







本博文的主要内容包括:
- Spark性能真正的杀手
- 数据倾斜多么痛
1、关于性能调优首先谈数据倾斜,为什么?
(1)因为如果数据倾斜,其他所有的调优都是笑话,因为数据倾斜主要导致程序跑步起来或者运行状态不可用。
(2)数据倾斜最能代表spark水平的地方,spark是分布式的,如果理解数据倾斜说明你对spark运行机制了如指掌。
2、数据倾斜两大直接致命性的后果:
(1)、OOM,一般OOM都是由于数据倾斜所致!
(2)、速度变慢、特别慢、非常慢、极端的慢、不可接受的慢!
何为数据倾斜如下图所示:
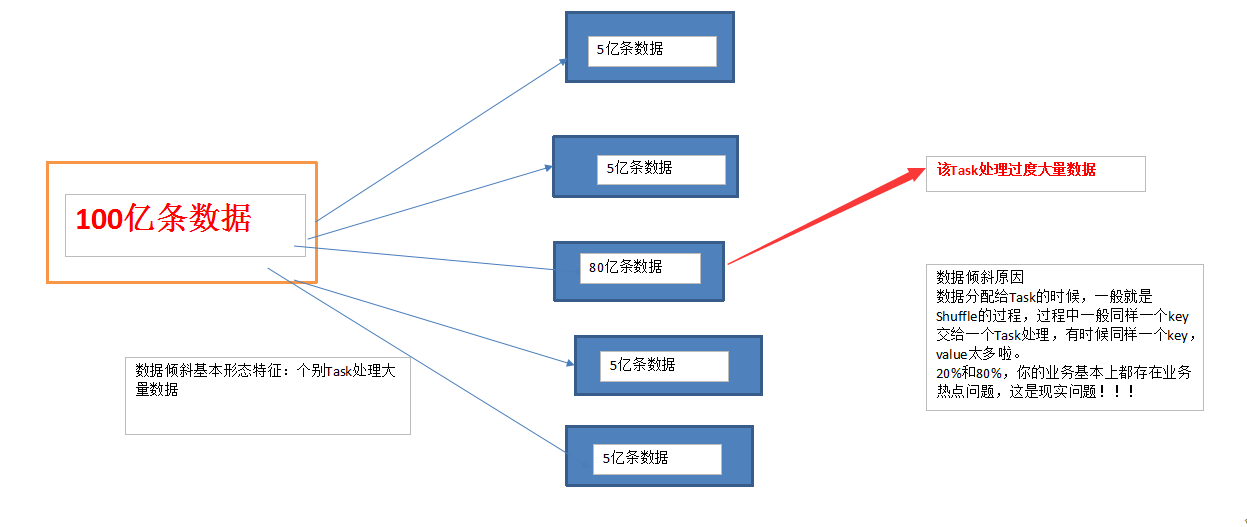
3、性能调优最好的方法。
数据倾斜解决掉之后最好的方法就是加内存和CPU 。
4、数据倾斜的定位:
(1)Web UI,可以清晰看见哪些个Task运行的数据量大小;
(2)Log,Log的一个好处是可以清晰的告诉是哪一行出现问题OOM,同时可以清晰的看到在具体哪个Stage出现了数据倾斜(数据倾斜一般是在Shuffle过程中产生的),从而定位具体Shuffle的代码;也有可能发现绝大多数Task非常快,但是个别Task非常慢;
(3)代码走读,重点看join、groupByKey、reduceByKey等关键代码;
(4)对数据特征分布进行分析;















 2318
2318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









