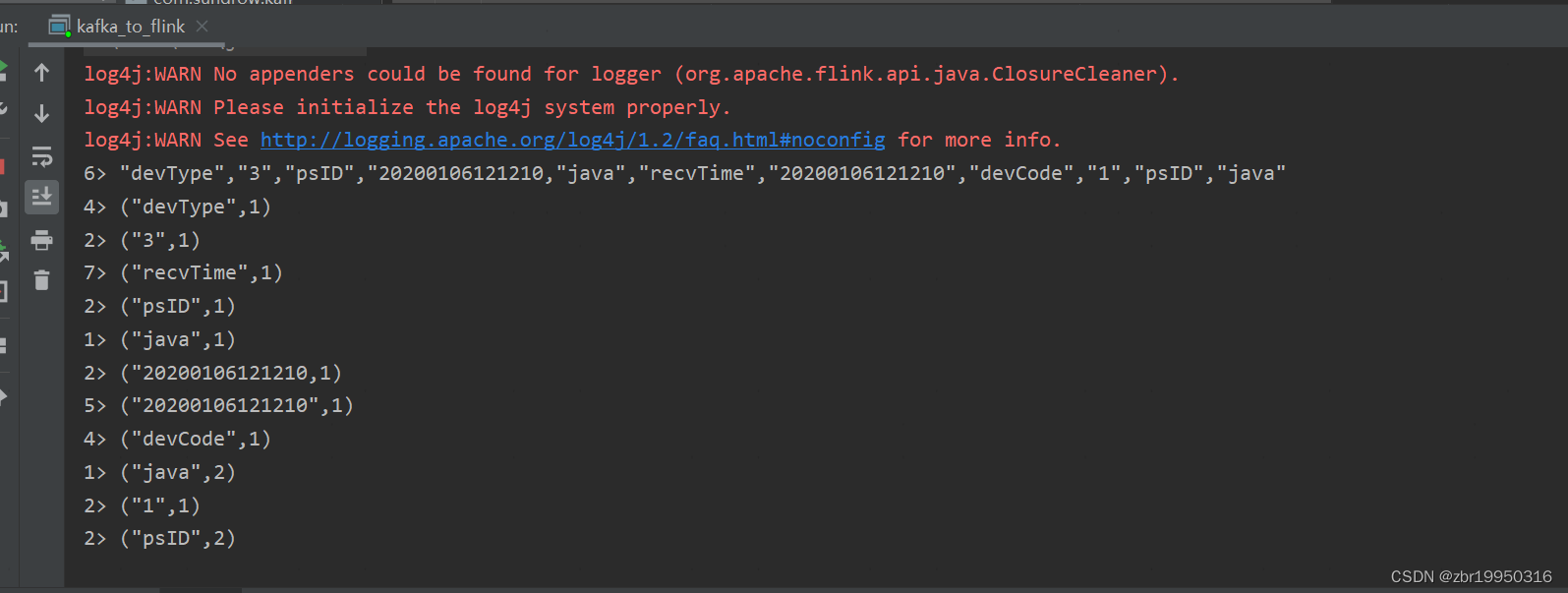
把这条数据在写到Redis缓存数据库
首先把这条数据存到某个路径,读取他的绝对路径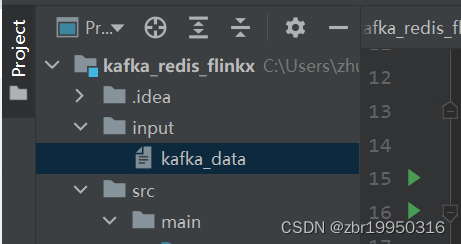
写入redis的整体代码如下
package com.sungrow.kafka_redis_flinkx;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import org.apache.kafka.common.protocol.types.Field;
import java.awt.*;
public class flink_to_redis {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从Flink环境中获取数据
String path=("C:\\Users\\zhubenrui\\IdeaProjects\\kafka_redis_flinkx\\input\\kafka_data");
DataStreamSource<String> inputStream = env.readTextFile(path);
//实例化Flink和Redis关联类FlinkJedisPoolConfig,设置Redis端口
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder()
.setHost("10.0.81.153")
.setPort(6379)
.setDatabase(5)//分区5
.setPassword("sungrow2011")
.build();
//写入Redis
inputStream.addSink(new RedisSink<>(conf,new MyRedisMapper()));
env.execute();
}
//自定义实现RedisMapper接口
public static class MyRedisMapper implements RedisMapper{
@Override
//返回当前Redis操作命令的描述
public RedisCommandDescription getCommandDescription() {
//把所有信息都保存在一张hash表里
return new RedisCommandDescription(RedisCommand.SET);
}
@Override
public String getKeyFromData(Object o) {
// System.out.println("aaaaaaaaaaaaaaaa" + o);
return "11111";
}
@Override
public String getValueFromData(Object o) {
// System.out.println("bbbbbb" + o);
return (String) o;
}
}
}
运行后如下
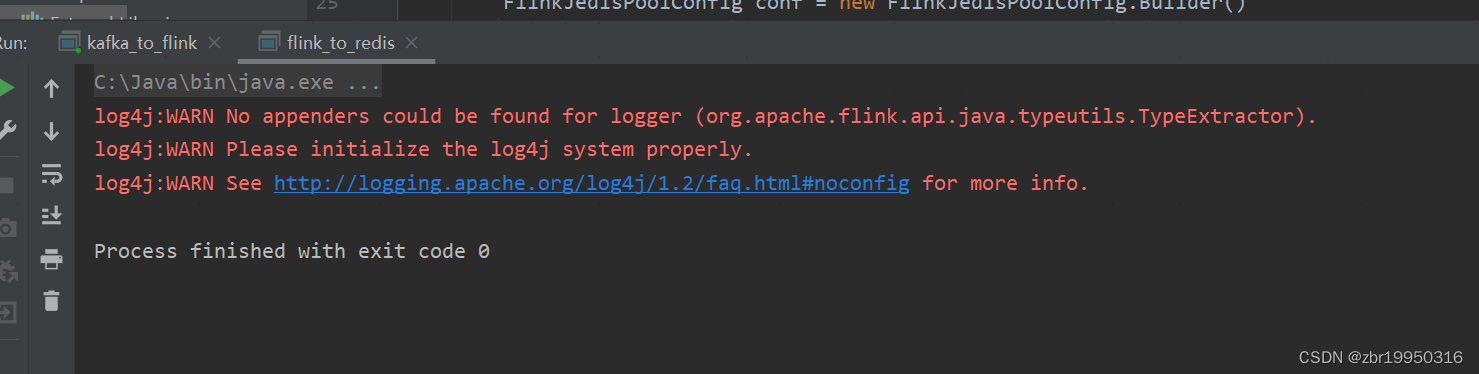
为了证明其成功写入,加个测试代码
System.out.println("aaaaaaaaaaaaaaaa" + o);
System.out.println("bbbbbb" + o);
重新运行如下图,前面的aaaaaaaa和bbbbbb相当于key,剩余的相当于value
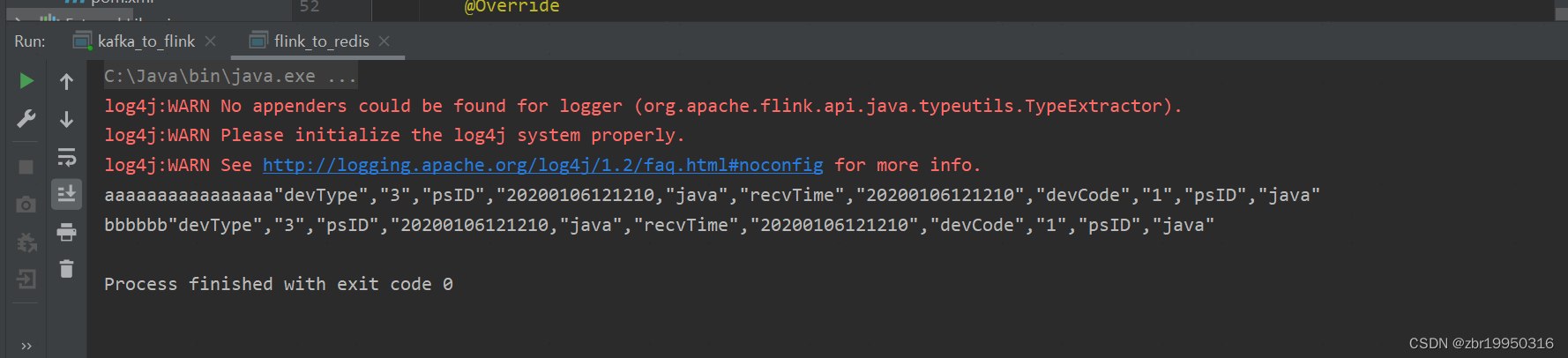
代表写入到redis成功
开启redis集群
进入redis,在src目录下,输入命令redis-cli -h 10.0.81.155 -p 6379 -a sungrow2011
-h代表主机ip,默认127.0.0.1
-p代表默认端口
-a表示密码
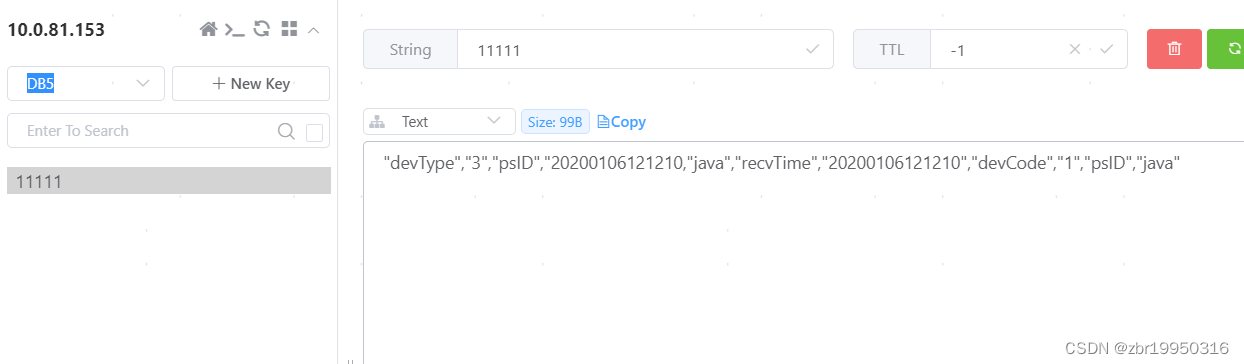
进入命令redis命令窗口,选择第五个分区,然后查看

通过get 查看11111里面的数据

启动redis可视化工具Another Redis Desktop Manager也可以查看
总结
从kafka到redis的wordcount,基本都是从kafka拿数据,基于环境(目前都是基于yarn去提交任务),用yarn去提交一下,或者说自己写一个shell脚本,直接执行脚本就提上去了。Redis主要是常用的一些基本命令要会,基本结构,string,set,目前我们这边一个string格式,一个hash结构,直接继承redis的jar包,把数据采进去,把kafka到redis的流程就搞通了,flink提交到yarn的任务搞通了,也可以flink自己的standalong去玩,可以什么都不搞,本地去跑。

这一坨是一个设备,是一个Hkey,后面以此类推。
以这个摇信为例,统计pskey的wordcount会不会统计,比如PSID:100004:1-1-1-1。。。-1,共十个,1-1-1-2...-1,共20个,我就造简单的,比如PSK,这是一个属性,自己造,“1-1-1-1”,以此类推。
到redis的意思是,上面说的10,20的结果,存到redis,我如果让你存一个Hash结构会不会存,redis的常用数据结构你知不知道,我的目的是存hash结构,什么叫hash结构,以一个人为例,Person为例,比如有一个ID,看身份证也行,有n多属性,这n多属性怎么存。一个field,一个value,field,比如说name,张三,age,20.
field value
name 张三
age 20
让你存list会不会存,前提是要会list的常用结构,redis什么集合都有key-value结构,最后统一交到yarn上去跑,这个写完以后,有两种玩法,第一种直接去写redis,第二种又可以回到flinkX,去看看kafka到flinkx怎么写,kafka到redis通过flinkx怎么去配,如果是第二种方式,结果应该往哪写,上面的wordcount计算结果往哪写,要到kafka,所以这个链路是kafka-->flink-->kafka-->flinkx的配置-->redis。这样就把flinkx到redis的配置就玩了一遍。二楼开发环境都有对应样例。
目前没让我去查mysql什么的,目的就是把整个流程跑通,基本的用法
DBeaver这个redis工具让我们可视化的去看结果,也可以可视化的去赛数据,也可以命令行去查都是一样的,最后的目的,不管我是手动版,还是自己搞一个程序,要造数据,到kafka,造什么样的数据我自己决定,json格式有哪些属性我自己决定,完了以后就是flink逻辑处理,完了以后两种方式,只写redis,要看这边怎么去整合redis,怎么调redis的jar包,两种方式,一种是flink提供了一个flink到redis的connect连接器,去仓库搜,就是一个依赖,或者直接用redis的编程jar包,直接搜redis就能搜到,直接百度一下,这是第一种方式,最基本的。第二种方式是先搞第一种方式到kafka,然后通过 flinkx的配置再到redis,去yarn提交任务。
yarn提交要连接xshell,在新集群,flinkx到hbase在老集群,flink提交任务往上一坨,shell脚本,写个最简单的,先手动bin/flink/-c等这一坨写一个helloworld的shell脚本,只要sh.xxx sh就提交上去了,能不能搞定。















 1876
1876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









