







1.1.1 数据描述
此处使用朴素的贝叶斯对20Newsgroup文本数据进行分类,20Newsgroup是路透社的新闻预料库,其包括了近20000篇新闻文档,被划分为20类。在文本挖掘和机器学习领域,常常使用20Newsgroup作为文本分类和文本聚类的标准测试预料库。下面将介绍
如何使用Mahout的朴素贝叶斯模型训练一个分类模型,并使用这个分类模型对测试数据进行分类。
1.1.2 20Newsgroup预处理(此处bug已修复,MAHOUT-3)
在使用贝叶斯对文本进行分类时需要将每篇文档合并到一个大的文件中,在合并后的文件中每一行代表一片文章。执行预处理时需要调用PrepareTwentyNewsgroups类中的main方法,该类在mahout-examples-0.6.jar包中,执行的命令行如下
$MAHOUT0P6_HOME/bin/mahoutprepare20newsgroups –p 20_newsgroups -o 20news-train -a org.apache.lucene.analysis.standard.StandardAnalyzer-c UTF-8
执行上述命令后形成了20个大的文件,每个文件中的一行代表一篇文档,每行的第一个字符串代表了该文档所属类别,类别后面是空格,然后是文档的内容,格式示意图如下
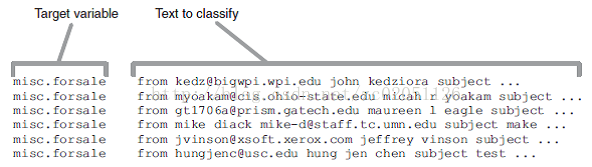
图1.2.1 经过预处理后的文件格式
bug修复记录:见6.2.1
1.1.3 训练贝叶斯模型
这里用到的命令行方法为trainclassifier,对应的实现在mahout-example-0.6-job.jar中,org.apache.mahout.classifier.bayes.TrainClassifier
将1.1.2中经过预处理后的文件20news-train拷贝到HDFS文件系统,执行如下命令
$HADOOP_HOME/bin/hadoopfs -put <Path to 20news-train>/20news-train 20new-train
然后执行如下命令训练模型
$MAHOUT0P6_HOME/bin/mahouttrainclassifier -i 20news-train -o newsmodel -type bayes -ng 1 -source hdfs
训练完成后会生成贝叶斯分类模型,名称为newsmodel,其中包括的信息可以参考本部分的1.7节。
1.1.4 测试贝叶斯模型(-method sequential参数有bug,未修复,MAHOUT-4)
这里用到的命令行方法为testclassifier,对应的实现在mahout-example-0.6-job.jar中,org.apache.mahout.classifier.bayes.TestClassifier
为了检测训练的模型准确性如何,需要用测试数据进行测试,为了方便简单,这里直接将训练数据当成测试数据,执行的命令行如下
$MAHOUT0P6_HOME/bin/mahouttestclassifier -d 20news-train -m newsmodel -type bayes -ng 1 -source hdfs-method mapreduce
运行完成后输出的模糊矩阵(ConfusionMatrix)如下
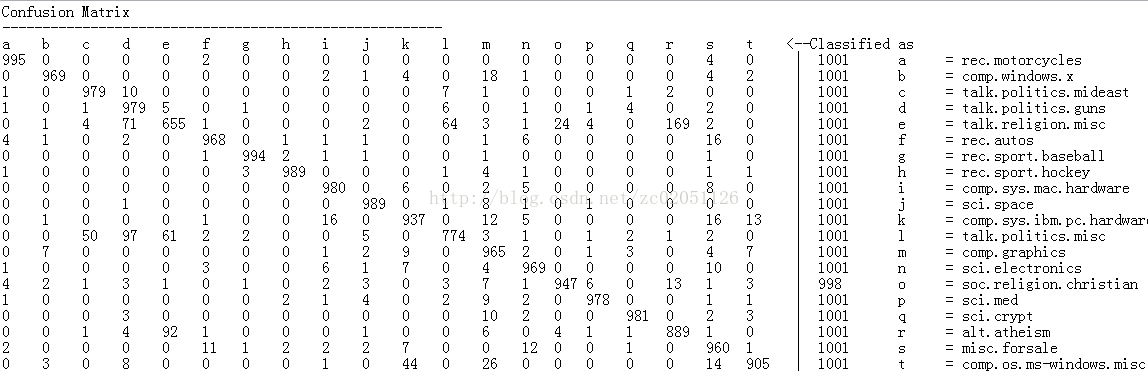
图1.1.4-1 测试数据集生成的模糊矩阵















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









