







1 Redis集群
1.1 什么叫集群(理解)
多台服务器集中在一起,实现同一业务
1.2 为什么集群
一台服务器不够,需要多台服务器支持,解决高并发,集群往往伴随分布式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5EJdMDER-1576858322042)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20191220092111148.png)]
2 分布式
2.1 什么是分布式 (理解)–springcloud(微服务)
分布式: 把整体业务拆分开,分别放到不同的服务
2.2 为什么要分布式
分布式和集群一起使用
便于维护
解决高并发 ,单点故障问题
便于扩容
3 Redis集群
为什么需要集群:
(1)解决单点故障
(2)处理高并发
(3)处理大数据(高并发) --解决存储问题
集群方案的选择:
(1)主从复制 (读写分离 主从同步)
优点:
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
缺点:
Redis不具备自动容错和恢复功能,如果想具备自动重起 ,需要安装插件
(2)哨兵模式
自动化的系统监控和故障恢复功能
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k7K990Dm-1576858337329)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\image-20191220101826403.png)]
优点缺点:
主从复制优点都在, 通过哨兵自动恢复
缺点:比较难扩容,服务占用空间比较多
(3)Redis-Cluster集群
redis的分布式存储,也就是说每台redis节点上存储不同的内容。
优点:
上面有都有,解决分布式存储问题 ,容错问题
4 搭建redis-cluster(了解)
(1) 拷贝6个redis 分别命名为 6379-6384
(2) 修改配置
port 6379
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
appendonly yes
(3) 每个redis服务 写一个startup.bat启动文件
title redis-6379
redis-server.exe redis.windows.conf
(4)安装ruby环境
傻瓜式安装
(5)安装Redis的Ruby驱动 rubygems-3.0.6
a)解压
b)D:\Program Files\Redis_cluster\rubygems-2.7.7 然后命令行执行 ruby setup.rb
(6)通过驱动安装的redis
a)进入6379的目录
b)执行gem install redis
(7) 启动 6379-6384服务
创建集群测试
拷贝redis-trib.rb到6379的redis节点
redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
使用Redis客户端Redis-cli.exe来查看数据记录数,以及集群相关信息
命令 redis-cli –c –h ”地址” –p “端口号” ; c 表示集群
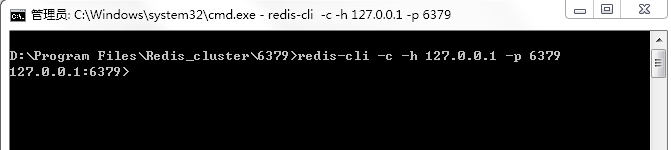
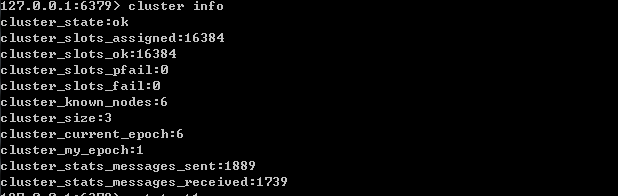
1)查看集群的信息,命令:cluster info
2)命令: info replication
主:

从:

3)查看各个节点分配slot,命令 cluster nodes

4)存值测试

Jedis代码测试
@Test
public void testCluster() throws IOException, InterruptedException {
Set nodes = new HashSet<>();
nodes.add(new HostAndPort(“127.0.0.1”, 6379));
nodes.add(new HostAndPort(“127.0.0.1”, 6380));
nodes.add(new HostAndPort(“127.0.0.1”, 6381));
nodes.add(new HostAndPort(“127.0.0.1”, 6382));
nodes.add(new HostAndPort(“127.0.0.1”, 6383));
nodes.add(new HostAndPort(“127.0.0.1”, 6384));
JedisCluster cluster = new JedisCluster(nodes);
try {
String res = cluster.get(“name”);
System.out.println(res);
// cluster.quit();
} catch (Exception e) {
e.printStackTrace();
// cluster.quit();
}
}
}
6 ES的(elasticSearch) 是什么
6.1ES的概念和特点
ES是什么?
es (elasticSearch): 全文检索的框架,专门做搜索,支持分布式,集群
es:全文检索的框架 --封装lucene的,支持分布式(集群) --特点
(1)原生Lucene使用的不足,优化Lucene的调用方式
(2)高可用的分布式集群 ,处理PB级别数据
1024KB – 1MB
1024MB – 1GB
1024GB – 1TB
1024TB - 1PB
(3)它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。达到开箱即用的效果
lucene:全文检索 – api的比较麻烦 操作全文检索的最底层技术
核心: 创建索引 搜索索引
6.2 ES的对手
Solr和ES区别:
(1)Solr重量级, 支持很多种类型操作,支持分布式式,它里面有很多功能,但是在实时领域上面,没有es好
(2)Es 轻量级, 支持json的操作格式, 在实时搜索领域里面做的不错,]如果想使用其他的功能,需要额外安装插件
7 ES的使用
ES 分为服务端 和 客户端
(1)ES服务端
解压 -->bin/elasticsearch.bat -->localhost:9200
a)配置内存:
config/jvm.options
-Xmx1g
-Xms1g
b)健康状态:
green(最健康) -->主分片和从分片(存储内容)都完好,集群是100%健康
yellow -->主分片好的,从分片至少缺少一个,集群还是可以使用,
red -->至少一个主分片以及它的全部副本都在缺失中。这意味着你在缺少数据
(2)ES客户端–navicat
restfull风格 —> GET/POST/DELETE/PUT shop/goods/1
GET shop/goods/1 -->查询shop这个库goods表 1这条数据
PUT shop/goods {“name”:“111”}
POST shop/goods {“name”:“111”}
DELETE shop/goods/1
1)postman +head
2)curl–>在firefox安装poster插件
3)Kibana5 -->es















 5382
5382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









