







 本文深入探讨Hadoop 1.0的局限性,包括抽象层次低、资源浪费及实时性差等问题,并详细介绍Hadoop 2.0的改进措施,如HDFSHA、HDFS联邦及YARN等,旨在提升资源管理和数据处理效率。
本文深入探讨Hadoop 1.0的局限性,包括抽象层次低、资源浪费及实时性差等问题,并详细介绍Hadoop 2.0的改进措施,如HDFSHA、HDFS联邦及YARN等,旨在提升资源管理和数据处理效率。
Hadoop的优化与发展
1. Hadoop(1.0)的局限与不足
- 抽象层次低。需要手工编写代码来完成,有时只是为了实现一个简单的功能,也要手工编写大量的代码。
- 表达能力有限。Hadoop把复杂的分布式编程高度抽象到两个函数Map和Reduce上,在降低使用难度的同时,但也带来了表达能有限的问题,实际操作的时候有些问题并不能单单靠这两个函数来解决问题。
- 开发者自己管理作业之间的依赖关系。一个作业Job只包含Map和Reduce两个阶段,通常的实际应用问题需要大量的作业协调才能顺利解决,这些作业之间往往存在着复杂的依赖关系,但是MapReduce框架本身并没有提供相关的机制来对这些依赖关系进行有效的管理,只能开发者自己管理。
- 难以看到程序的整体逻辑。用户处理的逻辑都隐藏在代码的细节当中,没有更高层次的抽象机制对程序整体逻辑进行设计,这就给代码理解和后期的维护带来了障碍。
- 执行迭代操作效率低。对于一些大型的机器学习,数据挖掘任务,往往需要更多轮次迭代才能得到结果。采用MapReduce实现这些算法的时候,每次迭代都是执行一次Map,Reduce任务的过程,这个过程的数据来源于分布式文件系统HDFS中,本此的迭代处理的结果也放在HDFS中,继续用于下一次的迭代。反复读写HDFS中的数据,大大降低了迭代操作的效率。
- 资源浪费。在MapReduce的框架设计中,Reduce任务必须等待所有的Map任务执行完毕后再开始执行,造成不必要资源的浪费。
- 实时性差。只是适用于离线批数据处理,无法支持交互式数据处理,实时数据的处理。
2. 针对其1.0版本的不足改进和提升
2.1 Hadoop框架自身的改进和提升
| 组件 | Hadoop1.0的问题 | Hadoop2.0的改进 |
|---|---|---|
| HDFS | 1.单一名称节点,存在单点失效的问题。 2.单一命名空间,无法实现资源隔离。 | 1.设计了HDFS HA,提供名称节点的热备份机制。 2.设计了HDFS联邦,管理多个命名空间 |
| MapReduce | 资源管理效率低 | 设计了新的资源管理框架YARN |
2.2 Hadoop生态系统的完善
| 组件 | 功能 | 解决Hadoop中存在的问题 |
|---|---|---|
| Pig | 处理大规模数据的脚本语言,用户只需要编写几条简单的语句,系统就会自动转换为MapReduce作业 | 抽象层次低,需要手工编写大量的代码 |
| Oozie | 工作流和协作服务引擎,协调Hadoop上运行的不同任务 | 没有提供作业依赖关系管理机制,需要用户自己处理作业之间的依赖关系 |
| Tez | 支持DAG作业的计算框架,对作业的操作进行重新分解和组合,形成一个大的DAG作业,减少不必要的操作 | 不同的MapReduce任务之间存在重复操作,降低了效率 |
| kafka | 分布式发布订阅消息系统,我的另一篇博文中有介绍 | Hadoop生态系统中各个组件和其他产品之间缺乏统一的,高效的数据交换中介 |
3. HDFS2.0
3.1 HDFS HA
对于分布式文件系统HDFS而言,名称节点(NameNode)是系统的核心节点,因为它存储了各类元数据的信息,并负责管理文件系统的命名空间和客户端对文件的访问。但是在HDFS1.0当中,只存在一个单一的名称节点,一旦这个名称节点宕掉那么整个HDFS就会崩掉,虽然存在第二名称节点(SecondNode),但其的主要作用是合并FsImage和EditLog文件,减少名称节点的压力和加快HDFS启动的时间,并不可以作为名称节点的备份节点,因为在其从名称节点拉回FsImage和EditLog进行合并的时候,HDFS新的对文件的操作其并不能进行记录, 故不能作为名称节点的实时备份切换节点。(详细了解名称节点和第二名称节点的工作原理我的这篇博文)
为了解决上述所存在的,第二名称节点无法提供“热备份”的功能,即在名称节点发生故障的时候,系统无法实时的切换到第二名称节点立即对外提供服务,存在单点故障的问题。设计出了HA(High Availability)架构。
3.1.1 架构简介
在一个典型的HA集群当中,一般设置两个名称节点,其中一个处于“活跃”状态,另一个处于“待命”状态。处于活跃状态的名称节点负责对外处理所有客户端的请求,而处于待命状态的名称节点则作为备用节点,保存足够多的元数据信息,当名称节点出现故障的时候提供快速回复的能力。一旦活跃的名称节点出现故障,就可以立即切换到待命的名称节点,不会影响到系统的正常的对外服务。
3.1.2 详细解析HA架构如何工作
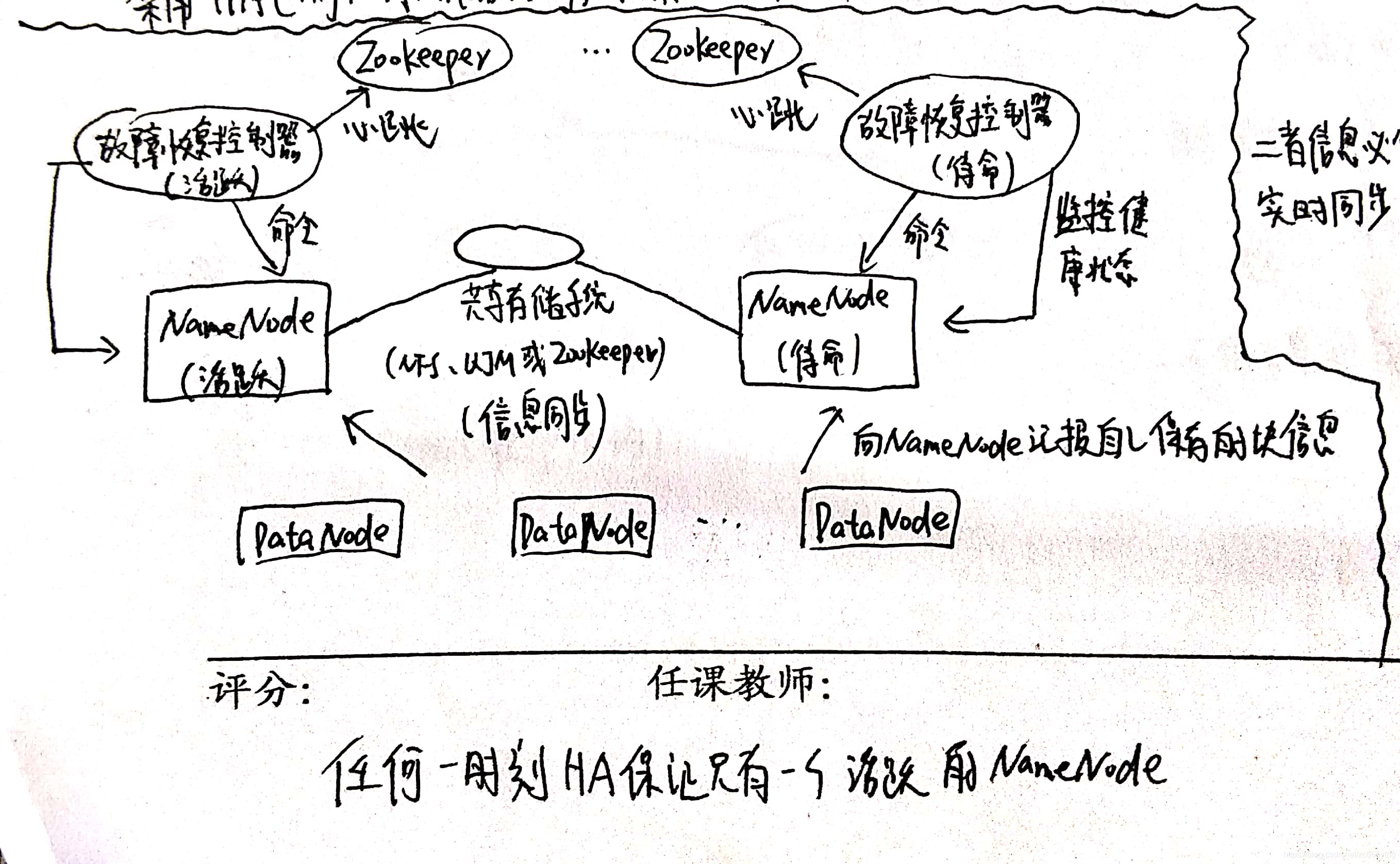
如上图是我画的HDFS HA的架构图。
- 由于待命的名称节点在活跃的名称节点出现故障的时候是可以实时立即切换对外提供服务的,所以二者的状态信息必须实时的同步,包括写操作的信息,数据存储等等的元数据信息。
- 实现这些通过一个共享的存储系统(Zookeeper) 来实现。活跃的名称节点将跟新数据写入共享存储系统当中,待命的名称节点会一直监听该系统,一旦发现有新的写入,就立即从公共存储系统中读取这些数据并加载到自己的内存当中,从而保证和活跃名称节点同步。
- 对于名称节点中保存的数据块到实际存储位置的映射信息,即每个数据块是由哪个数据节点所存储的。当一个数据节点加入到HDFS集群的时候,它会把自己所包含的数据块列表报告给名称节点,此后通过“心跳”的方式定期执行这个操作,以确保名称节点的块映射是最新的。因此,为了做到这一点,需要给数据节点配置两个名称节点的地址,并把块的信息和心跳信息同时发送给这两个名称节点。
- Zookeeper保证任意时刻只有唯一一个名称节点对外提供服务。
- 当然所有的数据都是保存在本地的Linux系统当中的。
3.2 HDFS 联邦
3.2.1 HDFS1.0当中存在的问题
- 在1.0的版本当中,是只有一个单一的名称节点的,其内存中包含了整个HDFS系统中的元数据信息,不可以进行水平扩展。
- 单个的名称节点的内存空间是有限的,这就限制了系统中的数据块,文件和目录的数目。
- 整个HDFS的系统吞吐量会受限制于单个名称节点的吞吐量。
- 隔离性方面,单个名称节点无法提供不同程序之间的隔离性,一个程序的运行很可能会影响其它程序的运行。
- HDFS HA虽然提供了两个名称节点,但是实际上正则在对外提供服务的任然是一个名称节点,之解决了单点故障的问题。
3.2.2 HDFS联邦的设计
- 在HDFS联邦中,设计了多个相互独立的名称节点,使得HDFS的命名服务可以很好的水平扩展,这些名称节点分别自己管理各自的命名空间和块的管理,相互之间是联邦关系,不需要彼此之间进行协调。
- HDFS联邦有很好的向后兼容性,可以无缝地支持单名称节点架构中的配置。所以,针对单名称节点的部署配置,不需要做任何的修改。
- 我理解认为,这些相互独立的名称节点,每个每个名称节点都用着HA 的架构,整个联邦是多个HA集群的并联。
- HDFS联邦中的名称节点提供了命名空间和管理功能。在HDFS联邦中,所有的名称节点会共享底层的数据节点存储资源,每个数据节点要向集群中所有的数据节点注册,并周期性地向名称节点发送“心跳”和块的信息,报告自己的状态,并处理来自名称节点的命令。
- 在HDFS联邦中,有多个独立的命名空间,其中,每个命名空间管理属于自己的一组块,这些属于同一个命名空间的块构成一个“块池”。每个数据节点会为多个块池提供块的存储。
- 数据节点是物理概念,块池属于逻辑概念,一个块池是一组块的逻辑集合,块池中的各个快实际上是存储在各个不同的数据节点当中的。因此,HDFS联邦中的一个名称节点失效,也不会影响到与它相关的数据节点继续为其他名称节点提供服务。
3.2.3 HDFS联邦的访问方式
使用客户端挂载表的方式进行数据共享的访问。
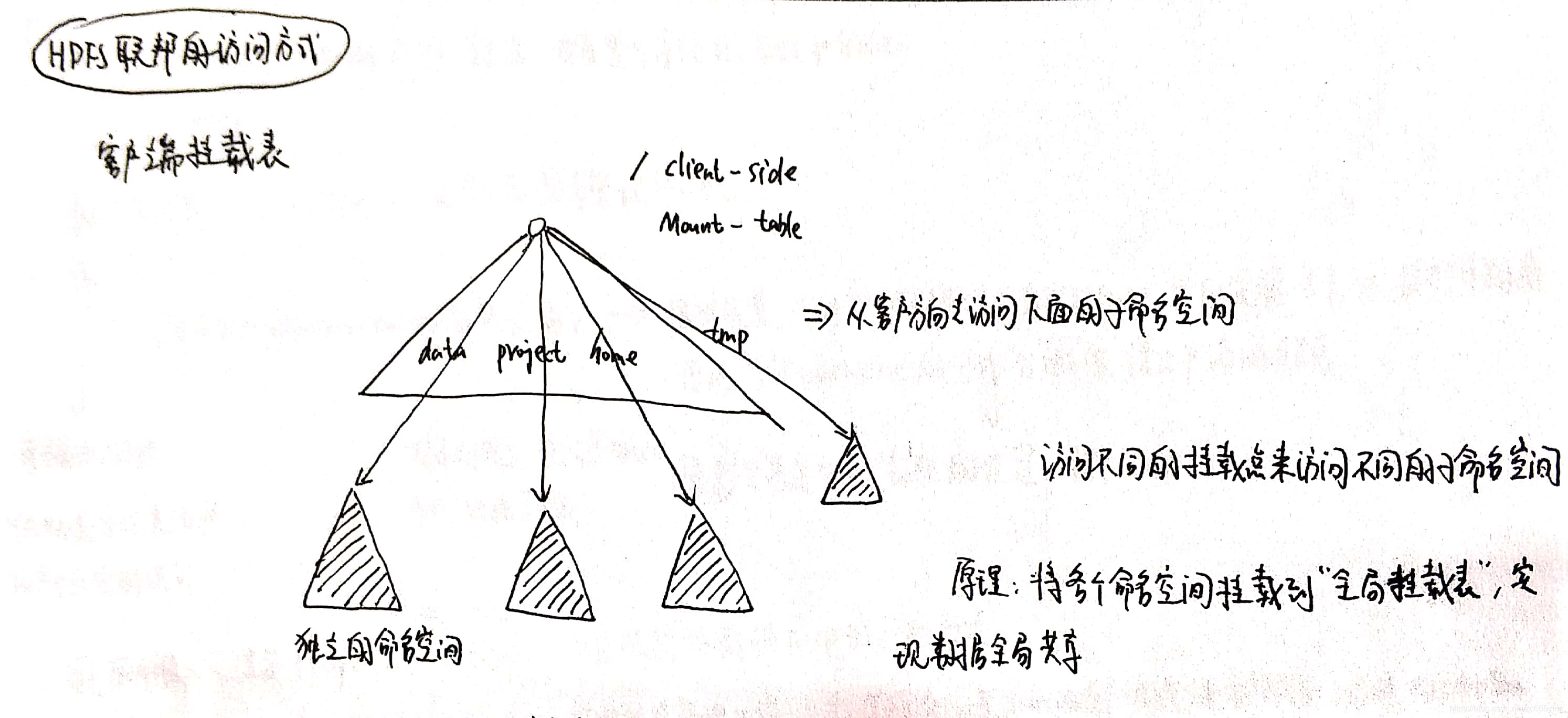
- 一个阴影三角便代表一个独立的命名空间,上方的空白三角形表示从客户端方向于访问下面的子命名空间。
- 客户端可以访问不同的挂载点来访问不同的子命名空间。
- HDFS联邦中命名空间管理的基本原理:把各个命名空间挂载到全局“挂载表”中,实现全局的数据共享,同样的,命名空间挂载到个人的挂载表当中,就成为了应用程序可见的命名空间。

















 9000
9000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









