







前言
我们知道“二八”法则阐明了生活中20% 的人掌握这世上 80% 的财富,而 80% 的人只掌握世上 20% 的财富。这里说明财富的划分并不是均衡的。生活中,工作中这样的场景也很多,“忙的忙死,闲的闲死”。生搬硬套硬套点概括就是数据倾斜。而这个名词在数据开发领域可以说是老生常谈的话题,这里就这个话题给大家一些自己对处理这种顽疾的一些经验之谈。
一、什么是数据倾斜
在大数据环境中,使用分布式计算引擎(hive, spark, flink)在进行数据处理时, 在某个(stage)阶段中的某个task运行的数据量/时长的结果远超该stage内task的平均运行的数据量/时长的(N倍)时, 认定为数据倾斜, 其本质是数据分布不均衡, 常常伴随着内存溢出和报错。
1.1 发生阶段
1.1.1 Map端倾斜(较少):
常见于文件不可切分, 或者小文件过多, MapJoin产生笛卡尔积倾斜等情况, 导致多个Map间的数据不均。
1.1.2 Reduce端倾斜(重点):
对应spark宽依赖, 按key进行shuffle, 若存在倾斜key, 则会导致多个Reduce间数据不均。
1.1.3 产生shuffle算子:
各类join(含where in, existis, except), gruopby, distinct, union,开窗(partitionby), distributeby, hint(repartition)
二、如何定位数据倾斜
2.1 定位倾斜任务
平台功能化:
解析spark历史服务器日志/yarn日志, 过滤某个task运行的数据量/时长超过该stage的其他task平均5倍以上的任务(这个5倍是参考spark aqe 的自动倾斜处理的阈值), 进行批量拉取。
个人经验:
集群运行时长Top任务或数据量不大但跑的异常慢, 利用SparkWebUI进行单个分析, 看shuffle阶段的Stage的task是否倾斜。(这个主要还是要通过日志和Spark web UI 去定位)
2.2 定位倾斜sql逻辑
SparkWebUI中,通过Stage页面用task运行数据量/时长确定倾斜, 再用SQL页面用倾斜的stageID找对应的sql块。最后还可以用count对应的shuffle字段枚举值,倒叙排序进行查看进行验证。
关于 SparkWebUI 后续可以用单独的一个篇章来讲解,毕竟定位问题比处理问题更重要。
三、数据倾斜的处理方式
分布式计算引擎的数据倾斜大致都是在shuffle 阶段发生,总共分为两大类:聚合阶段的倾斜与join 类的倾斜。下面分别介绍并提供处理方式:
3.1 聚合类倾斜
3.1.1 聚合类groupby, distinct, union
一些高版本计算引擎大多都有map端预聚合功能, 且默认开启, 基本不会倾斜。
再早期的处理办法也就是是手动二级聚合: gruop by key+随机数, 再group by key。如下SQL:
二次聚合处理倾斜
select split(rand_col1,'-')[0]
,sum(cnt)
from( select concat(col1, '-', ceil(rand() * 100)) as rand_col1
,count(1) as cnt
from tableA
group by concat(col1, '-', ceil(rand() * 100))
)t1
group by split(rand_col1,'-')[0]
3.1.2 开窗类partitionby
常见的row_number=1这种用来求最值类指标可用替换为聚合函数, 因为在有预聚合功能的前提下就不会倾斜或缓解倾斜。例子如下:
如时间最值: 用户粒度末次交易的产品名称,可以用时间+产品拼接后用聚合函数处理,SQL 如下:
substr(max(concat(trans_tm,prod_nm)), 20)
如数字最值: 用户粒度单笔最大交易金额对应的产品,也是使用上面方式,但是这里增加了统一长度处理
substr(max(concat(substr(concat('00000000000',order_amt),-10),prod_nm)), 11)
倾斜key被partition by,且有order by产生的倾斜
这种基本没法解决, 因为同一个key的排序不能分布式, 是必须进入一个reduce的, 这种操作一定要避免
重分区参数:
distributeby, hint(repartition) ,常用于小文件合并, distribute by倾斜可将倾斜key打散,SQL如下:
distribute by case when 字段 = 倾斜key then ceil(rand() * 50) else 字段 end
repartition(n) 是均分的, 但要注意按文件大小给数字
3.2 Join类倾斜
3.2.1 AQE SkewJoin
介绍:
spark会自动将倾斜分区拆成多个分区进行join, 默认判断是某分区的数据量超过平均分区数据量5倍以上会被spark进行拆分。
若引擎支持, 建议优先使用, 适用性强, 使用方便, 对代码无需改动, hive也有类似参数, 但只支持内连接, 很局限。
适用场景:
spark3.0以上, 大表join/left join小表 or 大表join/left join大表时, 主表侧(比如left join的左表)关联key产生倾斜的情况
失效场景:
1、如果倾斜的分区的大部分数据来自于上游的同一个 Mapper,AQE SkewedJoin 无法处理,原因是 Spark 不支持 Reduce Task 只读取上游 Mapper 的一个 block 的部分数据。
2、如果 Join 的发生倾斜的一侧存在 Agg 或者 Window 这类有指定 requiredChildDistribution 的算子,那么 SkewedJoin 优化无法处理,因为将分区切分会破坏 RDD 的 outputPartitioning,导致不再满足 requiredChildDistribution。
3、对于 Outer/Semi Join,AQE SkewedJoin 是无法处理非 Outer/Semi 侧的数据倾斜。比如,对于 LeftOuter Join,SkewedJoin 无法处理右侧的数据倾斜。
4、AQE 无法处理倾斜的 BroadcastHashJoin。
使用方式:
仅开启一个参数即可: set spark.sql.adaptive.enabled = true; --开启AQE, 默认false, 开启后SkewJoin会默认开启。
3.2.2 走广播, 大表 join / left join 小表
介绍:
MapJoin / BroadcastJoin, 用一个hash结构缓存小表到内存, 由Driver广播到每一个Executor, 在map阶段进行join, 无需shuffle
适用场景:
被广播表是小表, 具体多少算小看集群配置, 建议不要超过128M(是谓词下推+列裁剪后的大小, 2.4.x 源码写死最大8G)
spark2.4源码如下:BroadcastExchangeExec.scala
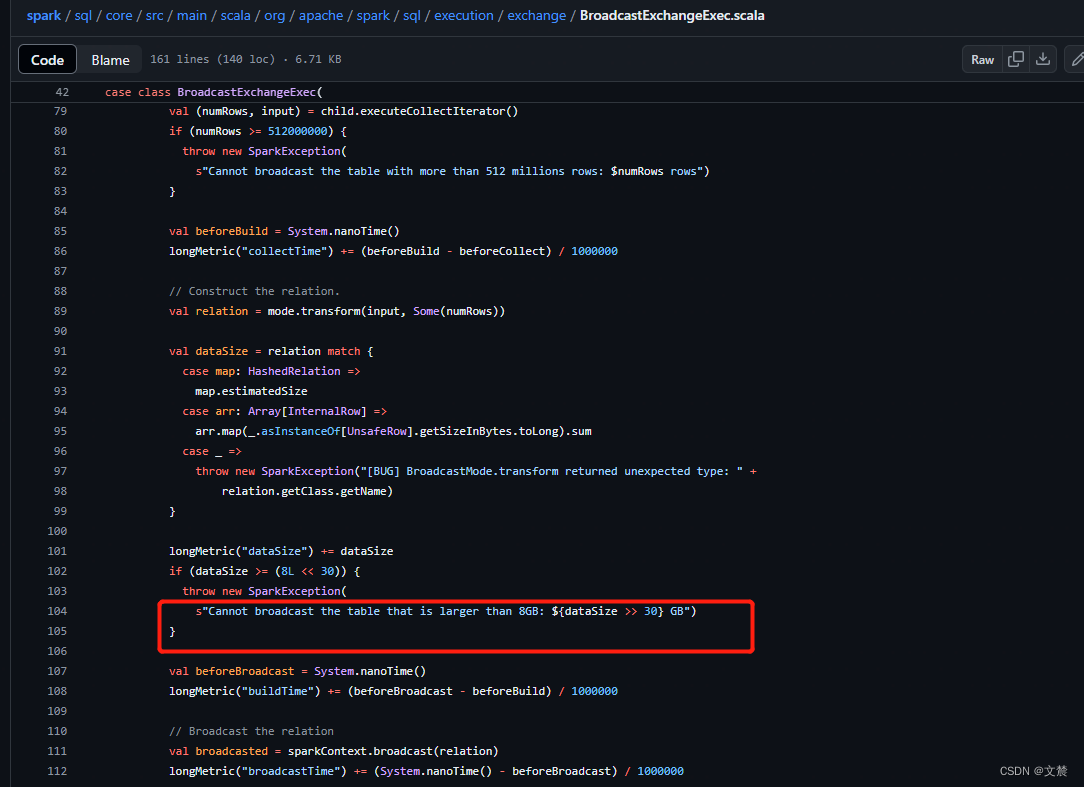
失效场景:
大表join大表; 小表left/full join大表(主表数据需被全部写出, 无法被广播)
使用方式:
1、手动hint指定: select /*+ broadcast(小表别名) */
2、spark参数:
set spark.sql.autoBroadcastJoinThreshold = 100m; 广播小表阈值默认10M, 小于阈值会spark自动广播, -1为禁止广播
set spark.sql.broadcastTimeout = 600s; 广播超时时长, 默认300s, 广播超时会报错, 所以建议同时调大。
参考sql 如下:
广播join 使用方式
set spark.sql.autoBroadcastJoinThreshold = 100m;
set spark.sql.broadcastTimeout = 600s;
select /*+ broadcast(t2) */ *
from tableA t1
left join tableDim t2
on t1.key = t2.key
;
3.3 倾斜场景与对应的处理方式
Join倾斜有两种,异常值倾斜与非异常值倾斜
3.3.1 异常key倾斜
宽表null值倾斜: 做宽表时, 用主表关联维表, 再用维表的字段(大量null)去关联维表, 产生null值倾斜
发生场景:
主表的关联key存在大量null值or默认值, 属于不需要参与关联的异常值, 这种是倾斜出现频率最高
解决方案一:
优先考虑AQE, 和广播。参考上面方式
解决方案二:
维表异常值可以直接过滤, 事实表异常值则将异常值(null)打散再关联
注意:sparksql的join on中不能使用rand()函数, 需要将coalesce(t1.key, rand())落个字段再关联
参考sql 如下:
select * from tableA t1
left join dimA t2
on coalesce(t1.key, rand()) = t2.key
3.3.2 非异常key倾斜
发生场景:
关联维表时, 事实表倾斜: 事实表left join商户维表 on 商户id, 事实表中的商户倾斜
关联维表时, 维表倾斜: 事实表left join用户维表(超大表) on 手机号, 用户维表无手机号默认值为-1, 默认值倾斜
上述的场景中,都是表的关联的某些key数据量特别多, 且不是异常值, 是需要参与关联的热点数据
整体方案优先级顺序:
AQE ==> 广播 ==> 加并行度 ==> 手动case ==> 过滤出小维表 ==> 加盐 ==> 单独处理倾斜再union
解决方案一:
优先考虑AQE, 和广播, 使用方法见上文
弊端:见上文
解决方案二:
加并行度, set spark.sql.shuffle.partitions=200;对于很多key倾斜的情况能缓解,。
案例sql 如下:可以以使用Hint 语法指定并行度,如图:
弊端:对单个key倾斜无效。
解决方案三:
少数倾斜的key当成异常null值不关联, 直接手动case出对应属性
案例sql 如下:
select
*
,case when t1.关联key = 倾斜key then '手动查出维度属性' else t2.正常关联的维度属性 end
from 事实表 t1
left join 维表 t2
on case when t1.关联key = 倾斜key then rand() else t1.关联key end = t2.关联key
弊端:硬编码,若倾斜key较多, 手动case会很麻烦, 且倾斜key的属性变化需要手动修改sql的case。
解决方案四:
想办法过滤出小表再广播。
案例sql 如下:
select /+ broadcast(t2) / --大维表变成小维表, 一般可以走广播
*
from 事实表 as t1
left join(--过滤出大维表中, 事实表实际用到的数据, 将大维表变小, 1G => 100M
select
*
from 维表
where 关联key in(
select 关联key
from 事实表
group by 关联key
)
)t2 on t1.关联key = t2.关联key```
弊端:如果过滤后还是大表就不行了
解决方案五:
加盐关联, 较大表随机数打散, 较小表随机数扩容(实现类似: 25条 join 1条 ===> 5条 join 5条)。(大表与大表关联的处理方案)
案例sql 如下:
select
*
from(--较大表的key打散成5份
select
,concat(key, ceil( rand() 5) ) as key_join
from tableA
)t1
left join(--较小表按key扩大5倍
select
*,concat(t1.key,t2.rand_num) as key_join
from tableB as t1
lateral view explode(array('1','2','3','4','5')) t2 as rand_num --增加统计周期粒度
)t2 on t1.key_join = t2.key_join
弊端:只能够缓解倾斜不能够解决倾斜
解决方案六:
找出倾斜key, 然后在 原sql中过滤, 单独拿出来跑, 最后unionall,倾斜的key单独跑可以走广播, 必然不会倾斜,。
找倾斜key方法:
- 单独跑: count查找倾斜key。
- 使用sample 抽样,(推荐,性能更好),如下代码所示:
pyspark 抽佣倾斜key 展开源码
from pyspark import SparkConf, SparkContext
from collections import Counter
conf = SparkConf().setAppName("SkewedKeySamplingDemo").setMaster("local[*]")
sc = SparkContext(conf=conf)
def parseLine(line):
fields = line.split(',')
return (int(fields[3]), float(fields[2]))
input = sc.textFile("/path/to/data.csv")
mappedInput = input.map(parseLine)
sample = mappedInput.sample(False, 0.1)
sampleCount = sample.countByKey()
for item in Counter(sampleCount).most_common(10): # 显示出现频率最高的10个key
print(item)
案例sql 如下:
select /+ broadcast(t2) /
*
from(
select*
from 事实表
where 关联key = 倾斜key
)t1
left join 维表 t2 on t1.关联key = t2.关联key and t2.关联key = 倾斜key
union all
select
*
from(
select*
from 事实表
where 关联key <> 倾斜key
)t1
left join 维表 t2 on t1.关联key = t2.key
弊端:该方案代码改动较大, 且倾斜key如果很多就不好处理















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









